핵심 요약
Anthropic이 기존 모델의 성능을 모든 지표에서 능가하는 Claude Sonnet 4.6을 출시했다. 이 모델은 코딩, 컴퓨터 사용(Computer Use), 장기 문맥 추론 분야에서 비약적인 발전을 이루었으며, 베타 버전으로 100만 토큰 컨텍스트 윈도우를 지원한다. 특히 이전 세대의 최상위 모델인 Opus 4.5에 근접하거나 일부 지표에서는 이를 능가하는 성능을 보여주면서도 기존 Sonnet의 가격 정책을 유지하여 실무 적용성을 극대화했다. 현재 Claude.ai와 API를 통해 즉시 사용 가능하다.
배경
Claude API 사용 경험, LLM 벤치마크 지표에 대한 이해, 에이전트 및 도구 사용(Tool Use) 개념
대상 독자
AI 에이전트 개발자, 엔터프라이즈 소프트웨어 아키텍트, LLM 기반 프로덕션 운영팀
의미 / 영향
이번 출시는 중급 모델이 이전 세대 플래그십 모델의 성능을 추월하는 속도가 가속화되고 있음을 보여준다. 특히 '컴퓨터 사용' 능력의 비약적 향상은 AI가 단순 텍스트 생성을 넘어 실제 OS 환경에서 자율적으로 업무를 수행하는 에이전트 시대로의 전환을 앞당길 것이다.
섹션별 상세
이미지 분석
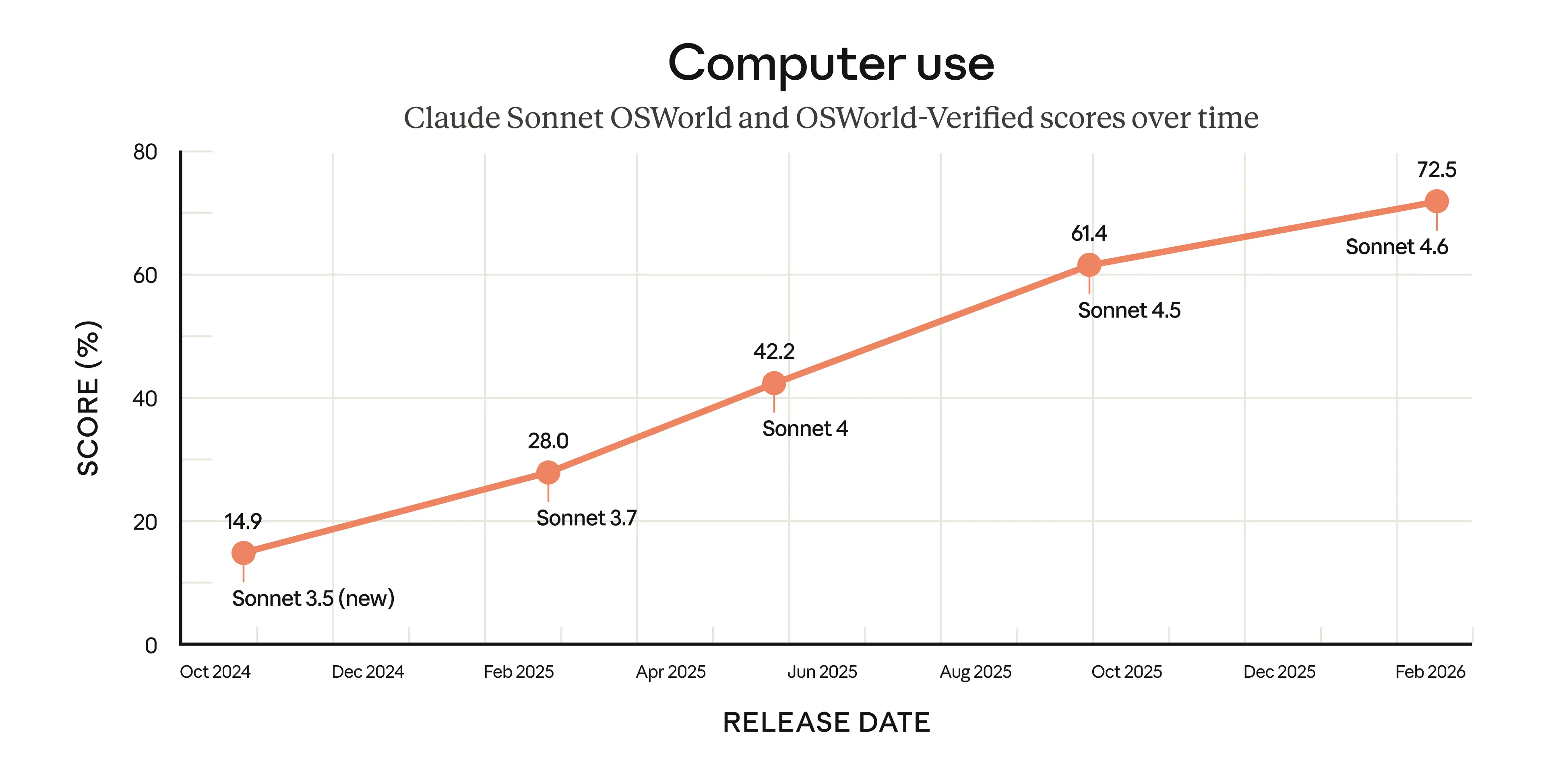
2024년 10월 Sonnet 3.5의 14.9%에서 2026년 2월 Sonnet 4.6의 72.5%까지 컴퓨터 사용 능력이 비약적으로 상승했음을 보여준다. 이는 모델이 인간 수준의 컴퓨터 조작 능력에 빠르게 근접하고 있음을 시각적으로 증명한다.
Claude Sonnet 모델들의 OSWorld 벤치마크 점수 변화를 보여주는 선 그래프
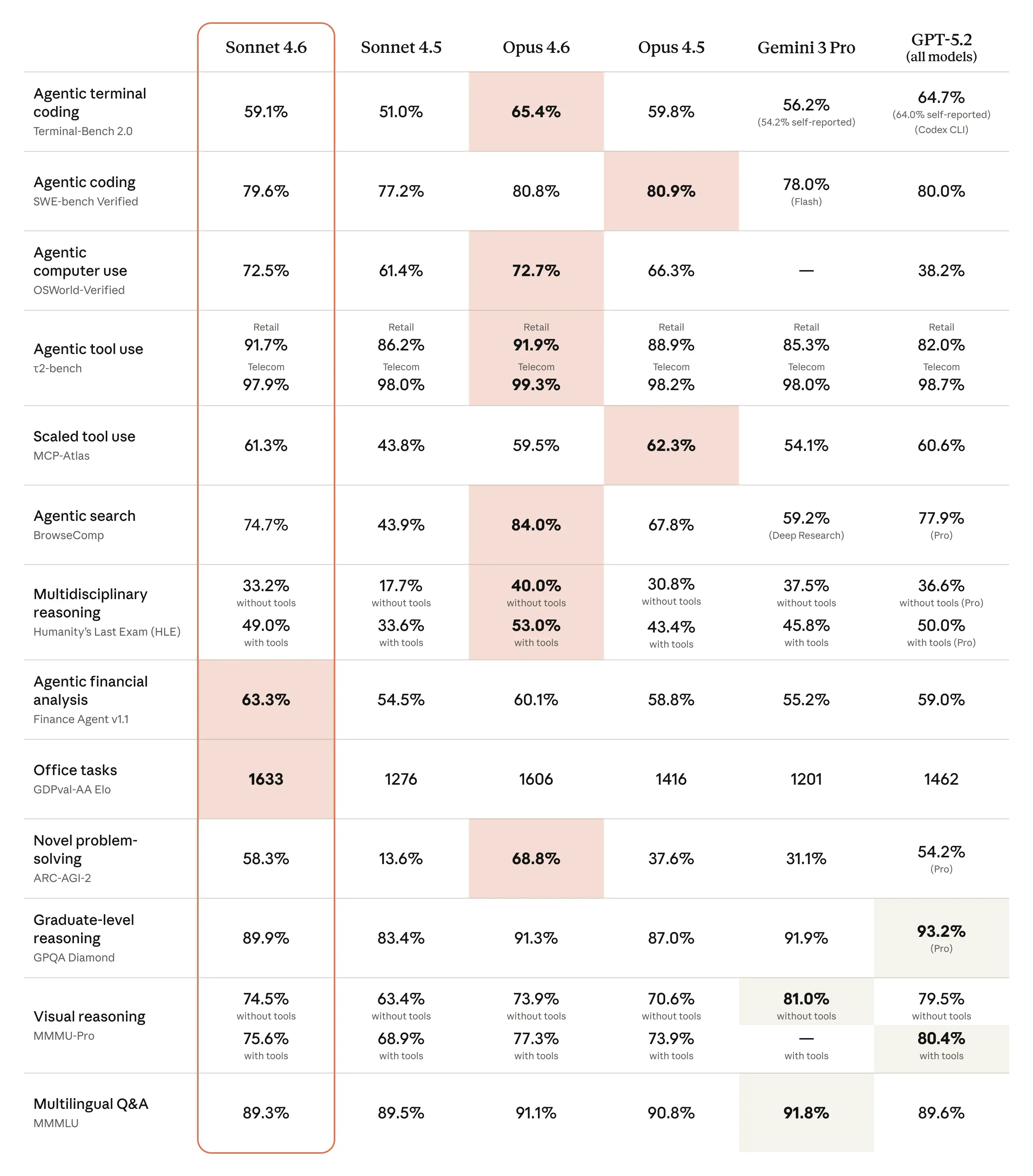
코딩(SWE-bench), 도구 사용, 금융 분석, 추론 등 다양한 지표에서 Sonnet 4.6이 Sonnet 4.5 및 GPT-5.2, Gemini 3 Pro와 비교하여 우위를 점하고 있음을 수치로 제시한다. 특히 오피스 작업과 금융 분석 에이전트 성능에서 두드러진 향상을 확인할 수 있다.
Sonnet 4.6과 타사 최신 모델들의 주요 벤치마크 성능 비교표
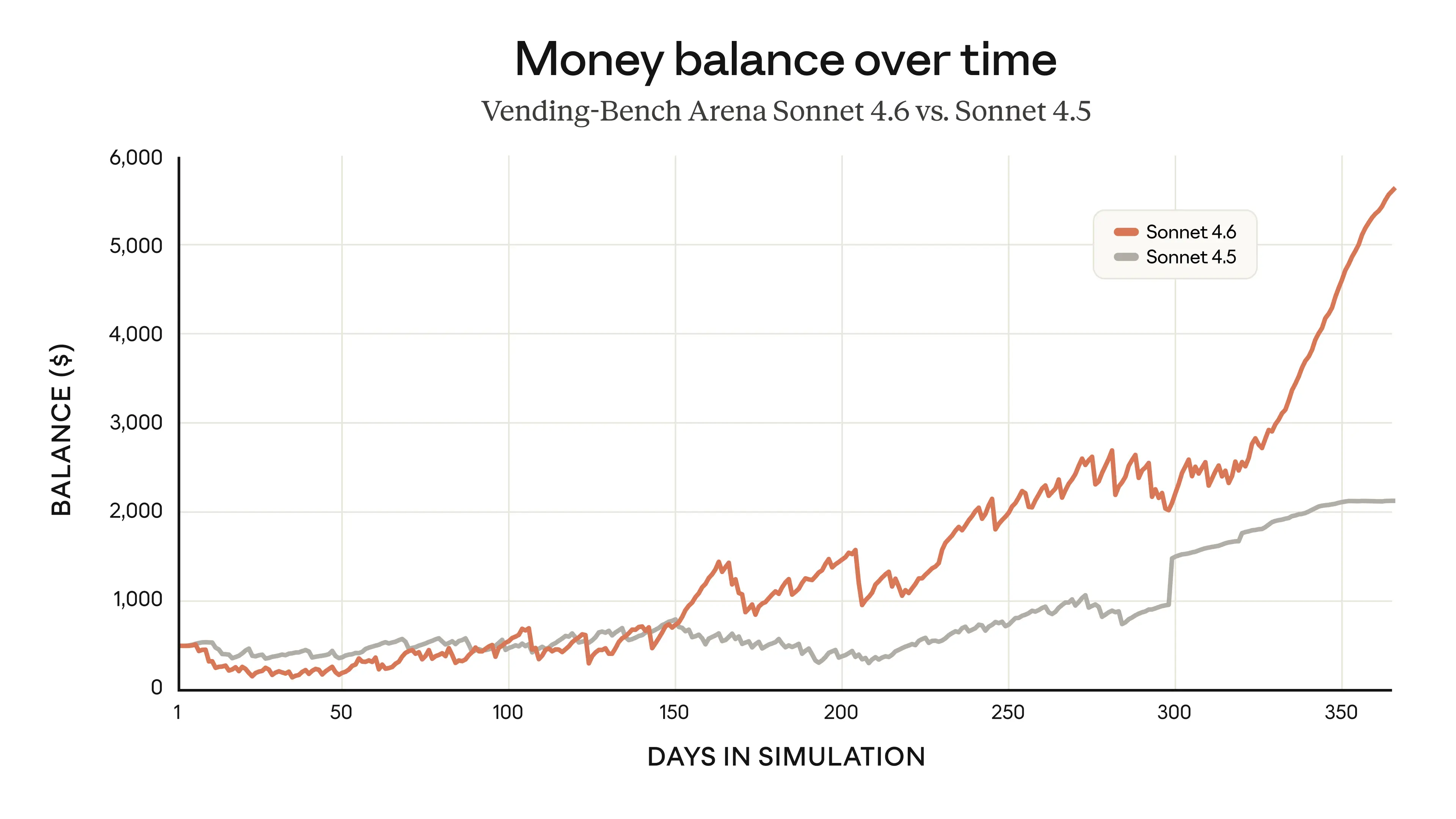
Sonnet 4.6이 Sonnet 4.5보다 훨씬 높은 수익을 창출하는 과정을 보여준다. 특히 초기 투자 단계를 거쳐 후반부에 급격한 성장을 이루는 전략적 추론 능력을 시각화하여 모델의 장기 계획 능력을 입증한다.
Vending-Bench Arena 시뮬레이션에서 Sonnet 4.6과 4.5의 자산 잔액 변화 비교 그래프
실무 Takeaway
- Sonnet 4.6은 Opus급 지능을 Sonnet의 가격($3/$15 per 1M tokens)으로 제공하므로, 기존에 비용 문제로 도입을 망설였던 복잡한 에이전트 워크플로우에 즉시 적용 가능하다.
- 100만 토큰 컨텍스트와 개선된 장기 추론 능력을 활용해 대규모 코드베이스 리팩터링이나 복잡한 금융 분석 에이전트 구축 시 성능 향상을 기대할 수 있다.
- 컴퓨터 사용 기능의 정확도가 임계치를 넘어서면서 API가 없는 레거시 시스템 자동화나 복잡한 웹 기반 업무 프로세스 자동화의 실무 적용 가능성이 높아졌다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료