핵심 요약
Anthropic이 자사 최상위 모델의 업그레이드 버전인 Claude Opus 4.6을 출시했다. 이전 모델 대비 코딩, 복잡한 추론, 자율적 에이전트 수행 능력이 크게 개선되었으며, 업계 최초로 100만 토큰 컨텍스트 창을 베타로 제공한다. 특히 경제적 가치가 높은 지식 노동 벤치마크(GDPval-AA)에서 GPT-5.2를 144 Elo 포인트 차이로 앞서는 성능을 보였으며, 적응형 사고(Adaptive Thinking)와 컨텍스트 압축(Context Compaction) 등 개발자 편의 기능이 대거 추가되었다. 현재 Claude API와 주요 클라우드 플랫폼을 통해 사용 가능하다.
배경
Claude API 사용 경험, 에이전트 워크플로우 및 도구 사용(Tool Use)에 대한 이해, 프롬프트 캐싱 및 토큰 관리 지식
대상 독자
LLM 기반 에이전트 개발자, 엔터프라이즈 AI 솔루션 설계자, 데이터 분석가
의미 / 영향
Claude Opus 4.6은 단순한 언어 모델을 넘어 자율적인 '에이전트'로서의 성능을 극대화하는 데 집중했다. 특히 긴 컨텍스트 유지 능력과 정교한 추론 제어 기능은 복잡한 기업용 워크플로우 자동화의 새로운 기준을 제시하며, GPT-5.2와의 경쟁에서 기술적 우위를 점하려는 Anthropic의 의지가 반영되었다.
섹션별 상세
이미지 분석
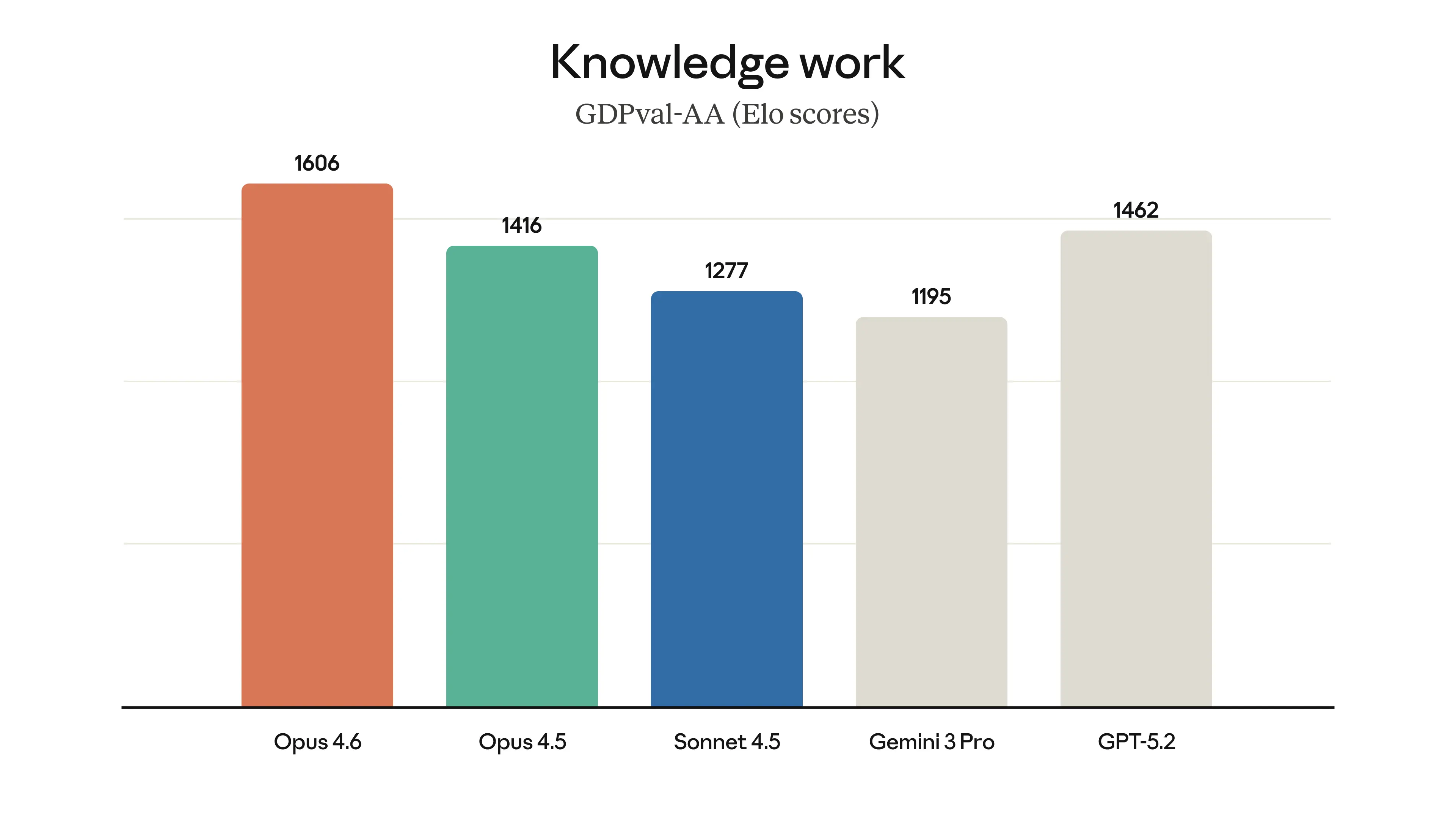
Opus 4.6이 1606점을 기록하며 GPT-5.2(1462점)와 Opus 4.5(1416점)를 크게 앞서는 것을 보여준다. 이는 경제적 가치가 높은 지식 노동 분야에서 Opus 4.6이 현재 가장 뛰어난 성능을 보유하고 있음을 수치로 증명한다.
GDPval-AA 벤치마크에서 Opus 4.6과 경쟁 모델들의 Elo 점수를 비교한 막대 그래프이다.
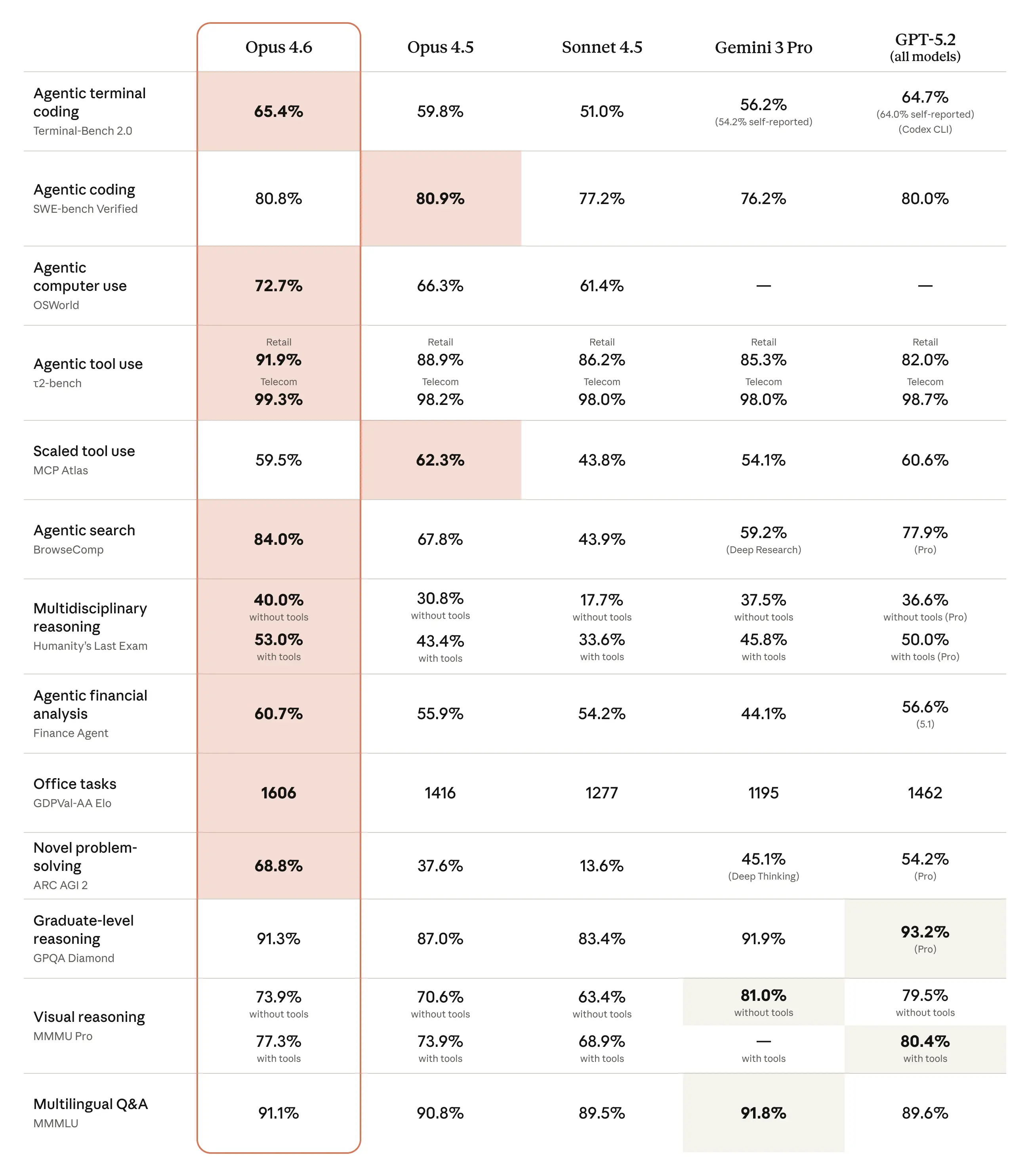
코딩, 컴퓨터 사용, 도구 활용, 추론 등 13개 이상의 지표에서 Opus 4.6이 대부분 1위를 차지하고 있음을 상세히 나타낸다. 특히 에이전트 관련 지표에서 경쟁 모델 대비 압도적인 우위를 점하고 있음을 확인할 수 있다.
다양한 벤치마크 지표에서 Opus 4.6과 경쟁 모델들의 성능 수치를 정리한 종합 비교표이다.
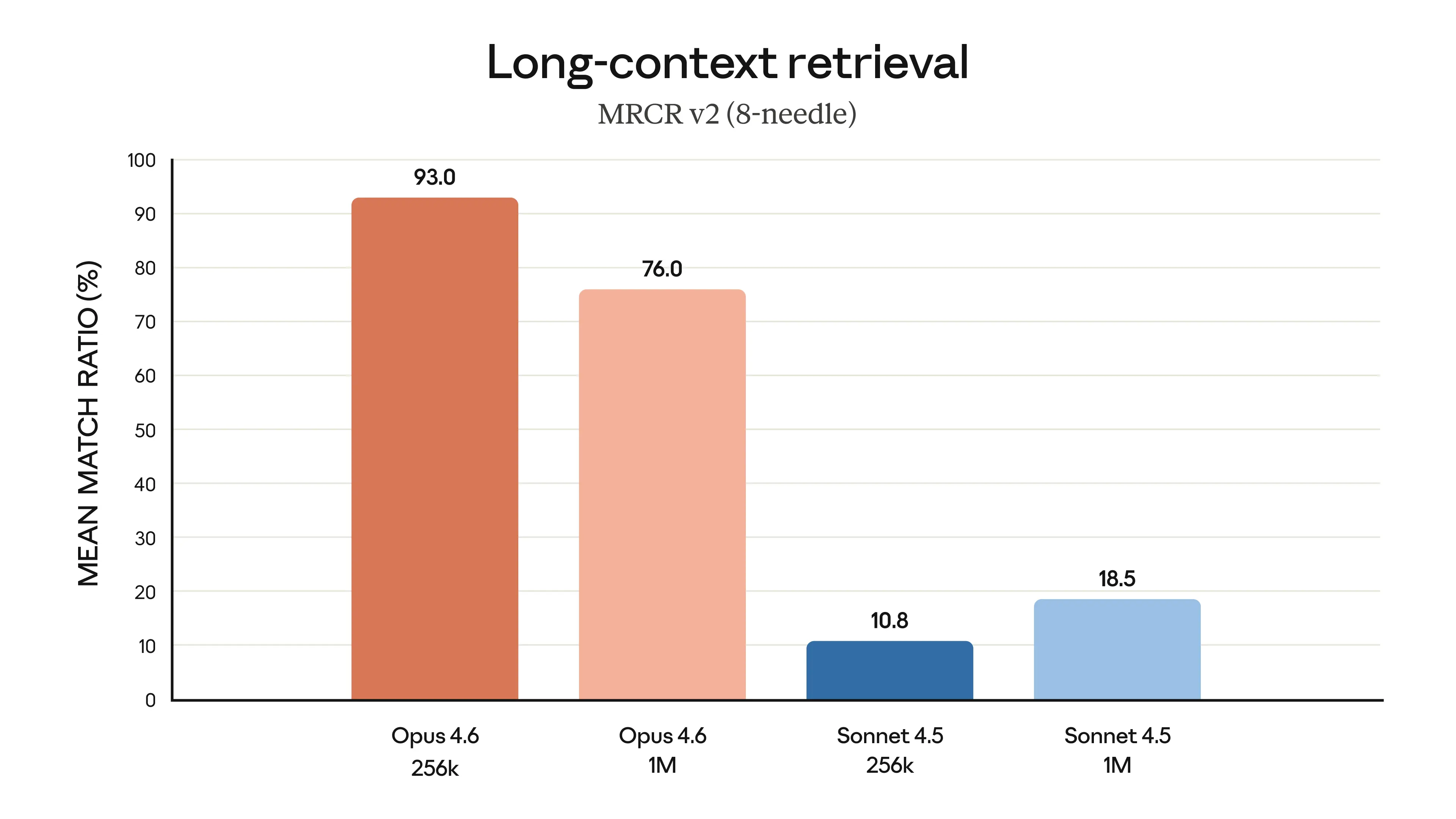
Opus 4.6이 100만 토큰 환경에서도 76%의 높은 검색 정확도를 유지함을 보여준다. 이는 Sonnet 4.5가 동일 환경에서 18.5%에 그친 것과 대조적이며, 대규모 데이터 처리 시의 신뢰성을 입증한다.
MRCR v2 벤치마크를 통한 긴 컨텍스트 정보 검색 성능 비교 차트이다.
실무 Takeaway
- 100만 토큰 컨텍스트와 컨텍스트 압축 기능을 결합하여 대규모 문서 분석 및 장기 에이전트 작업의 비용 효율성을 극대화할 수 있다.
- 새로운 /effort 파라미터를 활용해 단순 작업은 low로 비용을 아끼고, 복잡한 추론이 필요한 코딩이나 분석은 max로 설정하여 정확도를 높이는 전략적 운용이 필요하다.
- Claude Code의 에이전트 팀 기능을 활용하면 대규모 코드베이스 리팩터링이나 리뷰 작업을 병렬화하여 개발 속도를 획기적으로 높일 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료