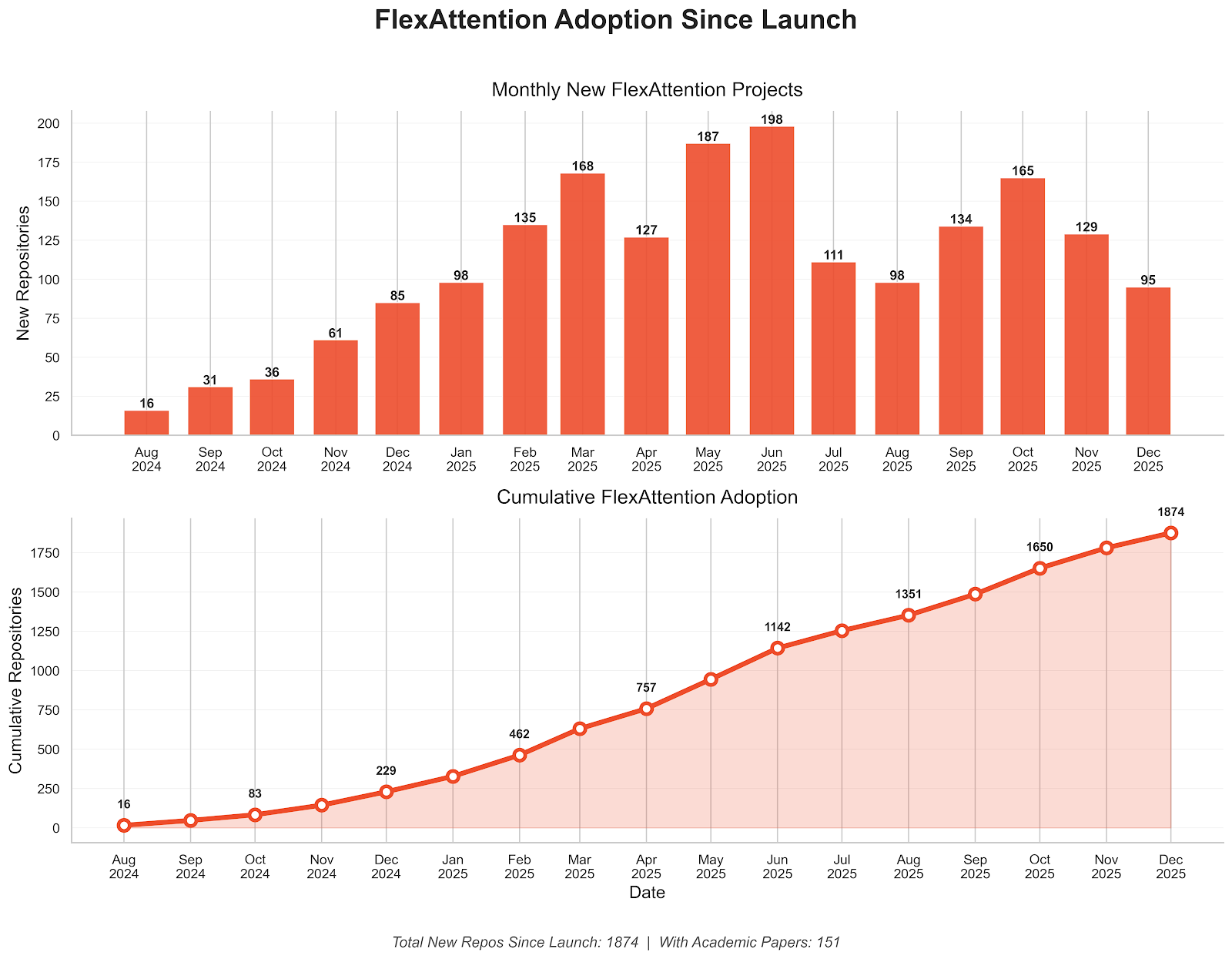
핵심 요약
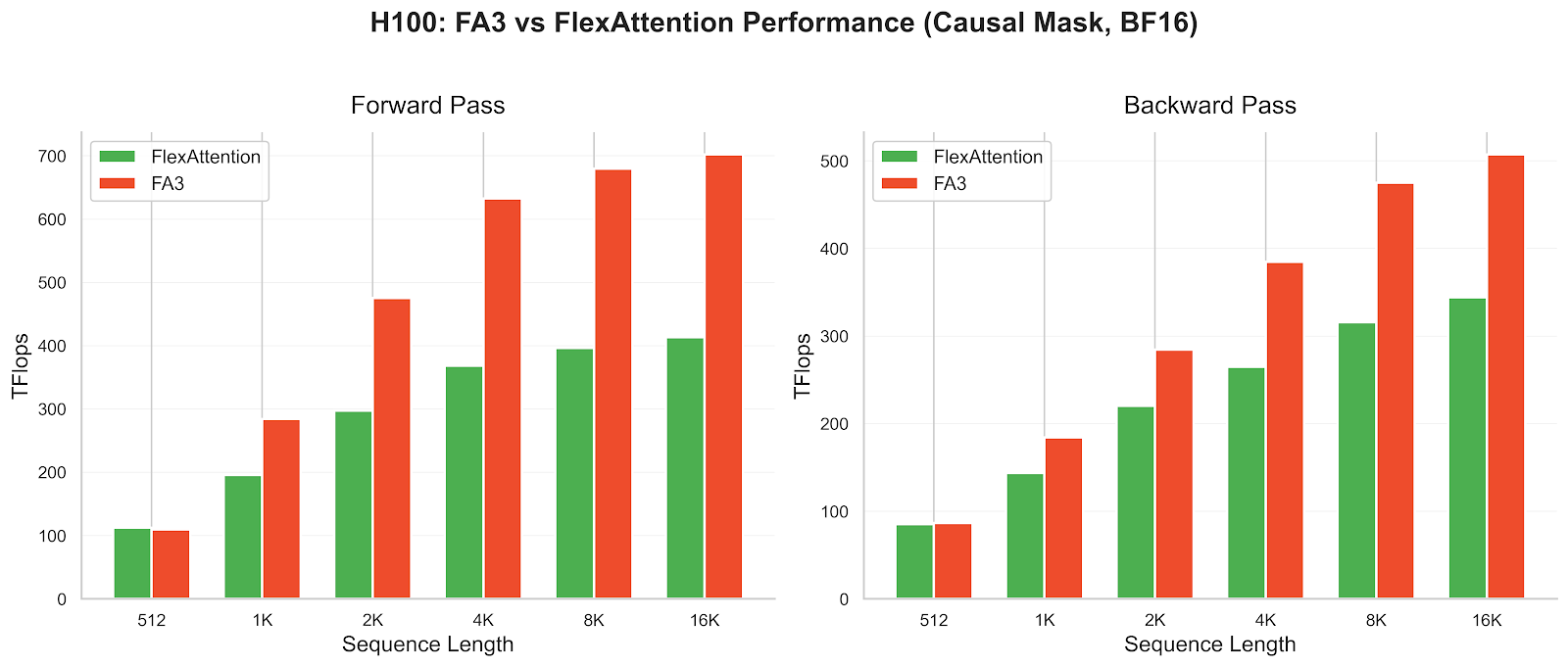
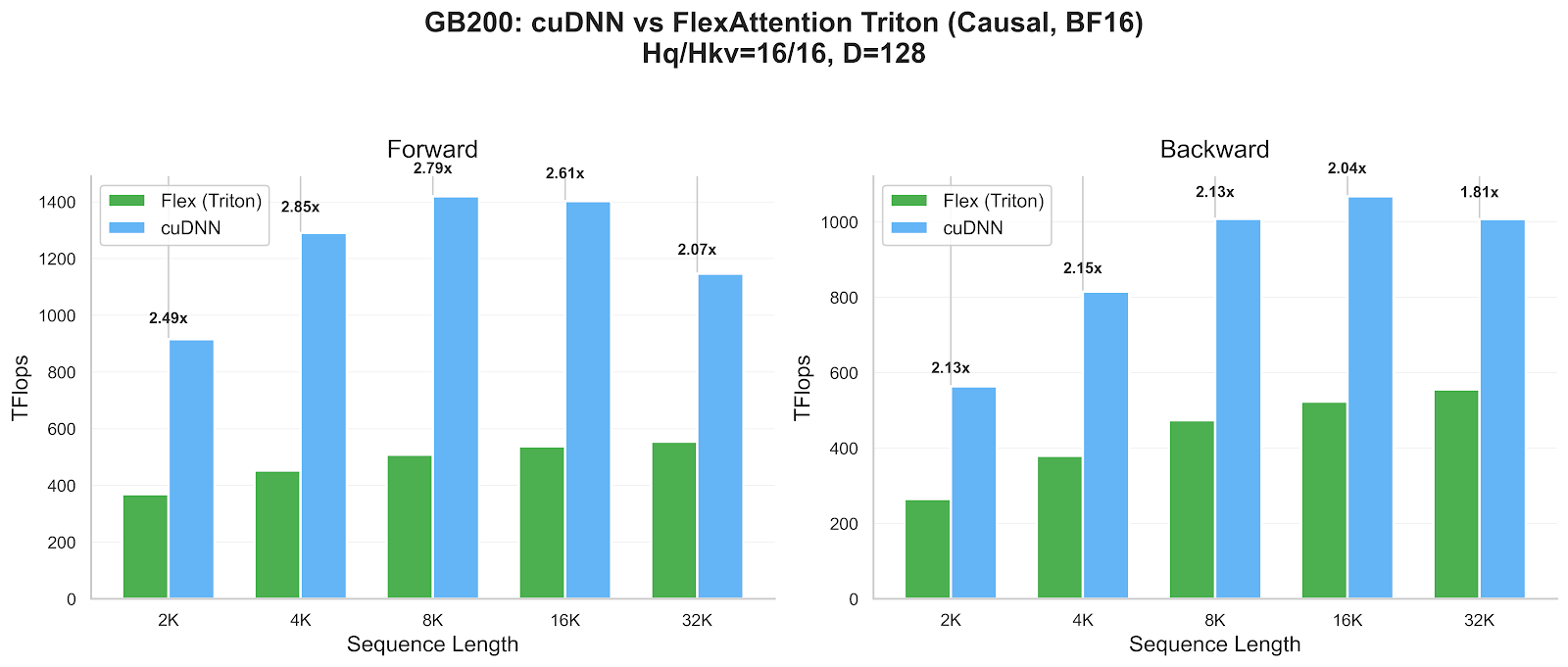
PyTorch는 커스텀 어텐션 변형을 쉽게 구현할 수 있는 FlexAttention API에 FlashAttention-4(FA4) 백엔드를 추가했다. 이번 업데이트는 NVIDIA Hopper 및 Blackwell GPU를 대상으로 하며, CuTeDSL을 활용해 사용자 정의 score_mod 및 mask_mod 함수를 고성능 CUDA 커널로 JIT 컴파일한다. 벤치마크 결과 기존 Triton 구현체 대비 1.2배에서 3.2배의 성능 향상을 보였으며, ALiBi, 슬라이딩 윈도우, 문서 마스킹 등 복잡한 패턴에서도 높은 효율을 증명했다. 이는 연구 단계의 새로운 어텐션 기법을 프로덕션 환경의 성능으로 즉시 전환할 수 있는 강력한 도구를 제공한다.
배경
PyTorch 2.x 사용 경험, Transformer 어텐션 메커니즘에 대한 이해, NVIDIA Hopper 또는 Blackwell 아키텍처 GPU 환경
대상 독자
고성능 LLM 학습 및 추론 최적화 엔지니어, 커스텀 어텐션 연구자
의미 / 영향
연구자들이 새로운 어텐션 기법을 제안할 때 성능 저하 없이 즉시 실험할 수 있게 하며, 최신 GPU의 하드웨어 기능을 소프트웨어 레벨에서 추상화하여 제공함으로써 개발 생산성을 크게 높인다.
섹션별 상세
import torch
from functools import partial
from torch.nn.attention.flex_attention import flex_attention
flex_flash = torch.compile(
partial(flex_attention, kernel_options={"BACKEND": "FLASH"}),
dynamic=False
)
def local_boost(score, b_idx, h_idx, q_idx, kv_idx):
return torch.where(torch.abs(q_idx - kv_idx) < 128, score * 1.1, score)
# 실행
out = flex_flash(q, k, v, score_mod=local_boost)FlexAttention에서 FlashAttention-4 백엔드를 사용하여 커스텀 score_mod를 적용하는 예시 코드

def tanh_softcap(score, b, h, q_idx, kv_idx):
return soft_cap * tanh(score / soft_cap)동적 스칼라 값(soft_cap)을 사용하는 예시로, 현재 백엔드에서는 값이 바뀔 때마다 재컴파일이 발생하는 제약이 있음
실무 Takeaway
- Hopper나 Blackwell GPU 환경에서 커스텀 어텐션을 사용하는 경우, kernel_options에 FLASH 백엔드를 설정하여 Triton 대비 최대 3배 이상의 성능 향상을 즉시 얻을 수 있다.
- ALiBi나 슬라이딩 윈도우와 같이 표준 SDPA가 지원하지 않는 패턴을 구현할 때, FlexAttention을 사용하면 CUDA 코드 작성 없이도 최적화된 FA4 성능을 활용 가능하다.
- Blackwell GPU의 CLC 기능을 활용하면 데이터에 따라 달라지는 복잡한 마스킹 패턴에서도 SM 간의 부하 불균형을 자동으로 해결하여 효율적인 추론 및 학습이 가능하다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.