이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
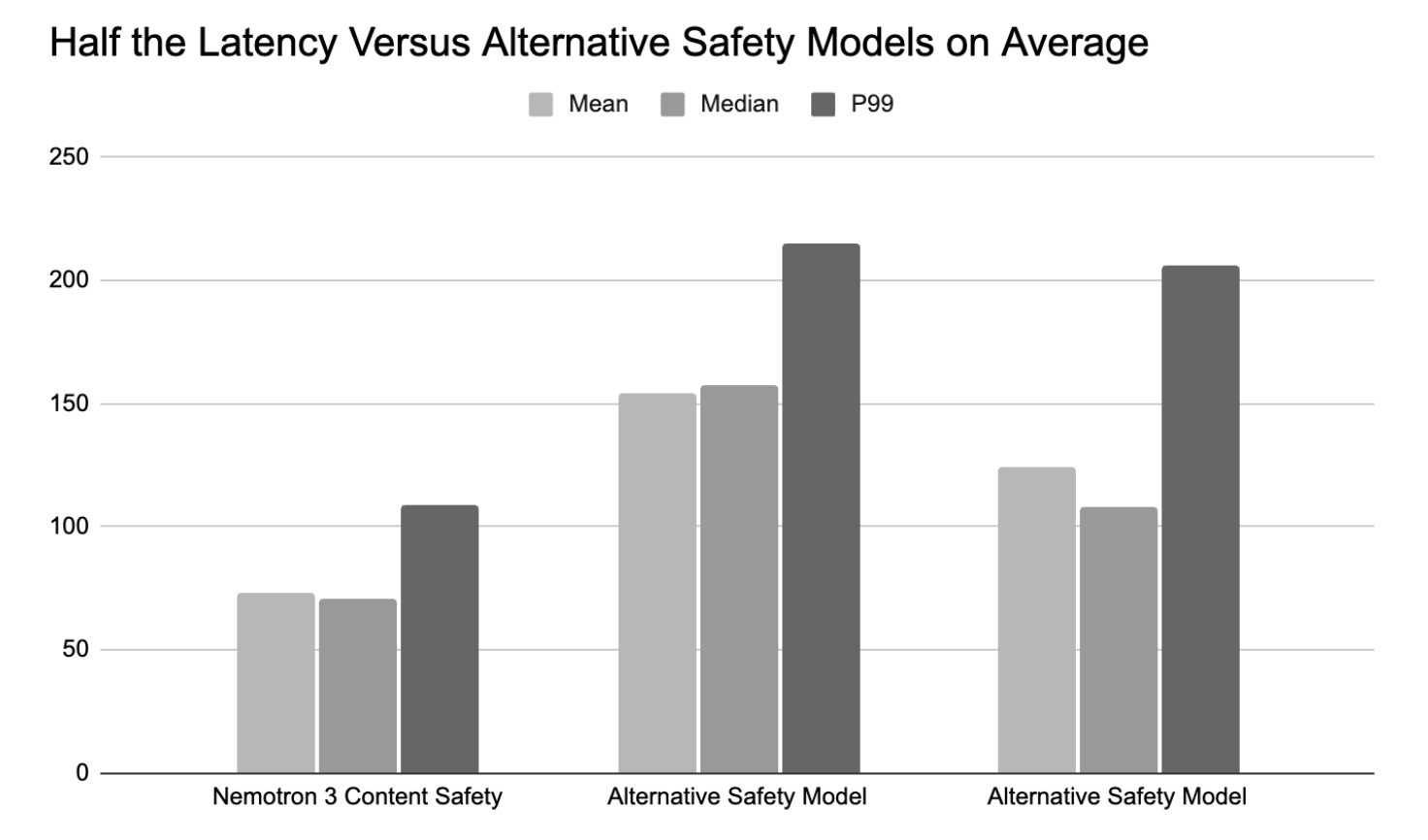
기존의 텍스트 중심 안전 모델은 다국어 환경과 이미지-텍스트 결합형 유해 콘텐츠 대응에 한계가 있었다. NVIDIA는 이를 해결하기 위해 Gemma-3 4B-IT를 기반으로 한 멀티모달·다국어 안전 모델인 Nemotron 3 Content Safety 4B를 출시했다. 이 모델은 LoRA 파인튜닝을 통해 경량화되었으며, 140개 이상의 언어를 지원하고 이미지와 텍스트의 상호작용을 정밀하게 분석한다. 벤치마크 결과 기존 모델 대비 절반 수준의 지연 시간과 84%의 높은 정확도를 기록하여 실시간 AI 에이전트 환경에 최적화되었다.
배경
LLM 및 VLM(Vision-Language Model)의 기본 개념, 콘텐츠 모더레이션 및 AI 안전성(Safety) 가이드라인, Python 및 Transformers/vLLM 라이브러리 사용 경험
대상 독자
실시간 멀티모달 AI 에이전트 및 글로벌 콘텐츠 플랫폼 개발자
의미 / 영향
이 모델은 AI 안전 가드레일의 성능과 속도 사이의 트레이드오프를 해결하여, 고성능 안전 검사를 실시간 추론 루프에 통합할 수 있게 한다. 특히 오픈 모델 기반의 경량화된 구조는 기업들이 자체 인프라에서 저비용으로 안전한 AI 서비스를 구축하는 데 기여할 것이다.
섹션별 상세
멀티모달 및 다국어 맥락 이해의 중요성: 텍스트와 이미지가 결합될 때 발생하는 비가산적(non-additive) 의미 변화를 포착한다. 예를 들어, 요리 도구로서의 칼 이미지는 안전하지만, 위해를 가하겠다는 텍스트와 결합되면 정책 위반으로 판단한다. 또한 특정 문화권에서 다르게 해석될 수 있는 상징물에 대한 문화적 맥락을 반영하여 오탐을 줄인다.
Gemma-3 기반 아키텍처와 효율적인 학습: Google의 Gemma-3 4B-IT 모델을 기반으로 구축되었으며, 128K 컨텍스트 윈도우를 지원한다. NVIDIA는 LoRA(Low-Rank Adaptation) 어댑터를 사용하여 모델을 파인튜닝함으로써, 4B라는 비교적 작은 파라미터 규모로도 강력한 추론 성능을 유지하면서 하드웨어 요구 사항을 낮췄다.
데이터셋 구성 및 합성 데이터 활용: Nemotron Content Safety Dataset v3와 인간이 라벨링한 멀티모달 데이터를 혼합하여 학습했다. 특히 12개 주요 언어로 번역된 데이터와 문서, 차트, 그래프 등 다양한 도메인의 이미지를 포함했다. 전체 학습 데이터의 약 10%는 Mixtral 8x22B 등을 활용한 합성 데이터(SDG)로 채워져 탈옥(Jailbreak) 패턴이나 희귀한 유해 사례에 대한 대응력을 높였다.
유연한 추론 모드와 표준 분류 체계: 단순 안전/불안전 분류(Default mode)와 상세 유해 카테고리 출력(Category-rich mode)의 두 가지 모드를 지원한다. 유해 카테고리는 ML Commons와 정렬된 Aegis AI Content Safety Dataset v2 분류 체계를 따르며, 폭력, 범죄 계획, 개인정보 침해 등 구체적인 위반 항목을 명시할 수 있다.
성능 벤치마크 및 실시간 배포 최적화: Polyguard, VLGuard 등 주요 안전 벤치마크에서 평균 84%의 정확도를 달성했다. 특히 추론 속도 면에서 기존 대형 모델 대비 약 50% 수준의 낮은 지연 시간(Latency)을 보여주며, 8GB 이상의 VRAM을 가진 GPU에서도 실시간 실행이 가능하다. 4월 중 NVIDIA NIM으로도 제공될 예정이다.


실무 Takeaway
- 멀티모달 AI 에이전트를 운영하는 개발자는 Nemotron 3 Content Safety를 도입하여 이미지 내 텍스트와 대화 맥락이 결합된 복합적 유해 콘텐츠를 실시간으로 차단할 수 있다.
- LoRA 기반의 4B 경량 모델이므로 8GB VRAM 수준의 보급형 GPU에서도 낮은 지연 시간으로 안전 검사를 수행하여 운영 비용을 절감할 수 있다.
- 140개 이상의 언어를 지원하므로 글로벌 서비스를 운영할 때 각 지역의 문화적 특수성이 반영된 정교한 콘텐츠 모더레이션을 구현할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 21.수집 2026. 03. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.