핵심 요약
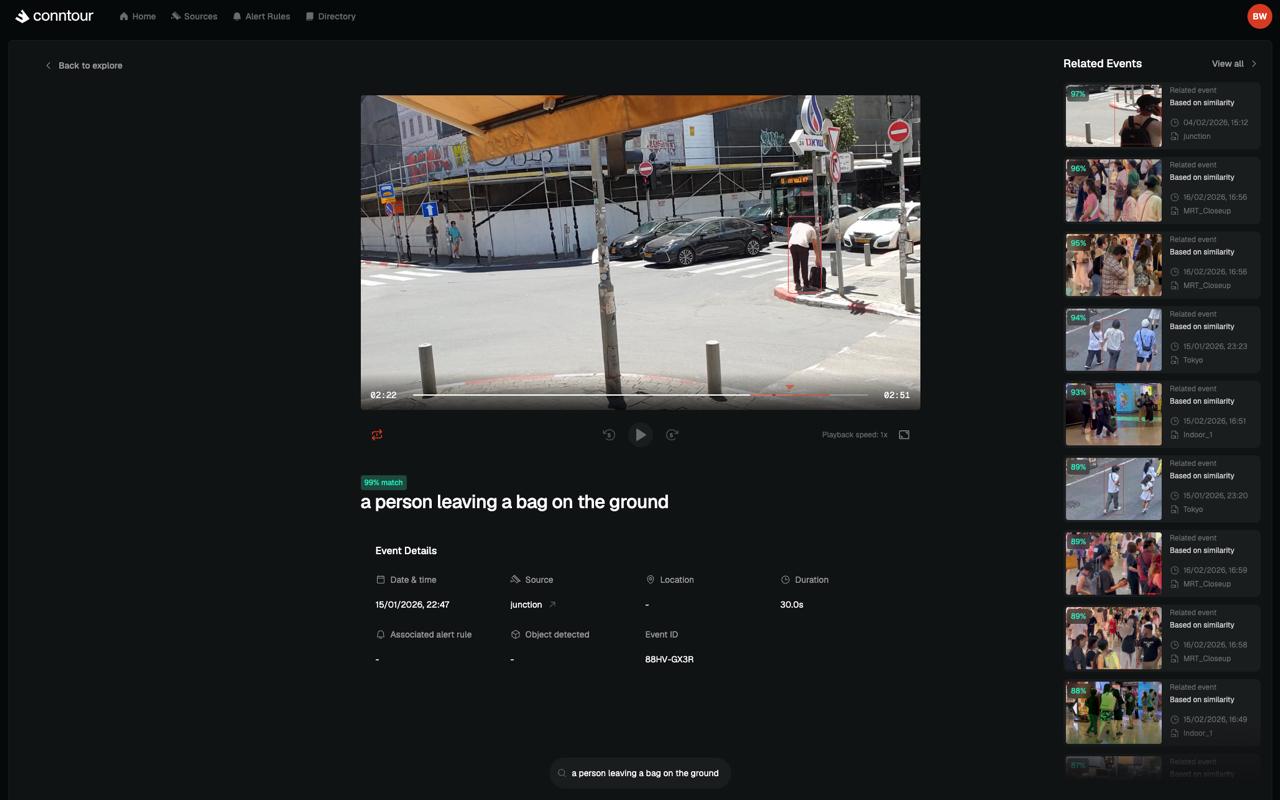
기존 비디오 감시 시스템은 사전 정의된 규칙에 의존해 유연성이 낮았으나, Conntour는 비전-언어 모델(VLM)을 도입해 자연어 쿼리로 특정 객체나 상황을 실시간 검색한다. 사용자가 "로비에서 운동화를 신은 사람이 가방을 전달하는 장면"을 검색하면 시스템은 수천 개의 피드를 분석해 관련 영상과 텍스트 보고서를 즉시 생성한다. 특히 단일 소비자용 GPU인 Nvidia RTX 4090으로 최대 50개의 카메라 피드를 처리하는 높은 효율성을 달성하여 대규모 인프라 확장이 용이하다. 싱가포르 중앙마약국 등 정부 기관을 고객으로 확보하며 기술력을 입증했고, 최근 General Catalyst 등으로부터 700만 달러의 시드 투자를 성공적으로 마무리했다.
배경
컴퓨터 비전 기초 지식, 비전-언어 모델(VLM)의 기본 개념, GPU 가속 및 추론 효율화에 대한 이해
대상 독자
물리 보안 시스템 관리자, AI 기반 영상 분석 솔루션 개발자, 스마트 시티 인프라 기획자
의미 / 영향
비전-언어 모델의 효율화로 인해 대규모 영상 감시의 자동화가 가속화될 것이며, 이는 공공 안전 향상과 동시에 프라이버시 침해 논란을 심화시킬 수 있다. 특히 소비자용 하드웨어에서의 높은 처리 효율은 중소 규모 사업장까지 AI 보안 도입 문턱을 낮추는 계기가 될 것이다.
섹션별 상세
실무 Takeaway
- 비전-언어 모델(VLM)을 활용하면 기존의 규칙 기반 감시 시스템이 놓치기 쉬운 복잡한 행동 패턴을 자연어 검색으로 정교하게 찾아낼 수 있다.
- 단일 Nvidia RTX 4090 GPU로 50개 피드를 처리하는 Conntour의 사례처럼, 모델 최적화와 쿼리별 로직 분배를 통해 AI 보안 시스템의 운영 비용을 획기적으로 낮출 수 있다.
- 보안 및 감시 분야의 AI 도입 시 데이터 프라이버시를 위해 온프레미스 배포 옵션과 AI 판단의 불확실성을 보완하는 신뢰도 점수 제공이 필수적이다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.