TL;DR
Amazon Nova 멀티모달 임베딩은 텍스트, 이미지, 오디오, 비디오를 하나의 벡터 공간으로 통합하여 관리하는 모델로, 단순 전사(Transcription)를 넘어 오디오의 음향적 특징까지 포착한다. 기존의 텍스트 기반 검색이 놓치던 감정, 리듬, 악기 특성 등을 256에서 3,072 차원의 수치 벡터로 변환하여 저장한다. 사용자는 Amazon Bedrock의 동기 및 비동기 API를 통해 실시간 검색이나 대규모 인덱싱 작업을 수행할 수 있으며, 마트료시카 표현 학습(MRL)을 통해 성능과 비용 간의 균형을 최적화할 수 있다. 결과적으로 수천 시간의 오디오 아카이브에서 특정 분위기나 주제가 포함된 구간을 밀리초 단위로 정확하게 찾아내는 프로덕션 수준의 시스템 구현이 가능하다.
배경
AWS Bedrock 기본 사용법, Python 및 Boto3 라이브러리 지식, 벡터 데이터베이스 및 k-NN 검색에 대한 기본 이해
대상 독자
AWS 기반으로 멀티미디어 검색 엔진이나 RAG 시스템을 구축하려는 AI 엔지니어 및 솔루션 아키텍트
의미 / 영향
이 기술은 오디오 데이터를 단순한 텍스트 변환 대상이 아닌, 그 자체로 풍부한 정보를 가진 멀티모달 데이터로 취급하게 합니다. 특히 콜센터 분석, 미디어 자산 관리, 콘텐츠 추천 시스템에서 텍스트만으로는 파악하기 힘든 '뉘앙스'와 '분위기' 기반의 검색을 가능케 하여 사용자 경험을 한 단계 끌어올릴 것입니다.
섹션별 상세
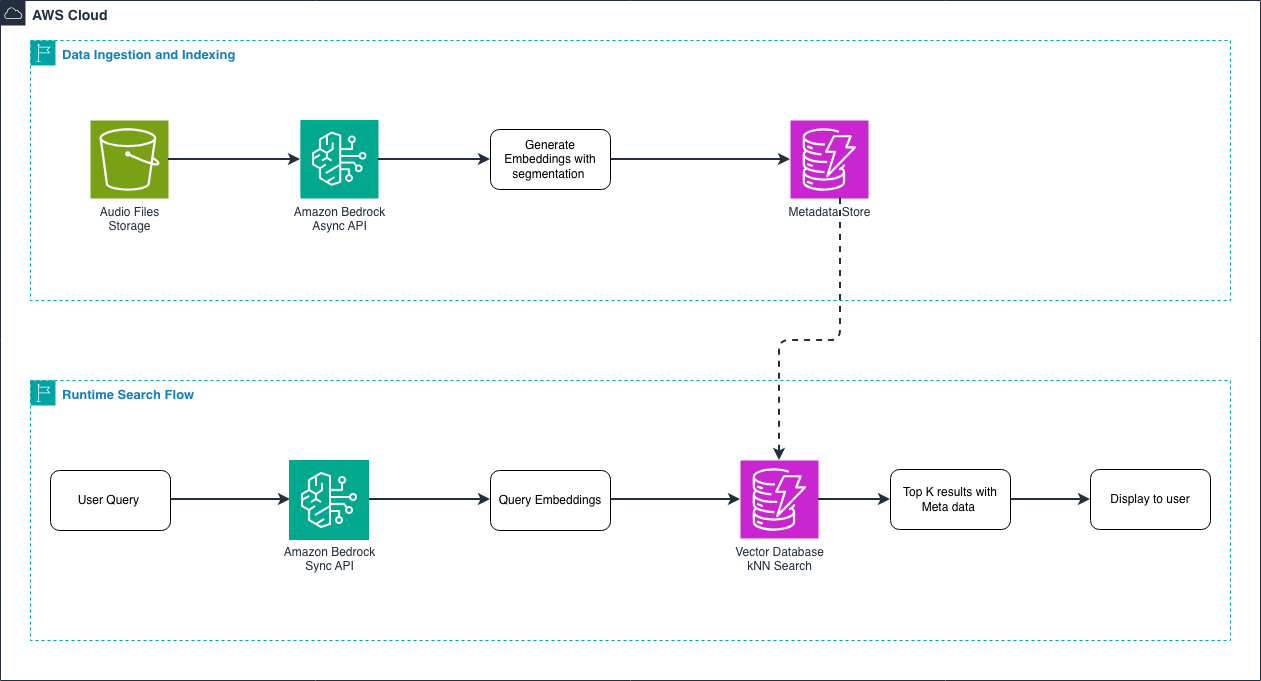
- Amazon Nova 멀티모달 임베딩은 3,072, 1,024, 384, 256의 네 가지 차원 옵션을 제공한다. — Understanding Audio Embeddings: Core Concepts 섹션
import boto3
import json
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": 1024,
"text": {
"truncationMode": "END",
"value": "jazz piano music"
}
}
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]Amazon Bedrock의 동기식 API를 사용하여 텍스트 쿼리에 대한 오디오 검색용 임베딩을 생성하는 예시
response = bedrock_runtime.start_async_invoke(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {"s3Uri": "s3://amzn-s3-demo-bucket/output/"}
}
)
invocation_arn = response["invocationArn"]
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]대용량 파일 처리를 위해 비동기식 API를 호출하고 작업 상태를 확인하는 예시
- 30초를 초과하는 오디오 파일은 자동으로 세그먼트화되어 시간적 메타데이터와 함께 처리된다. — Segmentation and Temporal Metadata 섹션
용어 해설
- Multimodal Embeddings
- — 텍스트, 이미지, 오디오, 비디오 등 서로 다른 형태의 데이터를 동일한 고차원 벡터 공간상의 수치로 변환하는 기술입니다. 이를 통해 '슬픈 음악'이라는 텍스트 쿼리로 실제 슬픈 분위기의 오디오 파일을 찾아내는 등 매체 간 교차 검색이 가능해집니다.
- Matryoshka Representation Learning (MRL)
- — 하나의 임베딩 벡터 내에 여러 크기의 정보를 계층적으로 구조화하여 학습하는 방식입니다. 큰 차원의 벡터 앞부분만 잘라내어 작은 차원으로 사용해도 성능 저하를 최소화하면서 저장 공간과 계산 비용을 유연하게 관리할 수 있게 해줍니다.
- Cosine Similarity
- — 두 벡터 사이의 각도를 측정하여 유사성을 계산하는 지표로, 1에 가까울수록 두 데이터의 의미적/음향적 특징이 유사함을 의미합니다. 벡터의 크기보다 방향성에 집중하므로 텍스트나 오디오의 의미적 유사성을 판단하는 데 널리 쓰입니다.
- k-Nearest Neighbor (k-NN)
- — 벡터 공간에서 특정 쿼리 벡터와 가장 거리가 가까운 k개의 데이터를 찾아내는 검색 알고리즘입니다. 오디오 검색 시스템에서 사용자의 질문과 가장 유사한 특징을 가진 오디오 클립 상위 k개를 추출하는 핵심 메커니즘으로 작동합니다.
근거 모음
- 1,024 차원 임베딩 100만 개를 저장하는 데 약 4GB의 벡터 스토리지가 필요하다. — Vector Storage and Indexing Strategies 섹션의 Example calculation
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.