이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대용량 데이터 파일에서 특정 정보를 효율적으로 찾기 위해 서버 측 처리 없이 클라이언트에서 직접 이진 탐색을 수행하는 실험적 도구를 개발했다. Claude와 브레인스토밍을 통해 유니코드 코드포인트 조회를 적합한 사례로 선정하고, Claude Code를 이용해 실제 구현을 진행했다. 76.6MB 크기의 메타데이터 파일을 S3에 저장하고 HTTP Range Request를 통해 필요한 바이트 범위만 요청함으로써 검색 속도와 데이터 전송량을 최적화했다. 이 과정에서 HTTP 압축이 바이트 오프셋 계산을 방해하여 Range Request와 호환되지 않는다는 기술적 특이점을 확인했다.
배경
HTTP 프로토콜 기초, 이진 탐색 알고리즘 이해, JavaScript Fetch API
대상 독자
웹 성능 최적화와 AI 보조 프로그래밍에 관심 있는 개발자
의미 / 영향
대용량 정적 파일을 서버 사이드 로직 없이 클라이언트에서 직접 검색하는 패턴은 서버 비용 절감과 응답 속도 향상에 기여할 수 있다. 특히 코딩 에이전트를 활용한 프로토타이핑 가속화의 실질적인 사례를 나타낸다.
섹션별 상세
HTTP Range Request를 활용하면 전체 파일을 다운로드하지 않고도 서버의 특정 바이트 범위 데이터만 선택적으로 가져올 수 있어 대용량 파일 처리에 유리하다.
정렬된 76.6MB 유니코드 메타데이터 파일을 대상으로 이진 탐색 알고리즘을 적용하여 단 17번의 fetch() 요청만으로 원하는 문자의 정보를 찾아내는 성능을 구현했다.
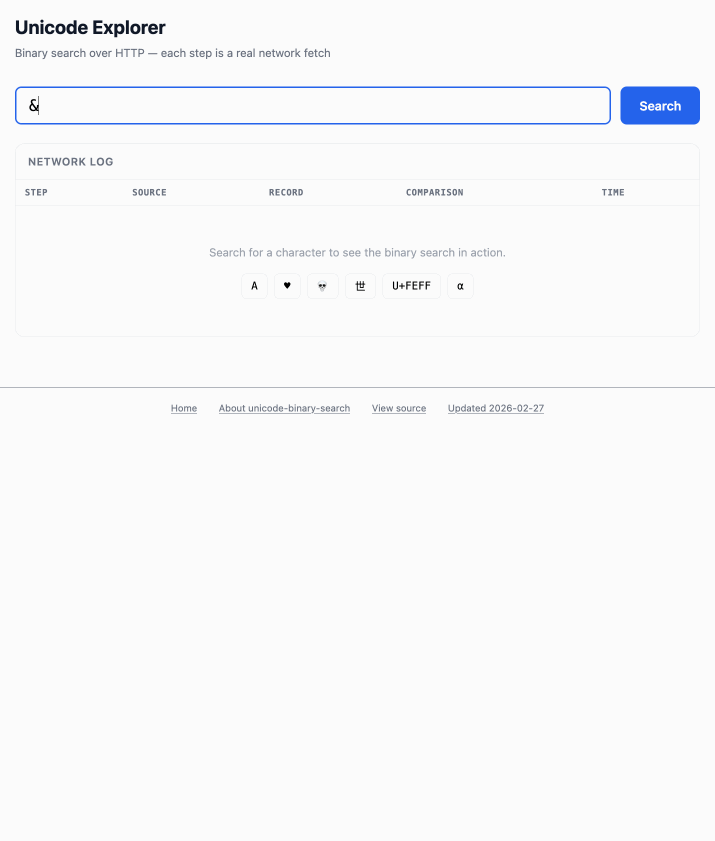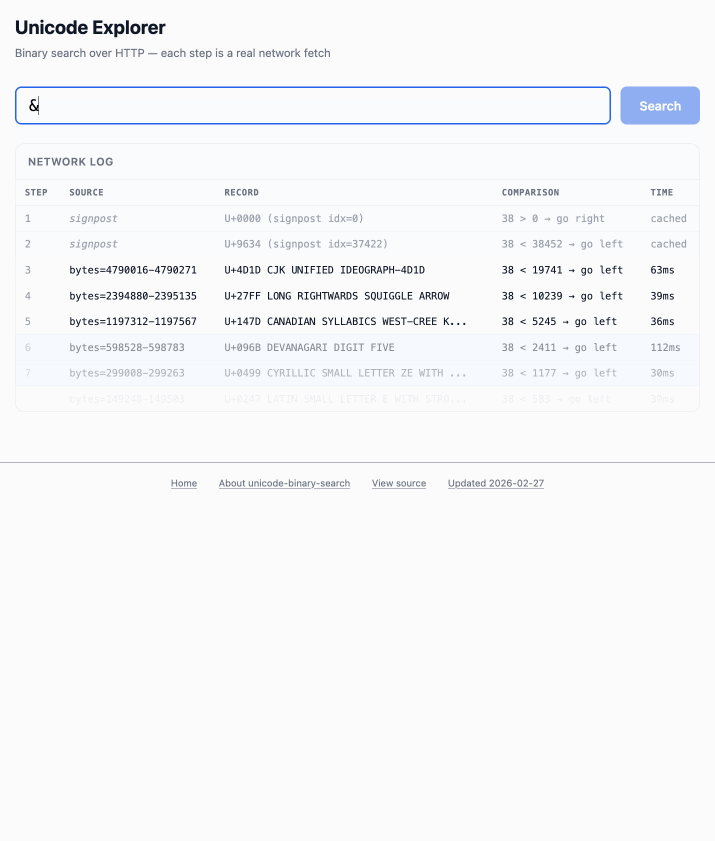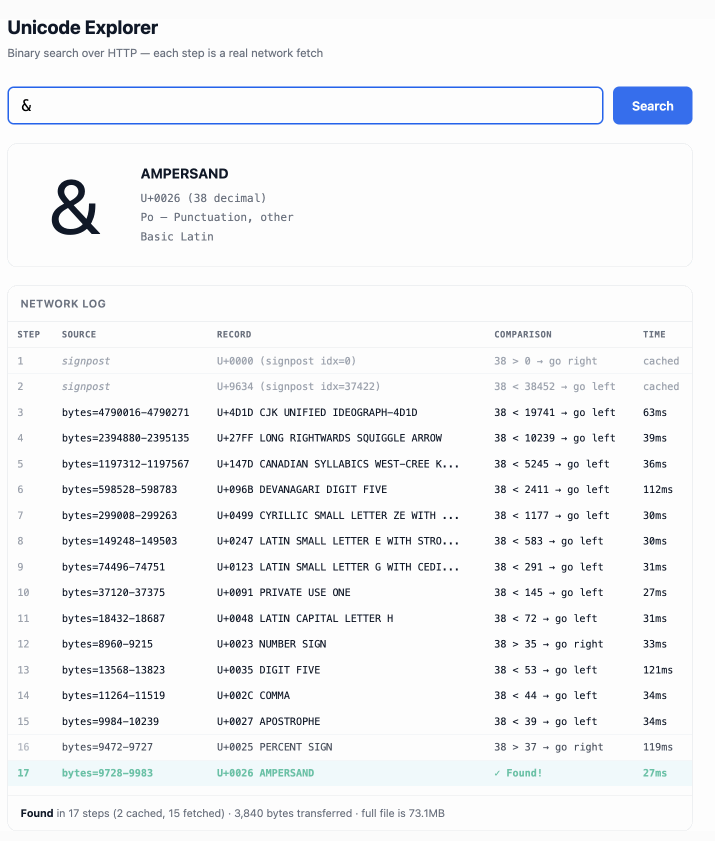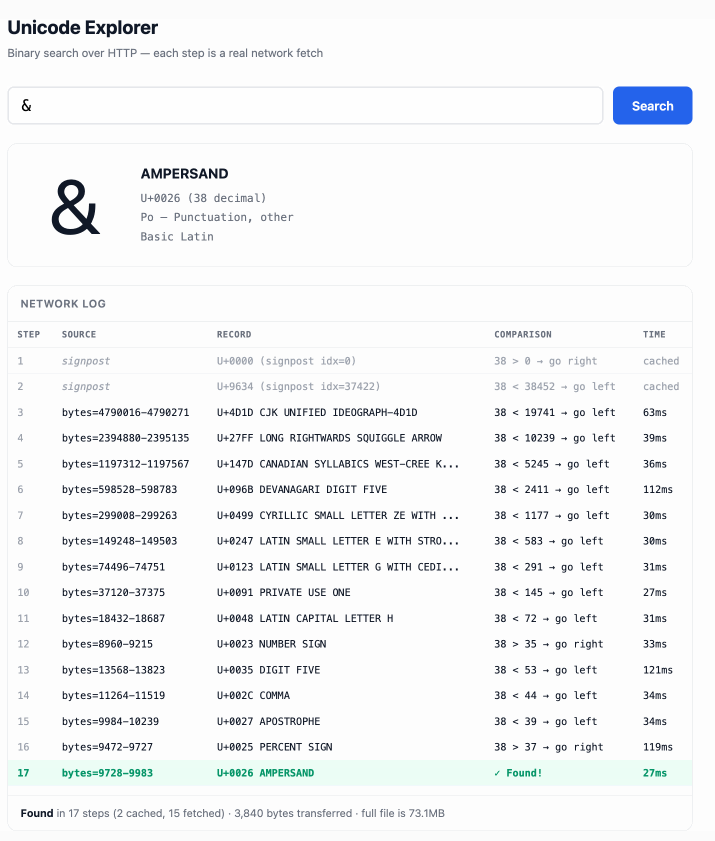
Claude를 통해 아이디어를 구체화하고 Claude Code 에이전트에게 상세 스펙을 제공하여 비동기적으로 코드를 생성하는 AI 협업 워크플로우를 적용했다.
Range Request 사용 시 HTTP 압축이 적용되면 실제 데이터의 바이트 위치와 압축된 데이터의 위치가 달라져 계산 오류가 발생하므로 Accept-Encoding: identity 설정이 필요함을 발견했다.
Cloudflare와 같은 CDN은 Content-Range 헤더가 존재할 경우 자동으로 압축을 건너뛰어 Range Request의 무결성을 보장한다는 운영 환경의 특성을 확인했다.
실무 Takeaway
- 대용량 정렬 데이터셋을 다룰 때 HTTP Range Request와 이진 탐색을 결합하면 서버 리소스 없이 클라이언트 사이드에서 초고속 검색 시스템을 구축할 수 있다.
- Claude Code와 같은 코딩 에이전트를 활용할 때 명확한 스펙을 먼저 작성하여 전달하면 복잡한 로직 구현의 정확도와 생산성을 크게 높일 수 있다.
- 바이트 단위의 정밀한 데이터 접근이 필요한 기능 구현 시 CDN이나 서버의 자동 압축 설정이 오프셋 계산에 미치는 영향을 반드시 고려해야 한다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 28.수집 2026. 03. 01.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.