이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
기존 검색 API는 인간의 브라우징에 최적화된 HTML 중심 데이터를 반환하여 AI 에이전트가 직접 활용하기에 부적합했습니다. AWS의 Strands Agents SDK와 Exa의 통합은 AI 네이티브 검색 레이어를 제공하여 LLM이 즉시 소비할 수 있는 정제된 구조화 데이터를 제공합니다. 이 시스템은 모델이 스스로 도구 호출 여부와 순서를 결정하는 모델 기반 아키텍처를 따르며, semantic search와 실시간 콘텐츠 추출 기능을 결합합니다. 실제 구현 사례인 딥 리서치 에이전트는 뉴스, 논문, GitHub 등 다양한 소스를 6단계 워크플로를 통해 자율적으로 탐색하고 종합적인 보고서를 생성합니다.
배경
Python 3.10 이상, Amazon Bedrock 접근 권한이 있는 AWS 계정, Exa API Key
대상 독자
실시간 웹 정보 검색 기능이 필요한 AI 에이전트 및 RAG 시스템 개발자
의미 / 영향
이 기술은 AI 에이전트가 정적인 지식 베이스를 넘어 실시간 웹 생태계와 상호작용하는 방식을 표준화합니다. 특히 구조화된 데이터 제공과 관측성 도구의 결합은 기업용 에이전트의 신뢰성과 디버깅 가능성을 획기적으로 높여줍니다.
섹션별 상세
기존 검색 API의 HTML 중심 데이터는 AI 에이전트가 처리하기 위해 복잡한 파싱과 랭킹 로직이 추가로 필요했습니다. Exa는 AI 전용 검색 엔진으로서 광고나 SEO 노이즈가 없는 깨끗하고 구조화된 콘텐츠를 LLM 컨텍스트 윈도우에 직접 전달합니다. 이를 통해 개발자는 별도의 데이터 전처리 레이어를 구축할 필요 없이 에이전트의 추론 루프에 실시간 지식을 주입할 수 있습니다. 결과적으로 에이전트는 더 정확하고 최신화된 정보를 바탕으로 의사결정을 내릴 수 있게 됩니다.
Strands Agents SDK는 하드코딩된 워크플로 대신 모델이 스스로 도구 사용을 결정하는 오픈 소스 프레임워크입니다. 개발자가 모델, 시스템 프롬프트, 도구 목록을 제공하면 에이전트 루프 내에서 모델이 대화 이력을 바탕으로 다음 단계를 결정합니다. 40개 이상의 사전 빌드된 도구와 Model Context Protocol(MCP)을 지원하여 확장성이 뛰어납니다. 이러한 자율적 구조는 단일 LLM 호출로 해결할 수 없는 복잡한 다단계 작업을 수행하는 데 핵심적인 역할을 합니다.
Exa 통합은 exa_search와 exa_get_contents라는 두 가지 핵심 도구를 통해 웹 검색 및 추출 기능을 제공합니다. exa_search는 키워드가 아닌 의미 기반의 semantic search를 수행하며 뉴스, 논문, PDF 등 특정 카테고리 필터링을 지원합니다. exa_get_contents는 특정 URL에서 전체 텍스트를 추출하며, 캐시된 결과가 없을 경우 실시간 크롤링(live crawling)을 수행하여 최신성을 보장합니다. 두 도구 모두 AI가 이해하기 쉬운 구조화된 요약과 JSON 스키마 기반 추출을 지원합니다.
실제 사례인 딥 리서치 에이전트는 6단계의 정교한 워크플로를 통해 자율적으로 정보를 수집하고 합성합니다. 개요 검색부터 시작하여 뉴스, 학술 논문, GitHub 프로젝트를 순차적으로 탐색한 뒤 가장 유망한 URL에서 심층 정보를 추출합니다. 마지막 단계에서는 수집된 모든 정보를 바탕으로 실행 요약과 출처가 명시된 리서치 브리프를 생성합니다. 이 과정은 단일 시스템 프롬프트에 의해 구동되며 에이전트가 스스로 소스 유형에 맞춰 검색 파라미터를 조정합니다.
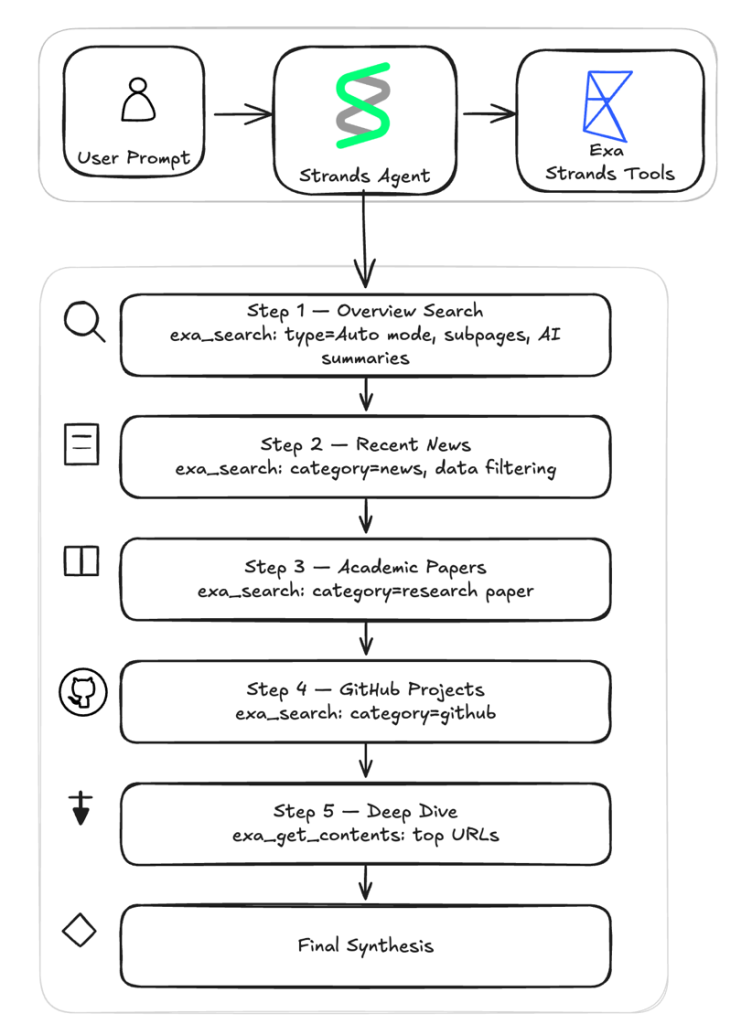
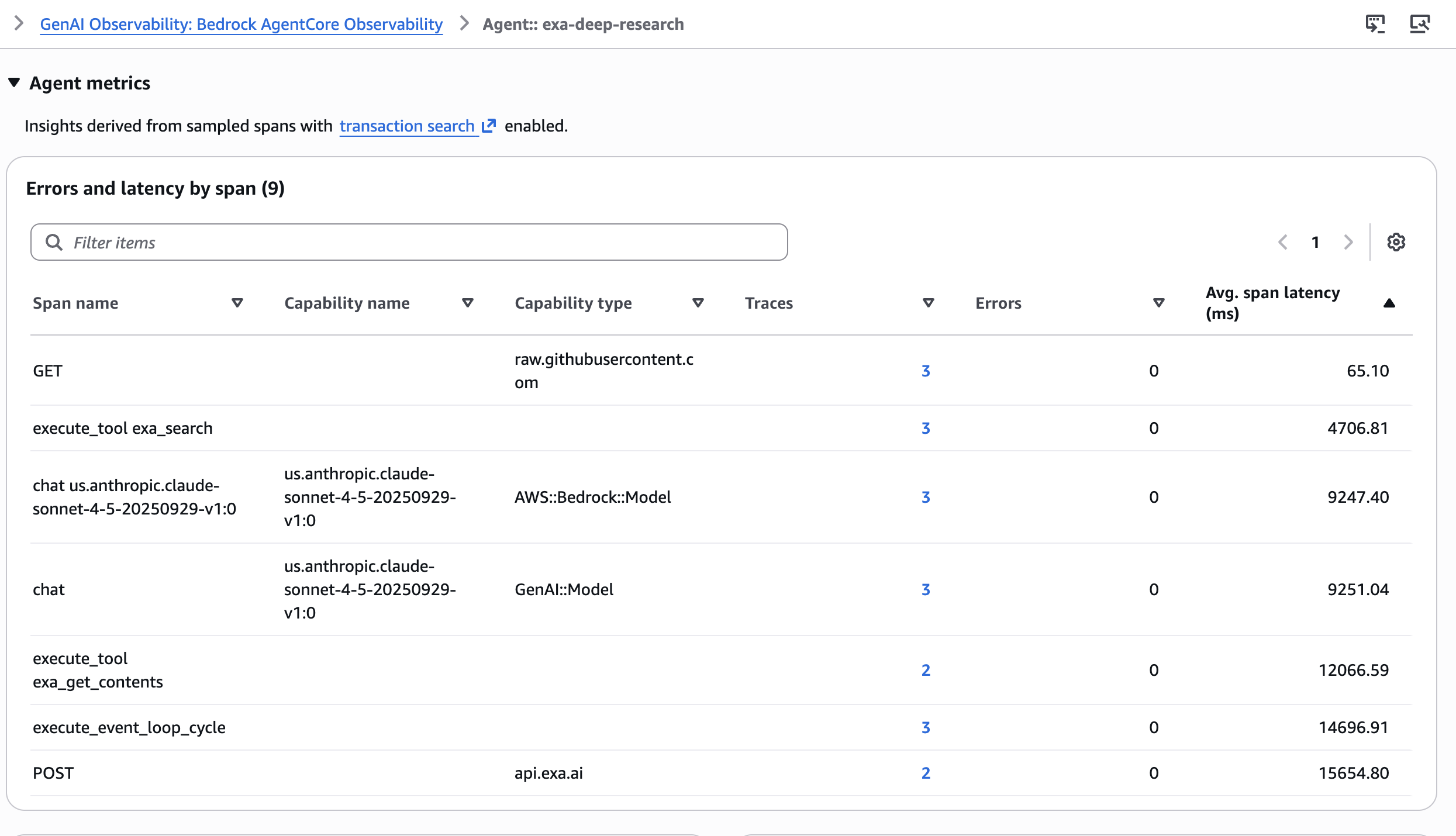
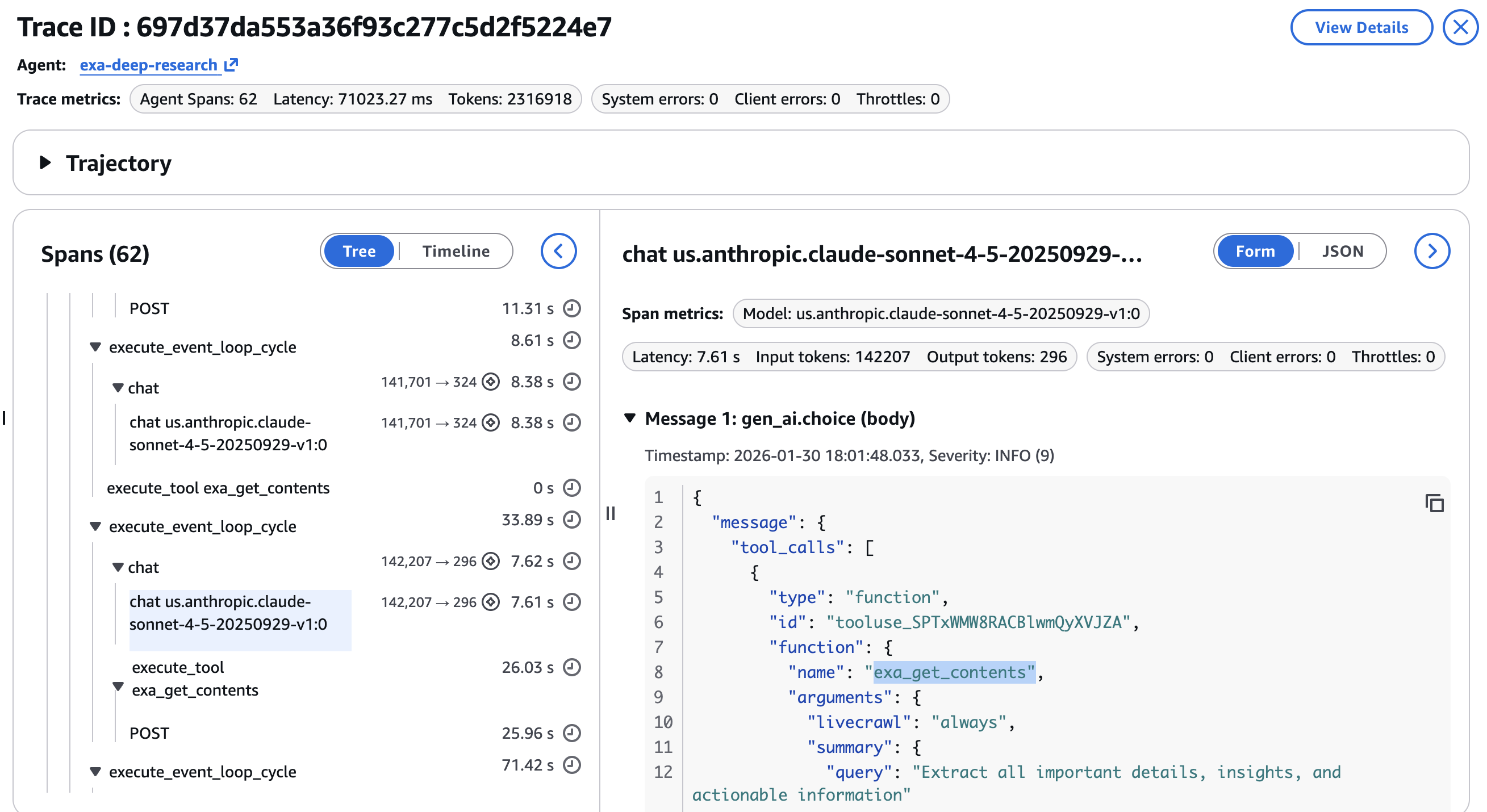
에이전트의 비결정론적 동작과 다단계 도구 호출을 디버깅하기 위해 Amazon Bedrock AgentCore Observability를 활용합니다. OpenTelemetry 기반의 이 도구는 각 도구 호출과 LLM 호출을 스팬(span) 단위로 계측하여 전체 실행 과정을 시각화합니다. 개발자는 CloudWatch 대시보드에서 각 단계별 지연 시간, 토큰 소비량, 도구 호출 파라미터의 정확성을 검증할 수 있습니다. 이는 에이전트 워크플로의 병목 지점을 파악하고 추론 성능을 최적화하는 데 필수적인 데이터를 제공합니다.
실무 Takeaway
- RAG 시스템 구축 시 일반 검색 API 대신 Exa를 사용하면 HTML 파싱 비용을 없애고 LLM 컨텍스트에 최적화된 정제된 텍스트만 주입하여 할루시네이션을 줄일 수 있습니다.
- Strands Agents의 모델 기반 아키텍처를 활용하면 복잡한 조건문 없이도 모델이 상황에 맞춰 뉴스 검색이나 논문 분석 중 최적의 도구를 스스로 선택하게 할 수 있습니다.
- Amazon Bedrock AgentCore Observability를 연동하여 에이전트의 다단계 추론 과정을 추적하면 비결정론적인 에이전트 동작의 원인을 정확히 파악하고 성능을 튜닝할 수 있습니다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 12.수집 2026. 05. 12.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.