이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
멀티모달 AI 모델은 비디오, 오디오, 텍스트 등 복합 데이터를 처리하며 전처리 과정에서 CPU 병목이 빈번하게 발생한다. 기존의 단계별 배치 실행이나 단일 노드 방식은 I/O 오버헤드나 자원 불균형으로 인해 GPU 활용률을 50% 이하로 떨어뜨린다. Ray Data는 CPU와 GPU 연산을 분리하고 데이터를 디스크에 쓰지 않고 네트워크로 직접 스트리밍하는 아키텍처를 통해 이 문제를 해결한다. 이를 통해 독립적인 자원 확장이 가능해지며, 실제 워크로드에서 기존 방식 대비 처리량을 2.5배에서 12배까지 개선한다.
대상 독자
프로덕션 환경에서 대규모 멀티모달 데이터셋을 처리하는 AI 엔지니어 및 인프라 설계자
의미 / 영향
대규모 멀티모달 모델 학습 및 추론에서 데이터 파이프라인의 효율성이 모델 성능만큼 중요해지고 있다. 연산 자원의 분리형 아키텍처는 인프라 비용을 절감하고 개발 속도를 높이는 핵심 요소로 자리 잡을 것이다.
섹션별 상세
전통적인 단계별 배치 실행은 전처리와 학습 단계를 스토리지로 연결하여 불필요한 I/O와 중간 데이터 저장 비용을 발생시킨다. 500TB 데이터셋 처리 시 중간 데이터가 1PB 이상 생성되어 전체 파이프라인 시간이 16시간 이상 소요되는 비효율이 나타난다.
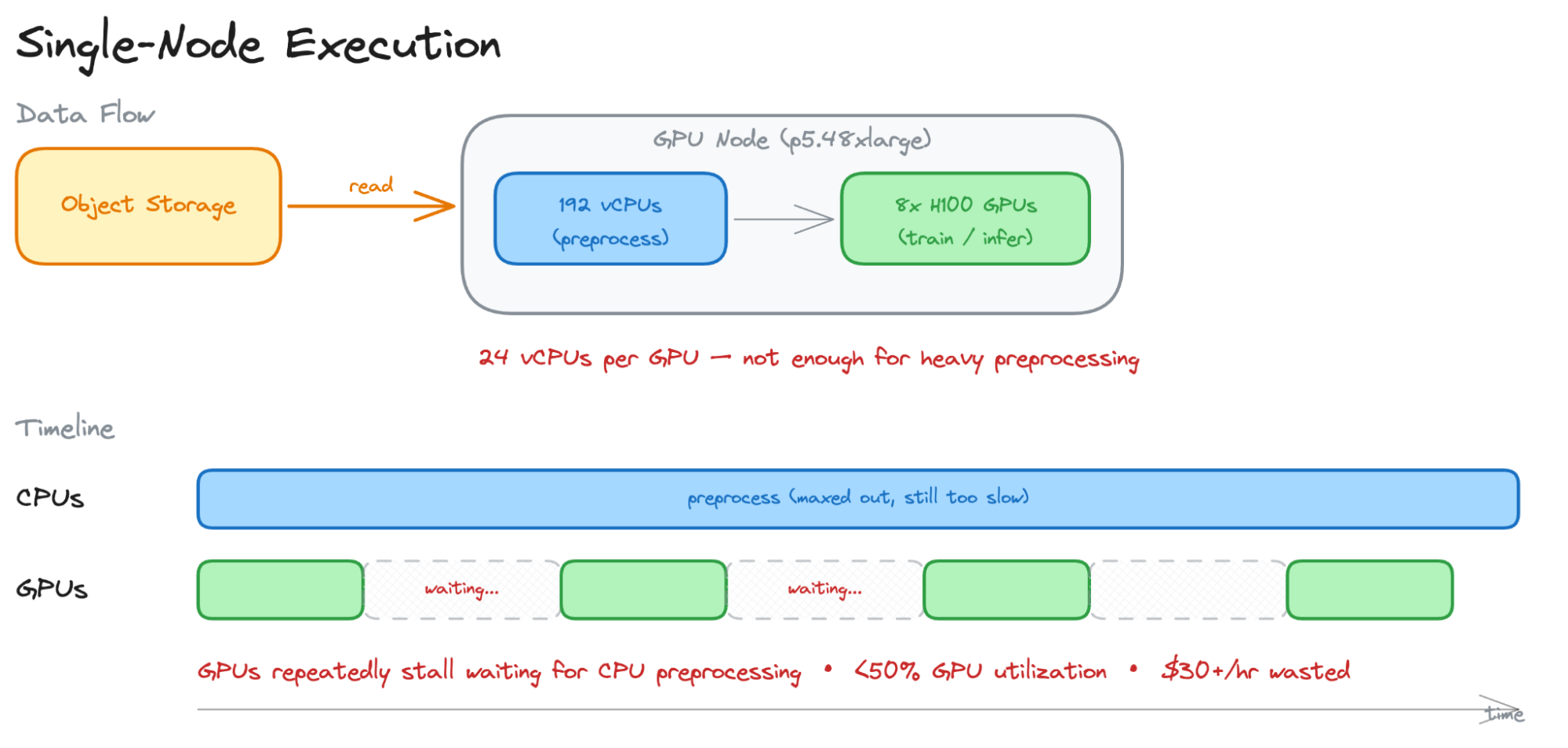
단일 노드 실행 방식은 GPU 인스턴스의 CPU/GPU 비율 불균형으로 인해 전처리 성능이 GPU 연산 속도를 따라가지 못한다. 이로 인해 GPU가 CPU 전처리를 기다리며 유휴 상태가 되어 시간당 수십 달러의 비용이 낭비된다.
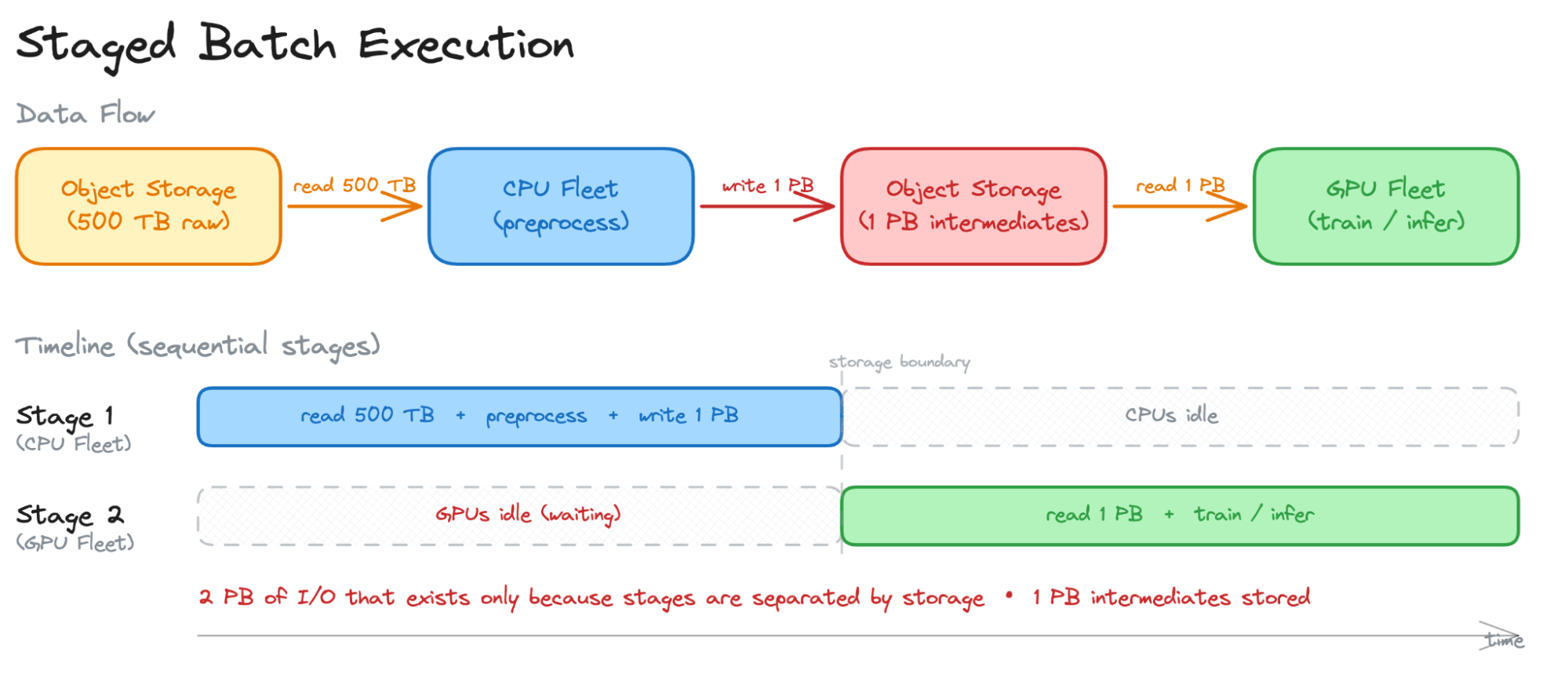
분리형 스트리밍은 전처리용 CPU 클러스터와 학습용 GPU 클러스터를 분리하여 네트워크로 데이터를 직접 전송한다. 중간 데이터를 디스크에 기록하지 않아 I/O 비용이 제거되며, 각 클러스터를 워크로드에 맞춰 독립적으로 확장할 수 있다.
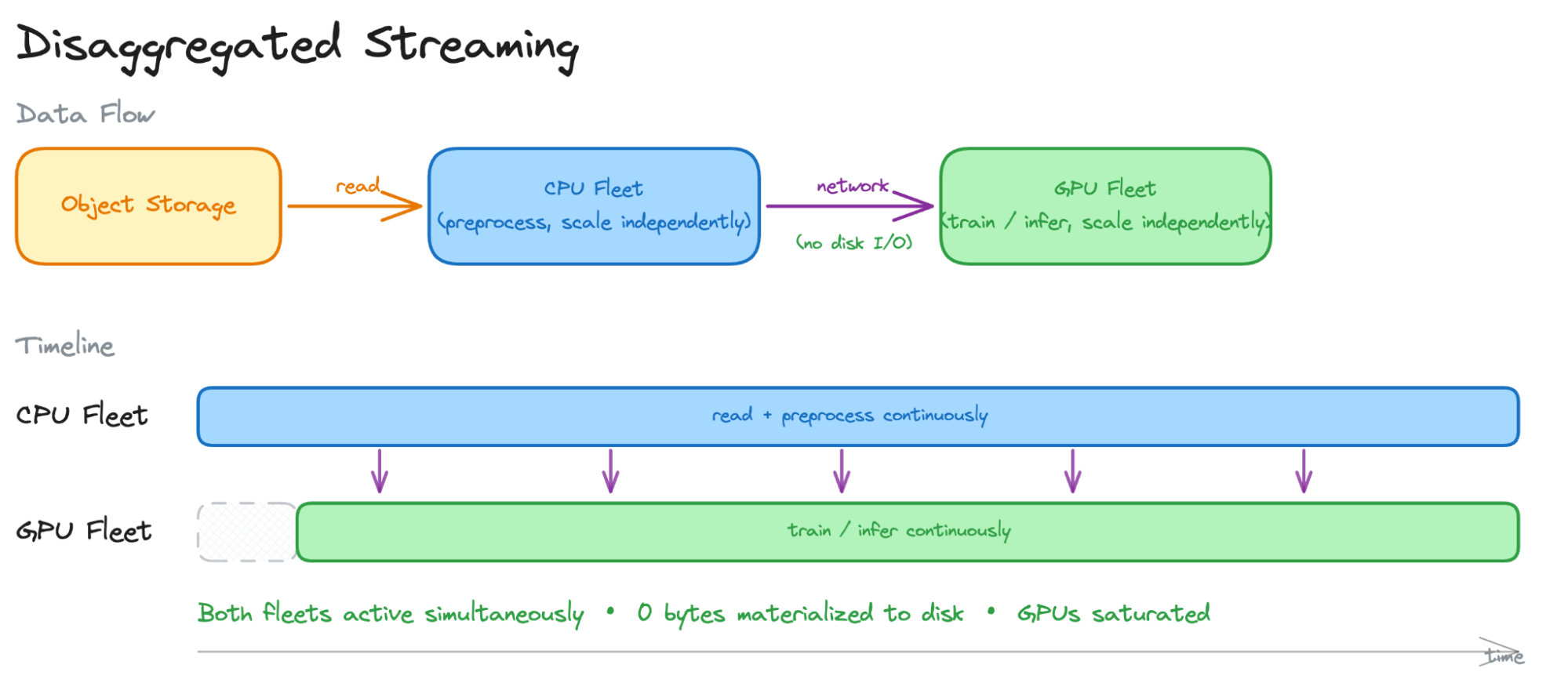
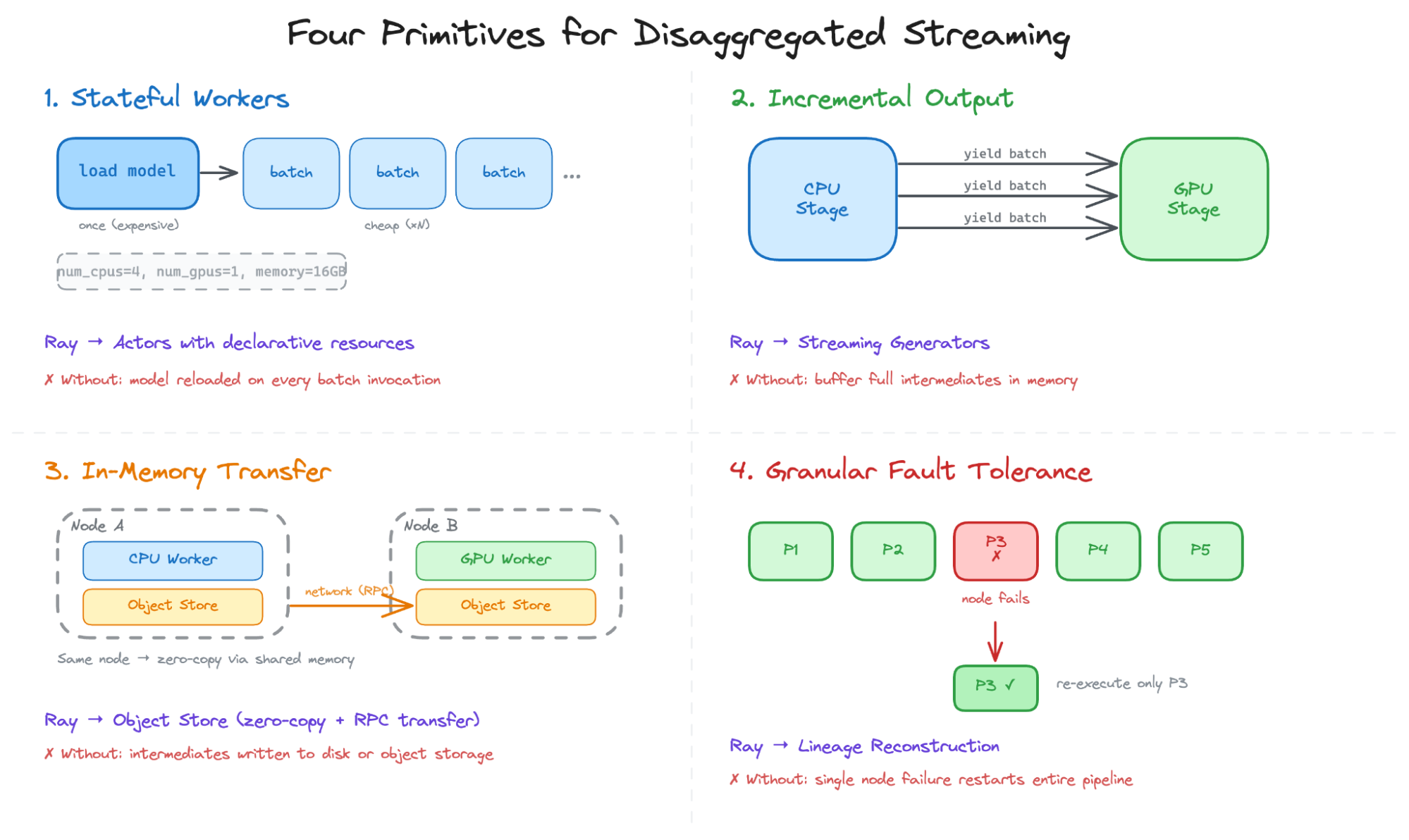
Ray Data는 상태 유지 워커, 증분 출력, 메모리 내 데이터 전송, 세분화된 장애 복구라는 4가지 핵심 프리미티브를 통해 스트리밍 파이프라인을 구현한다. 이를 통해 데이터가 블록 단위로 흐르며 전처리와 학습이 동시에 수행되어 GPU 활용률을 극대화한다.
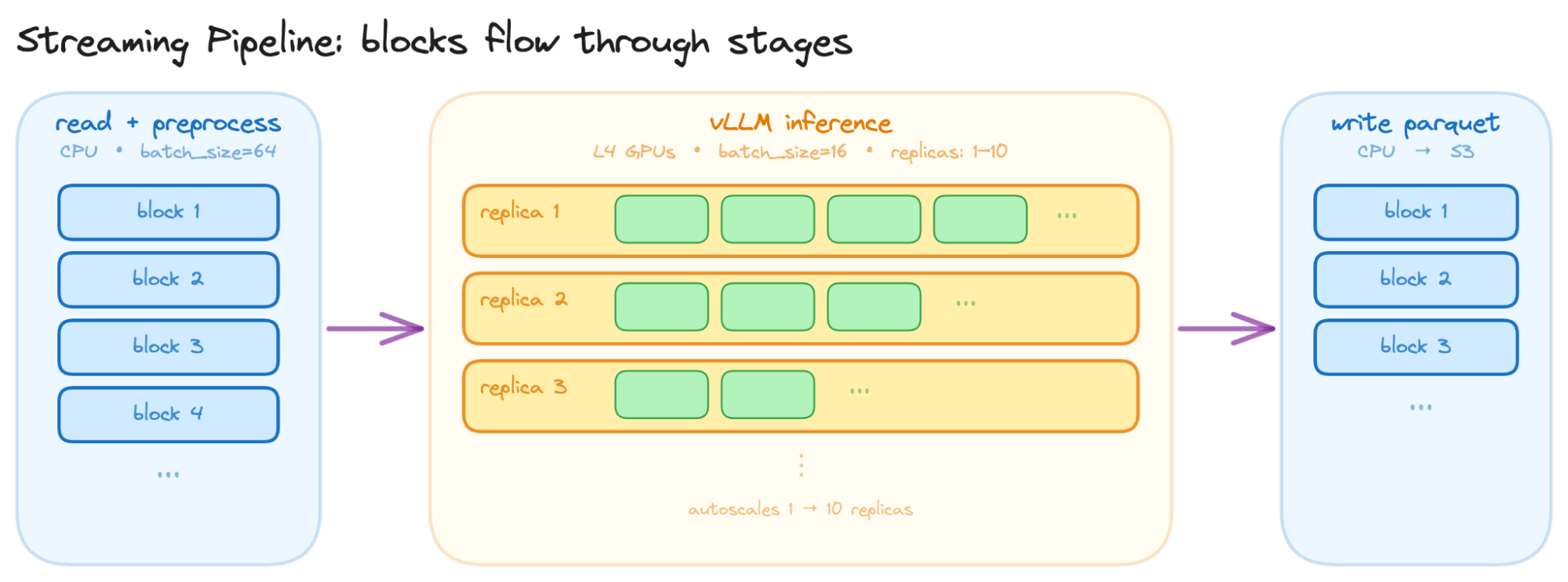
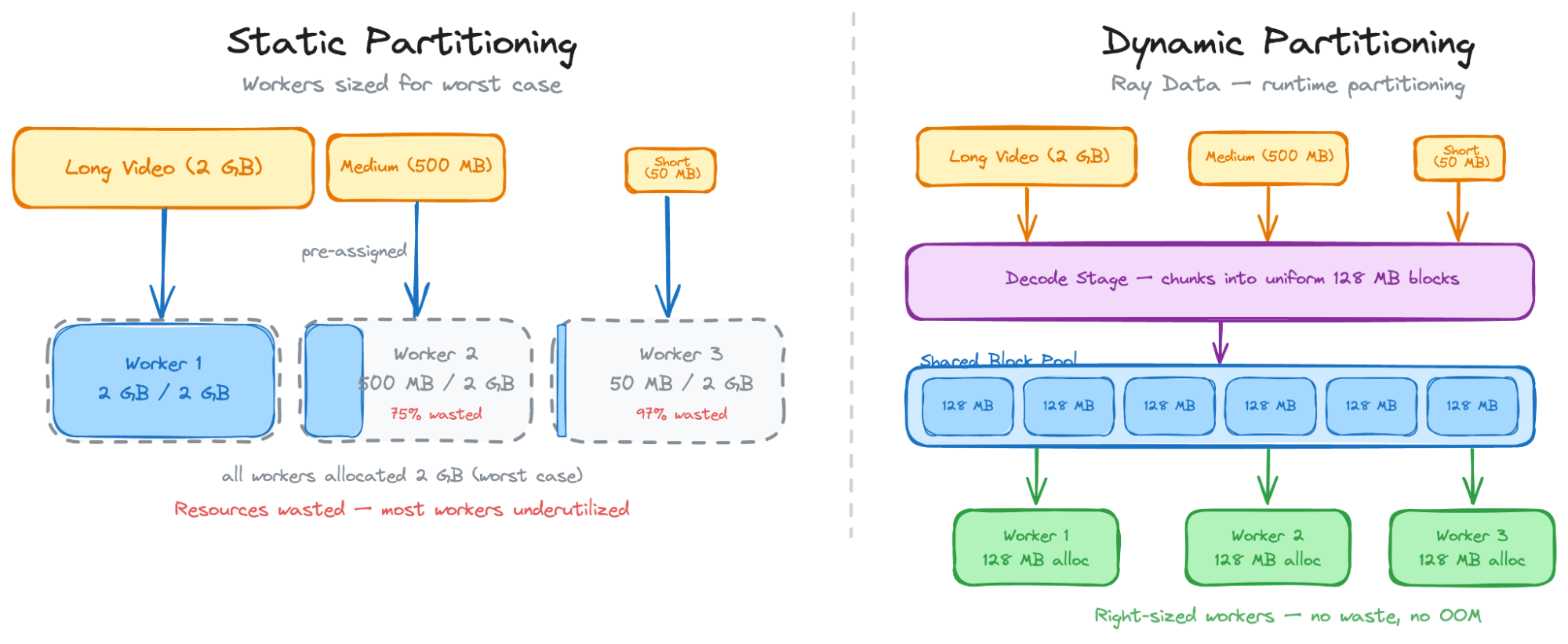
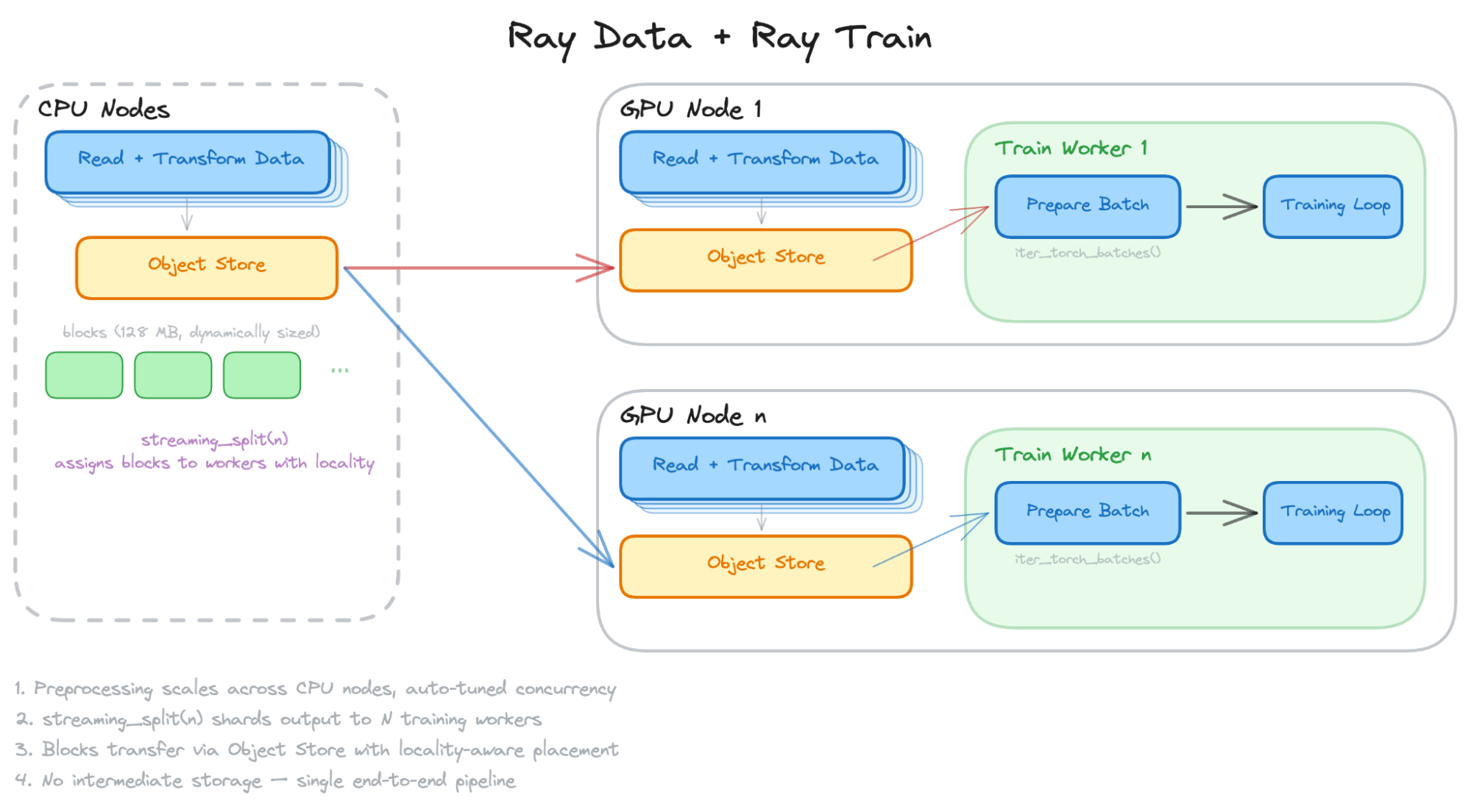
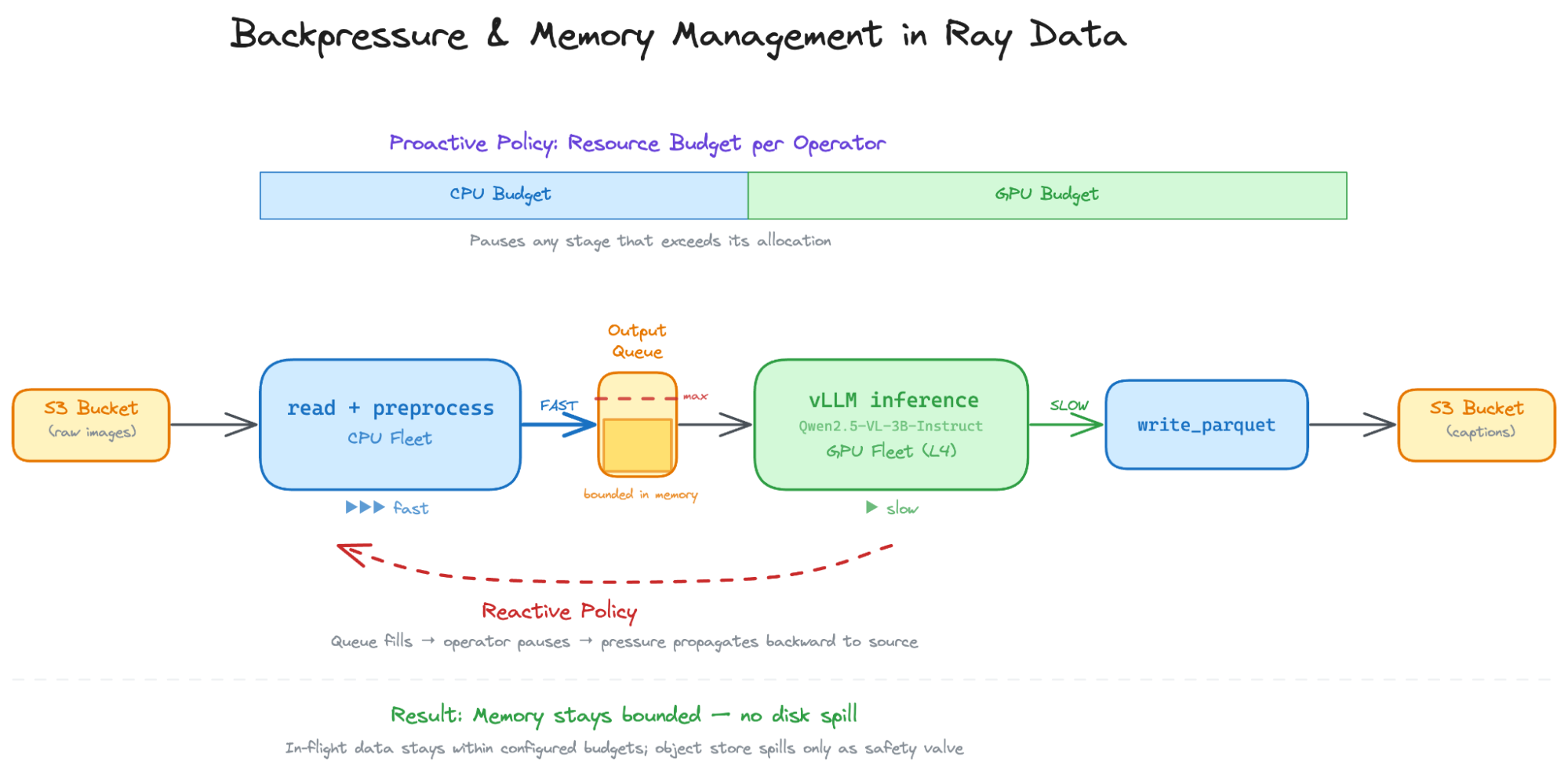

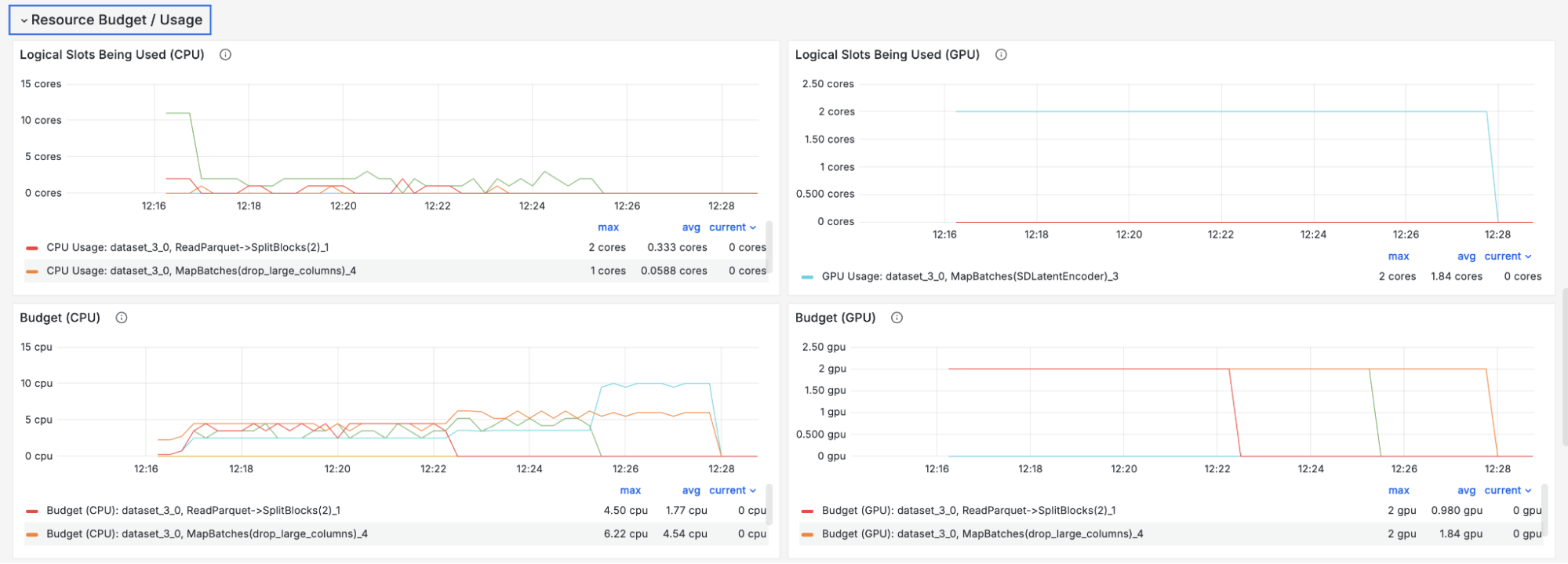
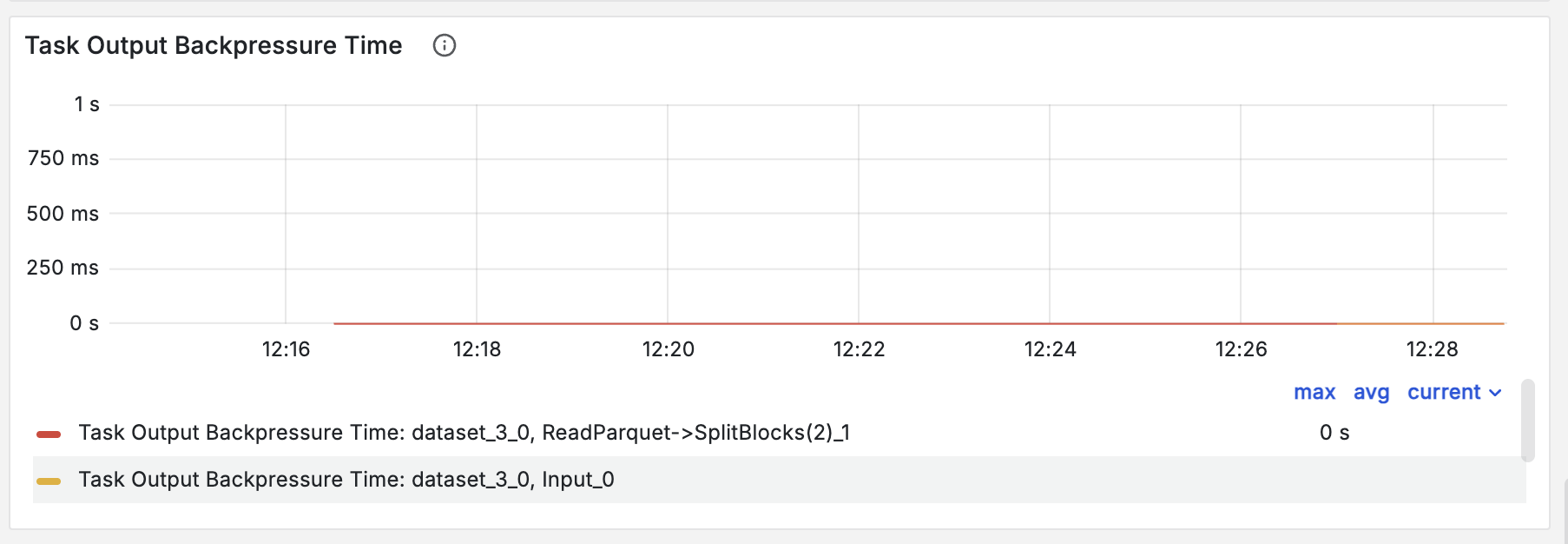
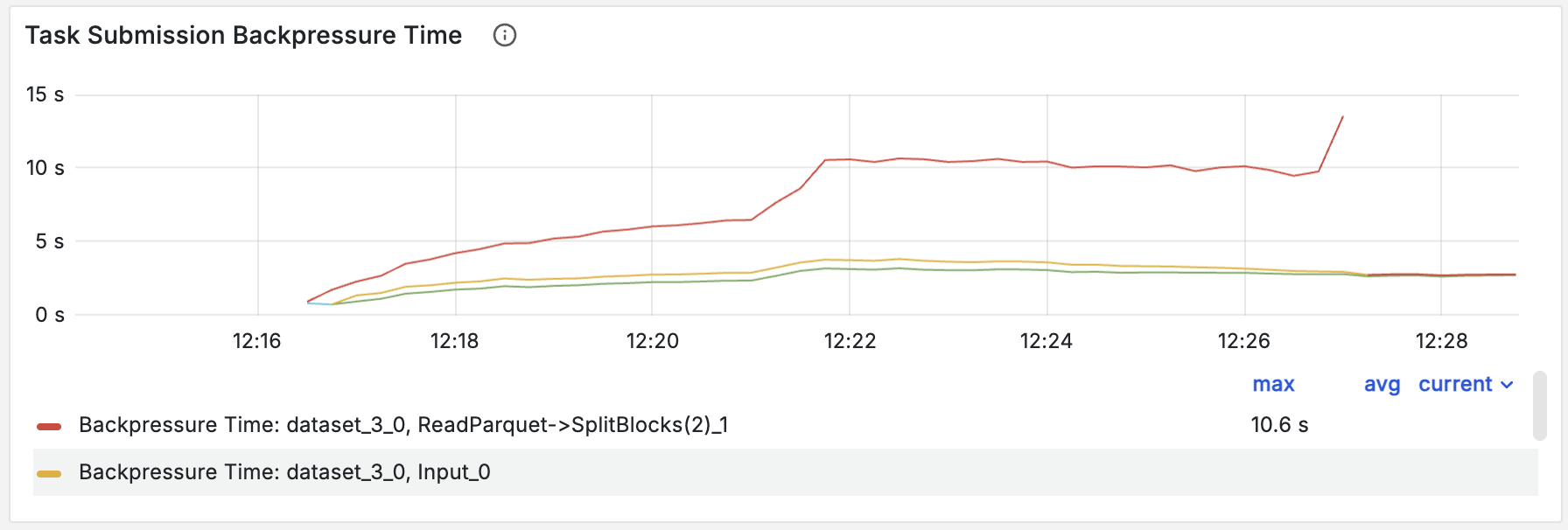
Ray Data의 동적 자원 스케줄링은 실행 중인 파이프라인의 처리량을 모니터링하여 CPU와 GPU 간 자원 예산을 실시간으로 조정한다. 전처리 병목 시 CPU 자원을 우선 배정하여 GPU가 데이터를 끊김 없이 공급받도록 유지한다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 14.수집 2026. 05. 14.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.