TL;DR
Omni-modal LLM은 오디오, 비주얼, 텍스트를 함께 이해하도록 설계되었으나 벤치마크의 성과는 시각적 단서에 의해 과대평가될 수 있다. 본 연구는 시각적 leakage를 제거하는 운영 뷰인 OmniClean을 제시하고, 이 뷰를 바탕으로 3단계 포스트 트레이닝 OmniBoost를 통해 소형 모델에서도 의미 있는 omni-modal 능력 향상을 보인다. 시각 누출에 대한 평가 제어가 있으면 omni-modal 진보의 해석이 더 명확해진다.
왜 중요한가
Omni-modal LLM은 오디오, 비주얼, 텍스트를 함께 이해하도록 설계되었으나 벤치마크의 성과는 시각적 단서에 의해 과대평가될 수 있다. 본 연구는 시각적 leakage를 제거하는 운영 뷰인 OmniClean을 제시하고, 이 뷰를 바탕으로 3단계 포스트 트레이닝 OmniBoost를 통해 소형 모델에서도 의미 있는 omni-modal 능력 향상을 보인다. 시각 누출에 대한 평가 제어가 있으면 omni-modal 진보의 해석이 더 명확해진다.
관련 Figure
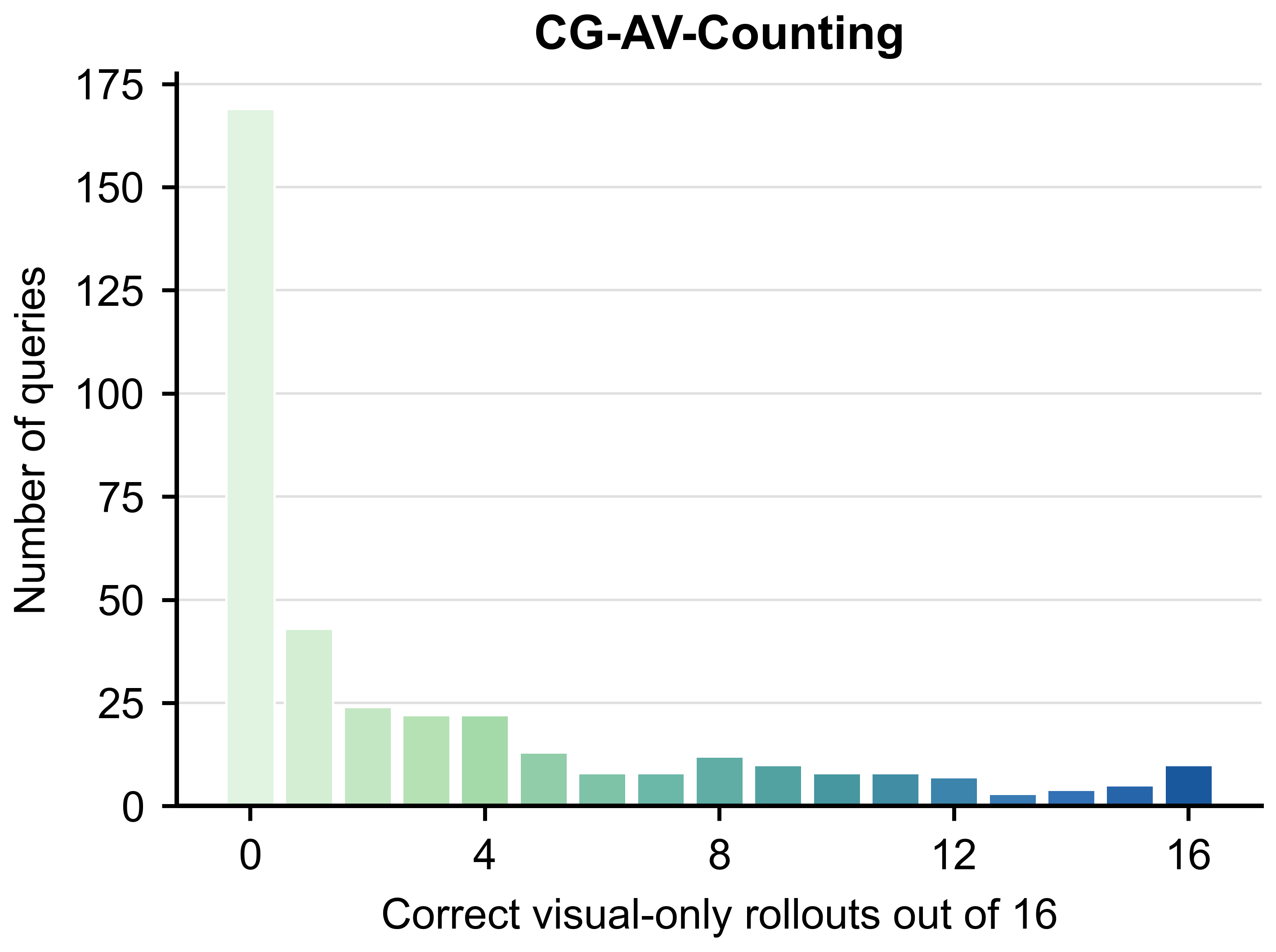
CG-AV-Counting에서 시각 입력만으로도 정답이 가능한 쿼리의 비중을 시각화한다. 이는 OmniClean의 필요성을 뒷받침하며 시각 누출이 벤치마크 해석에 미치는 영향을 정량화하는 근거를 제공한다.
CG-AV-Counting의 visual leakage 분포를 보여주는 막대 차트.
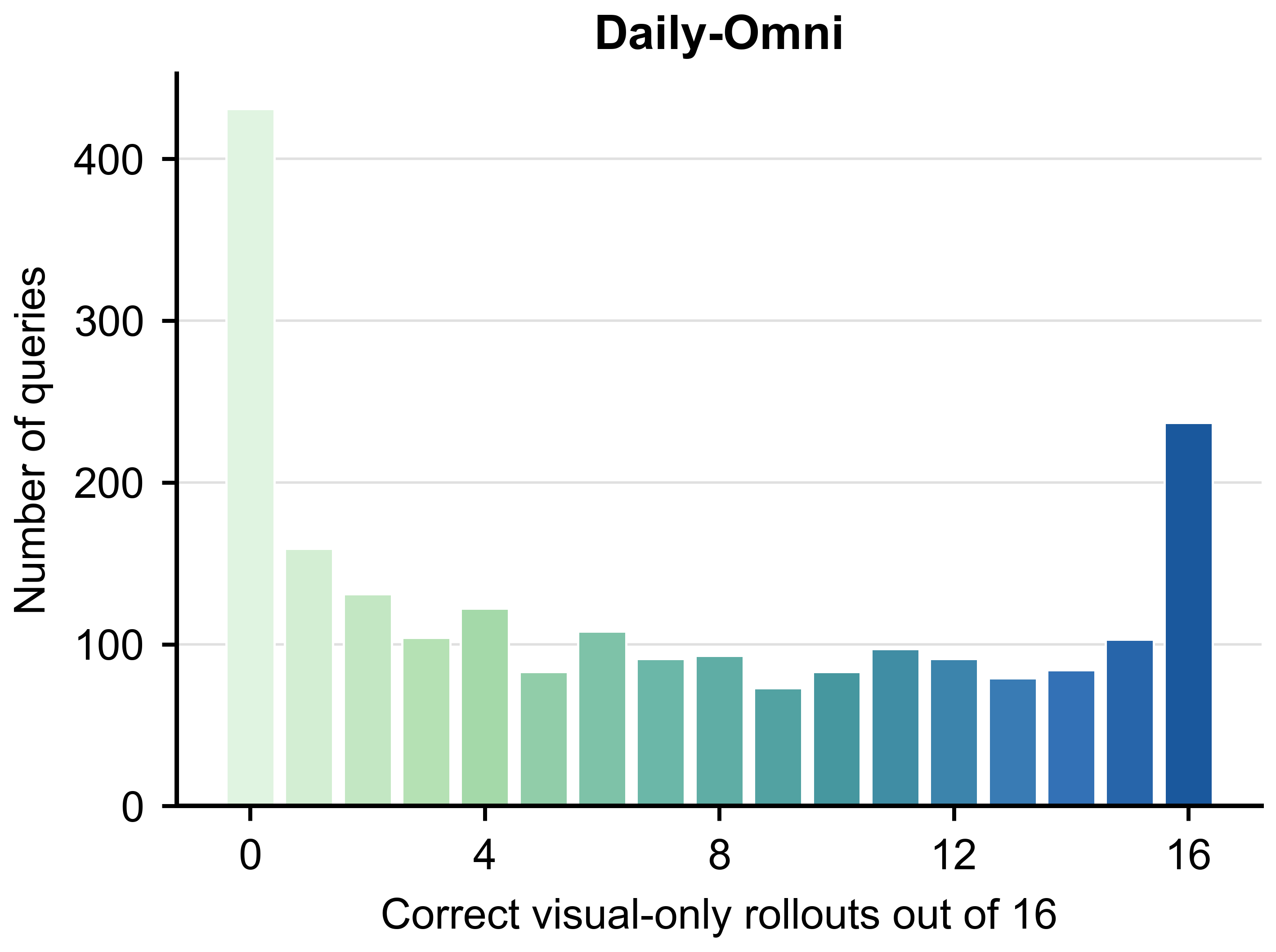
Daily-Omni에서 시각 누출의 영향도가 크며, OmniClean의 제거가 점수 분포를 크게 바꾼다는 근거를 제시한다.
Daily-Omni의 visual leakage 분포 차트.
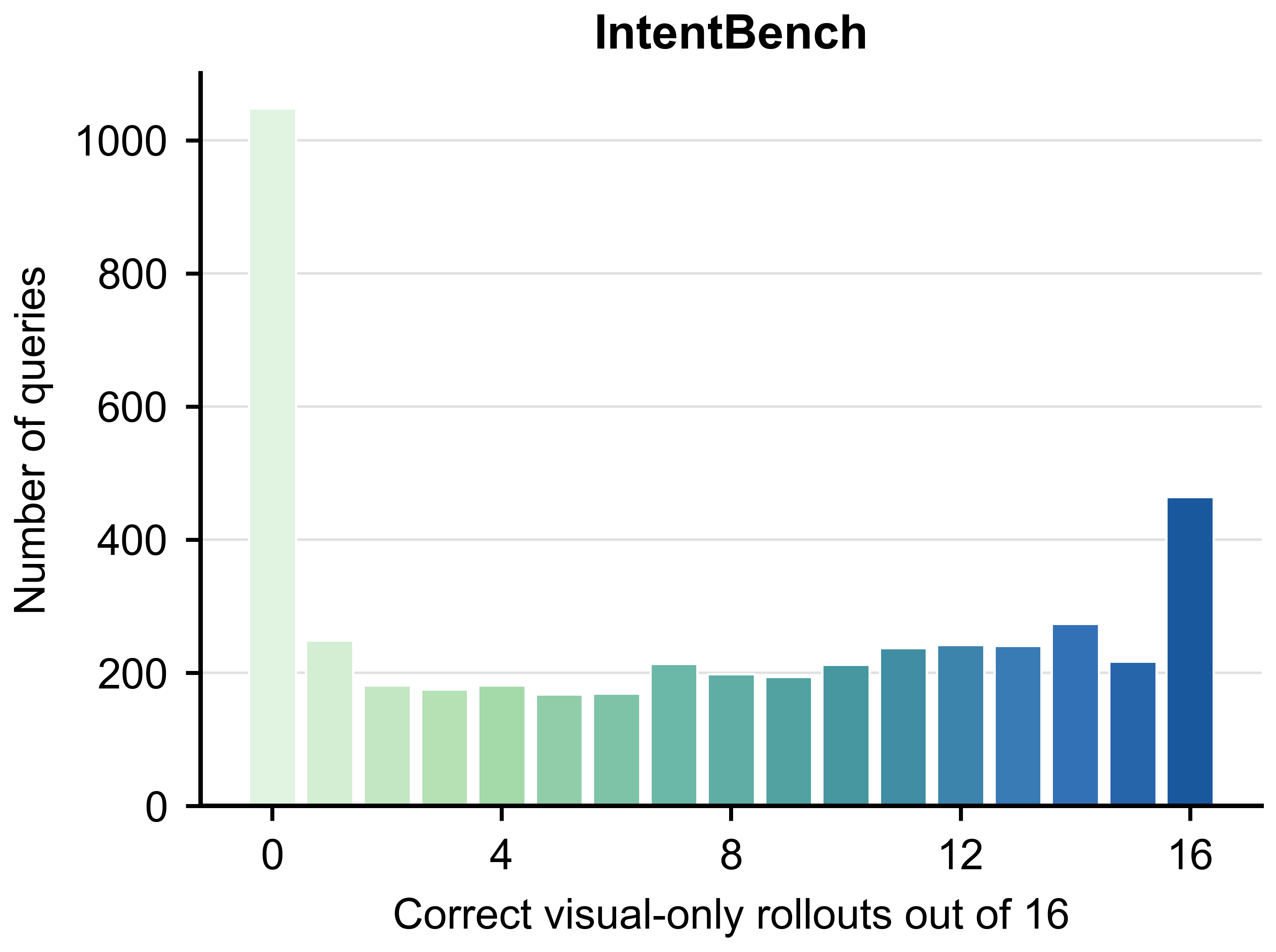
IntentBench에서도 시각 누출이 존재하며, 정합성 높은 OMNI 평가를 위해 누출 감소 필요성이 제기된다.
IntentBench의 visual leakage 분포 차트.
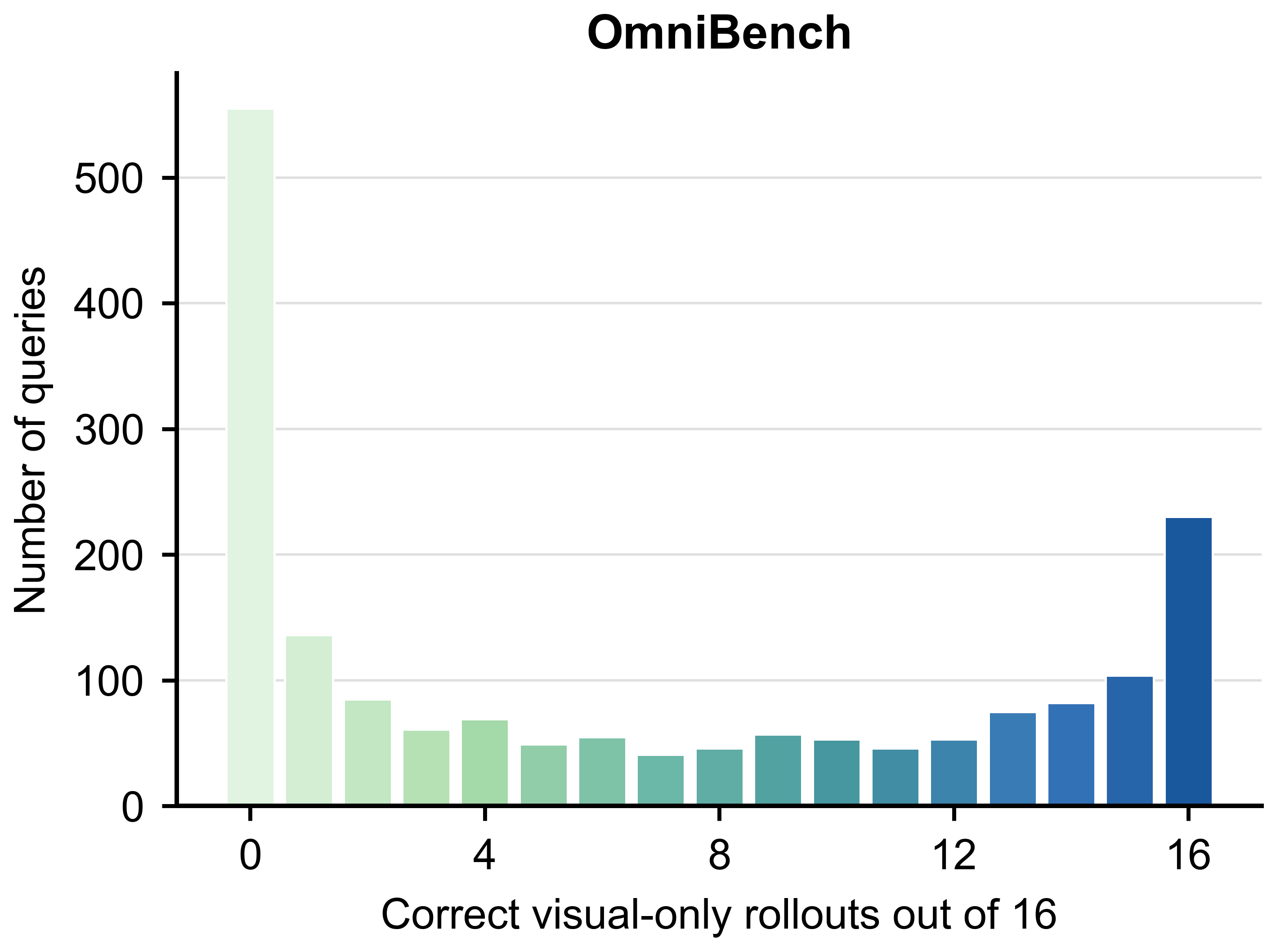
OmniBench에서도 누출 경향이 나타나며, cleaned view의 필요성을 시사한다.
OmniBench의 visual leakage 분포 차트.
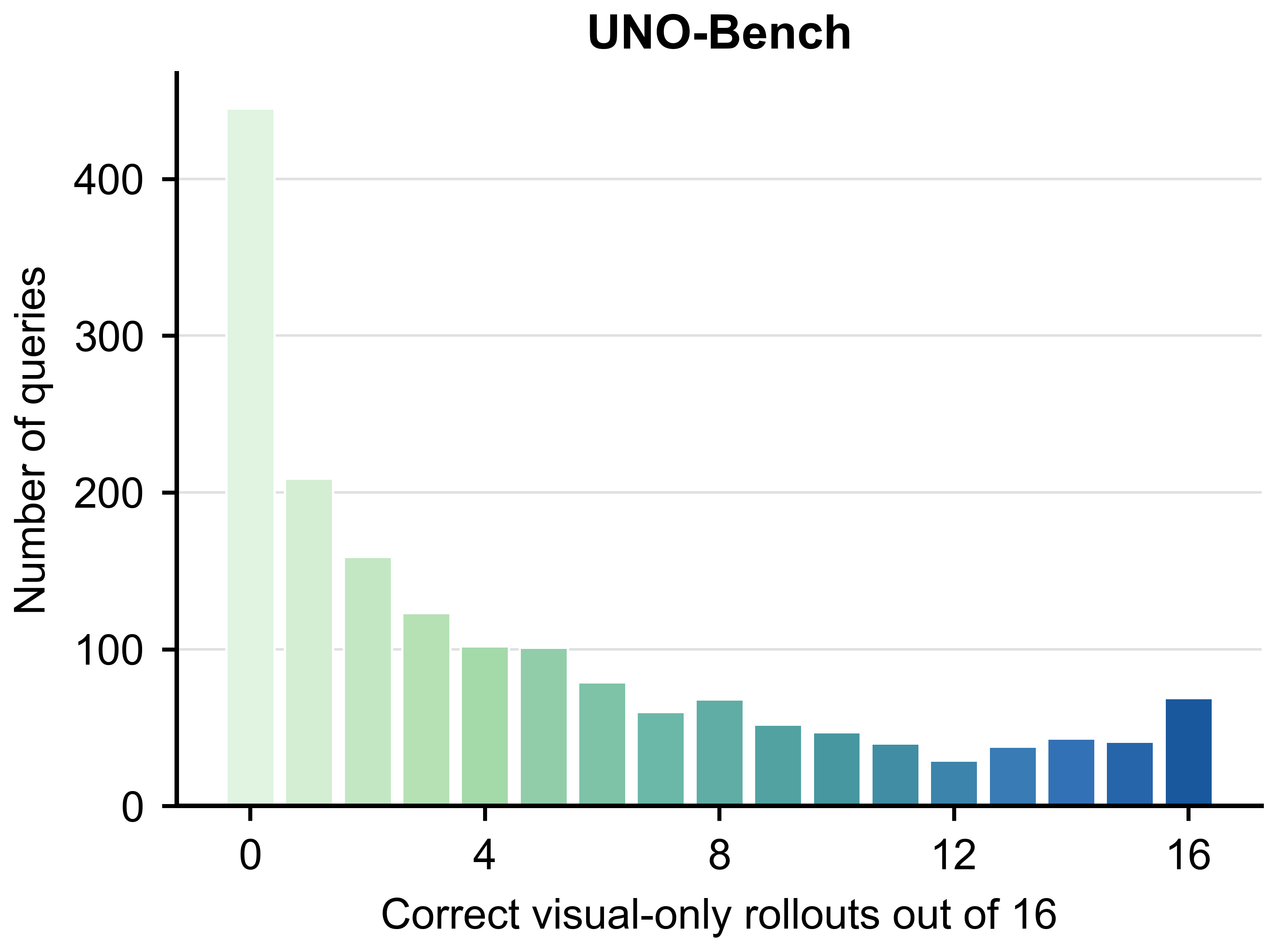
UNO-Bench에서도 시각적 누출이 확인되며, OmniClean의 필요성을 보강한다.
UNO-Bench의 visual leakage 분포 차트.
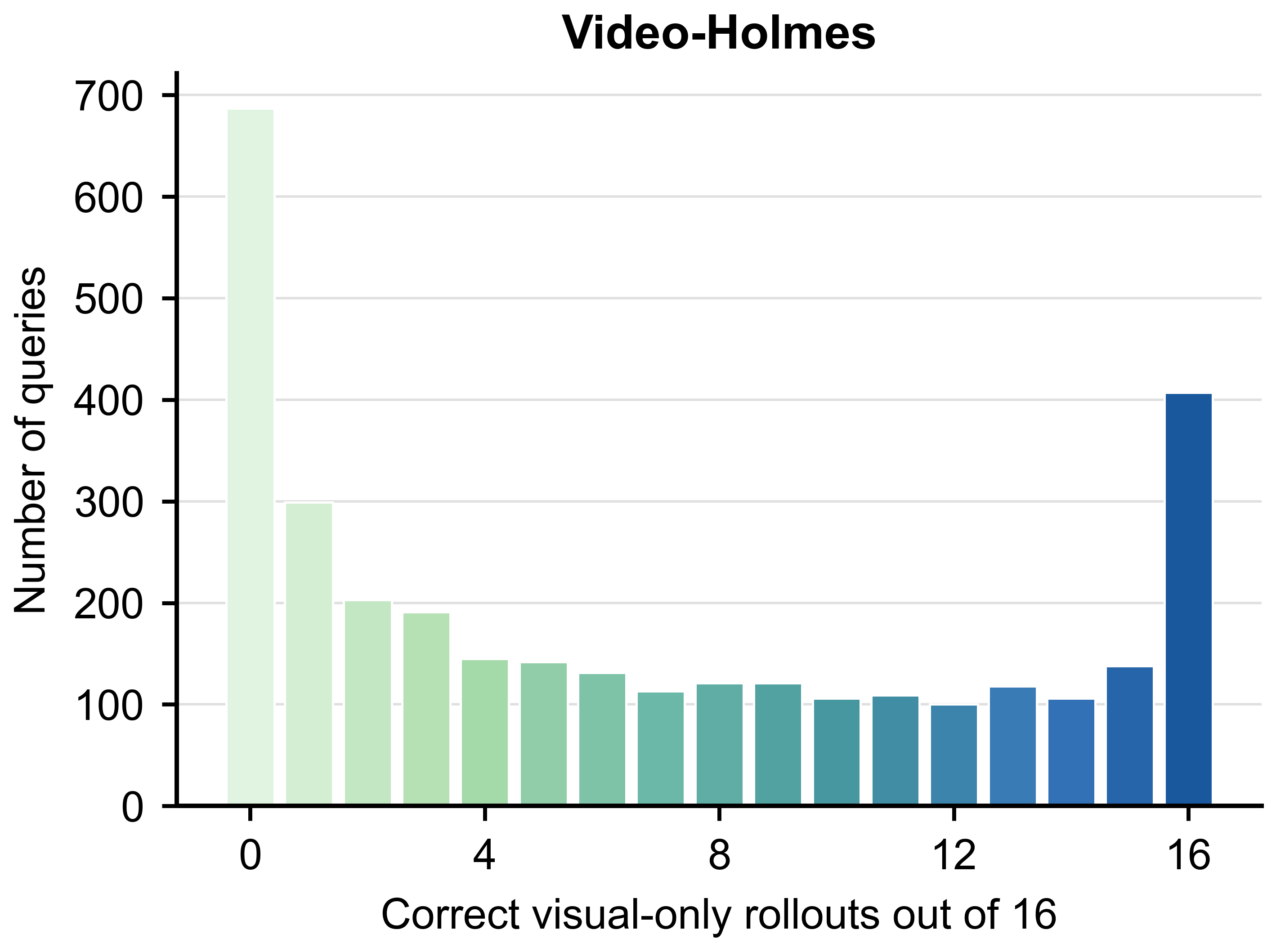
Video-Holmes에서 시각 누출의 영향이 크며, 시각-기반 해석의 한계를 드러낸다.
Video-Holmes의 visual leakage 분포 차트.
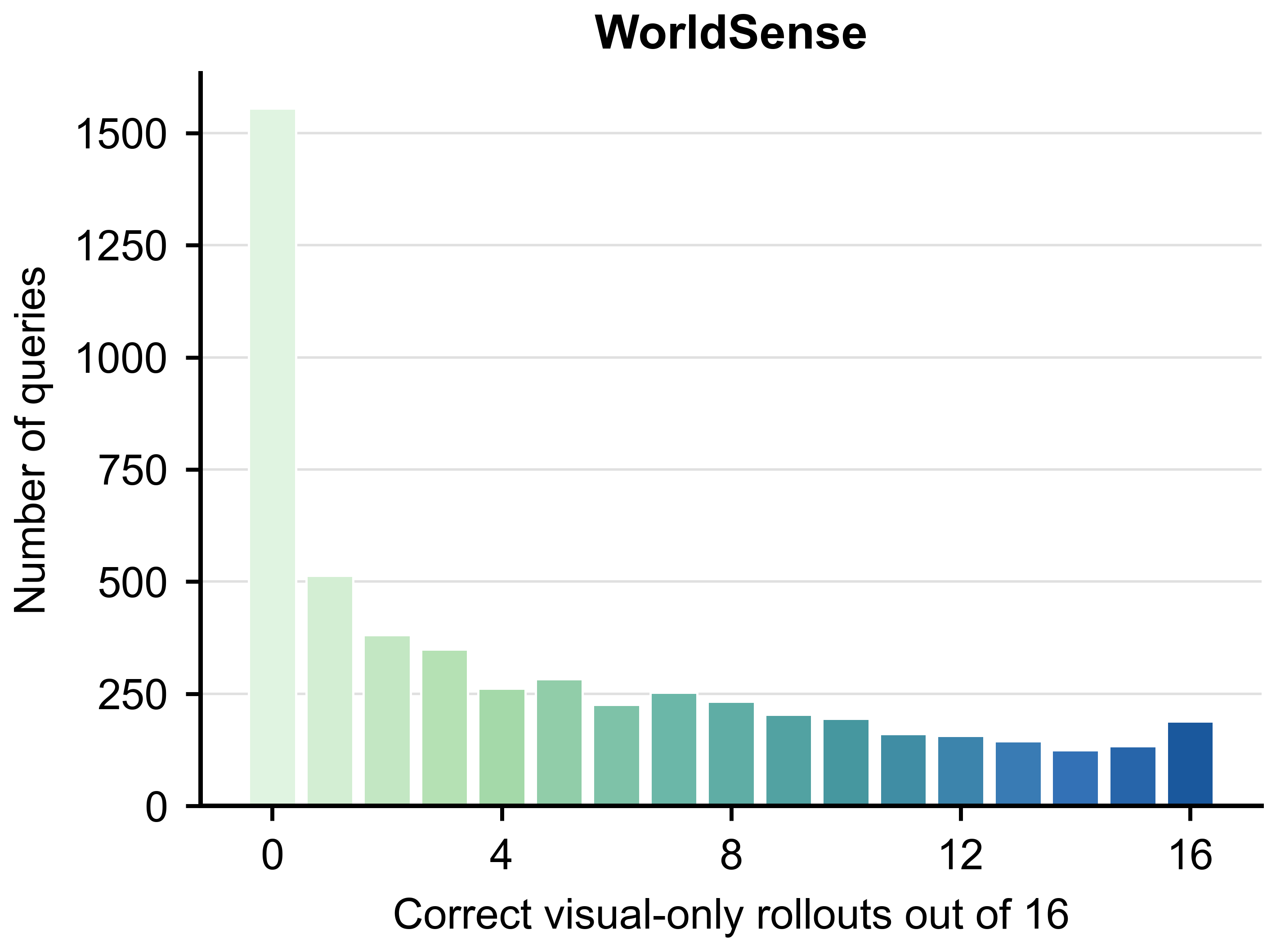
WorldSense에서 시각 누출의 영향이 확연하며, cleaned view의 중요성을 강조한다.
WorldSense의 visual leakage 분포 차트.
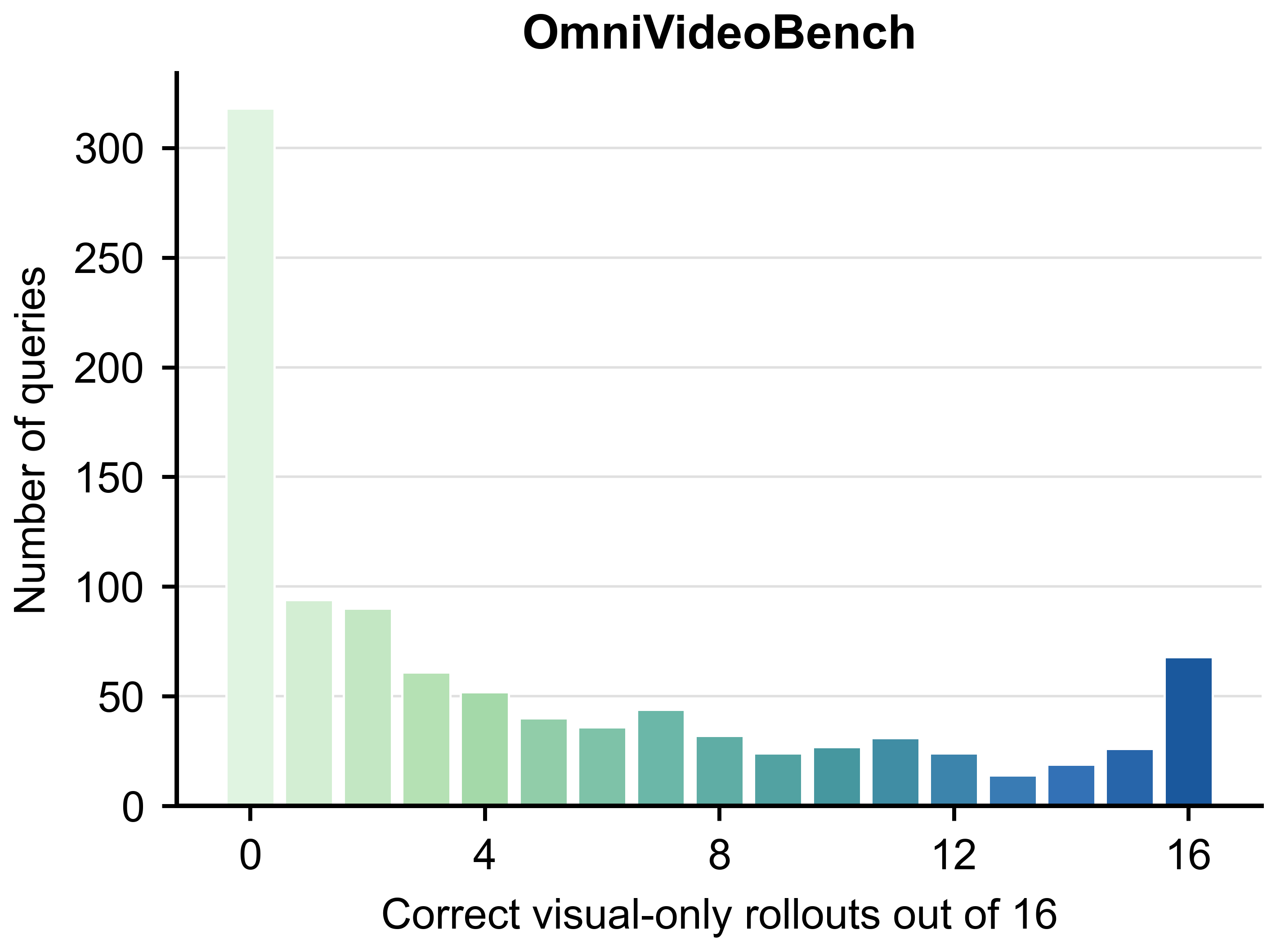
Omnivideobench에서도 누출 경향이 관찰되며, omni-modal 평가의 해석에서 시각적 편향 제거의 역할이 크다.
Omnivideobench의 visual leakage 분포 차트.
핵심 기여
OmniClean: visually debiased evaluation over nine omni benchmarks
9개 옴니 벤치마크를 시각적 프로빙으로 진단하고, 시각적으로 solvable queries를 제거해 8,551개 retained query로 구성된 visually debiased 평가 뷰를 제시한다. 이는 시각 누출을 고정 프로토콜 하에서 감소시키는 운영적 평가 뷰를 제공한다.
OmniBoost: 3단계 포스트 트레이닝 파이프라인
Qwen2.5-Omni-3B를 기점으로 mixed bi-modal SFT → mixed-modality RLVR → self-distillation SFT의 순서를 통해 omni-modal 능력을 점진적으로 향상시킨다. Stage 2가 macro 평균에서 가장 큰 향상을 주고, Stage 3가 특정 벤치에서 재분포를 유도한다.
Synthetic omni-modal queries via self-distillation
LLaVA-Video seed, Step-Audio-R1 캡션, Qwen3-VL 캡션, gpt-oss-120b entity scaffolds로 구성된 합성 쿼리를 만들어 hard-matchable 타깃으로 distillation한다. 이는 외부 강한 omni-teacher 없이도 omni-modal 습득에 기여한다.
벤치마크별 효과 패턴과 시각 누출의 영향 분석
Stage 2는 Daily-Omni, IntentBench, OmniVideoBench, UNO-Bench 등에서 강한 매크로 이득을 주고, Stage 3는 AV-Odyssey, Daily-Omni, IntentBench, OmniVideoBench, UNO-Bench에서 강점을 재배치한다. 따라서 데이터 선택에 따른 효과 차이가 존재한다.
OmniClean 데이터 셋의 공개와 해석적 가치
OmniClean 최종 cleaned 평가 뷰를 공개하여 시각 누출에 대한 통제된 평가가 재현 가능하게 되었고, 새로운 옴니 모델 평가 설계에 활용 가능하다.
핵심 아이디어 이해하기
출발점: 옴니-모달 모델은 음향/시각/언어를 함께 이해하지만, 벤치마크에 노출된 시각 단서가 학습의 주된 요인이 되어 실제 omni-modal 융합 능력이 과대평가될 수 있다. 해결 원리: Visual leakage를 탐지하는 visual-only probing으로 OmniClean을 구성하고, 이를 바탕으로 OmniBoost의 세 단계 포스트 트레이닝을 설계한다. 변화점: Stage 2 RLVR가 가장 큰 매크로 향상을 주고, Stage 3 self-distillation은 특정 벤치에서 강점을 재배치하며, 3B 모델도 외부 omni-teacher 없이 대형 오픈 소스 대비 경쟁력을 얻는다.
방법론
전체 접근: OmniClean은 9개 벤치마크를 대상으로 쿼리별로 이미지/비디오를 유지하고 오디오를 제외한 시각 입력만으로 정답 가능 여부를 16회 롤아웃으로 확인한다. 시각-only probing의 pass@16 규칙으로 쿼리를 제거/유지해 시각적 누출의 규모를 산출한다. 예시: Daily-Omni, IntentBench, OmniBench 등에서 시각 누출의 정도가 다르게 나타난다. OmniBoost는 동일 계열의 3단계로 구성되며, Stage 1은 Balanced Mixed Bi-modal SFT(4개 소스: audio-text, image-text, video-text, text), Stage 2는 RLVR으로 omni-grounded reasoning 최적화, Stage 3은 self-distillation SFT로 synthetic Query를 활용한 이유 추론 패턴을 강화한다. 합성 쿼리 구성은 seed 비디오(LLaVA-Video), segment-level 캡션, entity 그래프를 연결하고 gpt-oss-120b로 질문-답변 쌍을 생성한다. F1-F3 품질 관리 흐름으로 롤아웃 신뢰성을 보장한다. 학습 파라미터로 RLVR은 1200-step, rollouts 16, 업데이트는 32 쿼리, 최대 생성 길이 4K, learning rate 1e-6이다. 평가 지표는 OmniClean의 macro 평균/쿼리 가중 평균이며, 샘플링 및 데이터 비율은 Stage 간 비교를 위해 고정된다.
주요 결과
메인 벤치마크 결과: OmniBoost의 Macro Avg는 Stage 1 26.49에서 Stage 2 31.43으로 상승했고, Stage 3은 31.03으로 나타났다. Stage 2가 매크로 평균에서 가장 큰 향상을 보였고, Stage 3은 쿼리 가중 평균에서 가장 강하게 작용했다(Stage 3 32.15). Stage별 벤치마크별 효과 분포: Stage 2는 CG-AV-Counting, OmniBench, Video-Holmes, WorldSense에서 강세를 보였고, Stage 3은 AV-Odyssey, Daily-Omni, IntentBench, OmniVideoBench, UNO-Bench에서 강점을 보였다. 합성 데이터의 피드백은 Stage 3에서 특정 데이터셋에서 더 큰 상승을 견인했다. 원문 비교에서 보면 Stage 2가 여전히 강한 벤치가 있으며, Stage 3는 데이터의 크기에 따라 가중 평균에서 더 강한 편이다.
기술 상세
구조: OmniClean은 9개 옴니 벤치마크를 대상으로 visual-only probing을 수행하고, 쿼리별로 시각 입력만으로 정답 가능 여부를 확인해 필터링한다. 수학적 기저: Cross-Entropy Loss는 일반적으로 정답 분포와 예측 분포 간의 차이를 통해 가중치를 업데이트하고, RLVR은 정책(policy) 업데이트를 통해 보상을 최대화하도록 설계된다. 합성Query 구성은 20초 분할 영상, 엔티티 그래프, 캡션을 결합하고 gpt-oss-120b가 hard-matchable 답안을 생성하도록 한다. F1–F3 품질 관리 단계에서 rollouts의 난이도/일관성 등을 평가해 최종 distillation 데이터로 선별한다.
한계점
이 연구는 Qwen2.5-Omni-3B 라인에 한정되어 있으며, 다른 베이스 모델에서의 일반화는 추가 검증이 필요하다. OmniClean은 제거된 쿼리에 대한 보정된 해석을 제공하지만 여전히 특정 벤치마크의 구조에 의존한다. Augmentation 및 데이터 구성의 선택에 따라 벤치마크별 결과가 달라질 수 있다. 원문은 3B 라인에서의 효과를 중심으로 다루므로 대형 모델에 대한 직접적 일반화는 추가 연구 필요.
실무 활용
OmniClean으로 시각 누출을 제어한 평가 체계가 제시되었고, 소형 모델인 3B 계열에서도 staged post-training으로 omni-modal 능력을 크게 향상할 수 있음을 보였다.
- 새로운 옴니모달 모델의 누출 민감도 평가에 OmniClean을 사용한다.
- OmniBoost 스타일의 포스트 트레이닝 파이프라인으로 작은 모델의 omni-modal 성능 향상을 시도한다.
- 합성 쿼리 생성 파이프라인을 통해 외부 omni-teacher 없이도 강화된 다중 모달 추론 데이터를 확보한다.
- 벤치마크 비교 시 visual leakage를 보정한 해석적 평가를 적용한다.
코드 공개 여부: 미확인
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.