TL;DR
llama-dash는 로컬 LLM 추론 환경을 위한 관측 가능하고 정책 제어 가능한 AI 게이트웨이입니다. 이 도구는 llama-swap과 llama.cpp를 기반으로 모델 상태, 요청 기록, API 키, 라우팅 규칙, 프록시 메트릭을 통합 관리합니다. OpenAI 및 Anthropic 호환 클라이언트를 지원하며, 로컬 모델과 외부 API를 투명하게 프록시하여 사용량 추적과 비용 최적화를 수행합니다. GPU 모니터링, Prometheus 메트릭, SQLite 기반 요청 로깅을 통해 운영 가시성을 확보합니다.
대상 독자
로컬 LLM을 프로덕션 환경이나 팀 단위로 운영하는 개발자
의미 / 영향
로컬 LLM 인프라의 운영 복잡성을 낮추고, 기업용 수준의 관리 기능을 제공하여 로컬 AI 모델의 실무 도입을 가속화함.
섹션별 상세
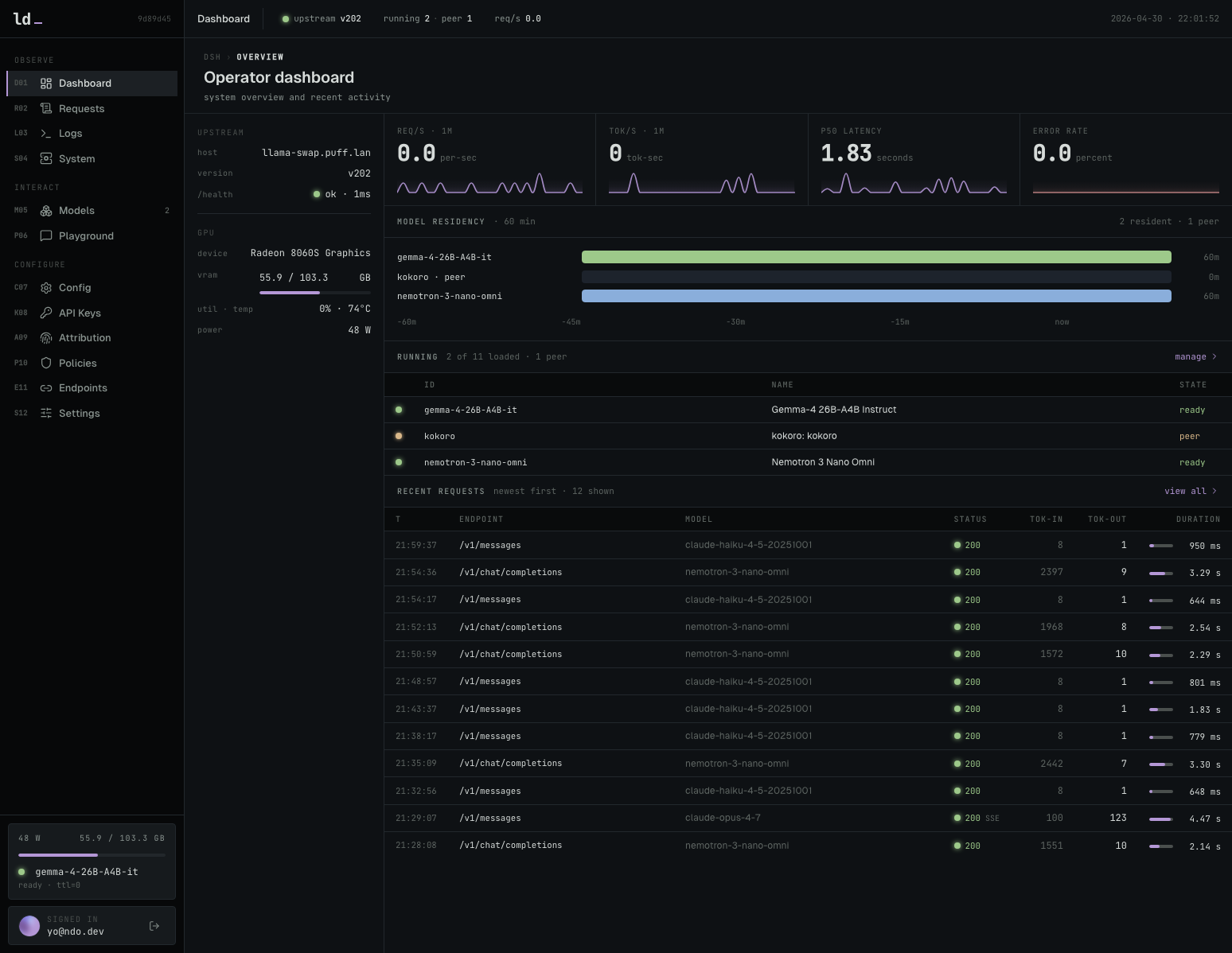
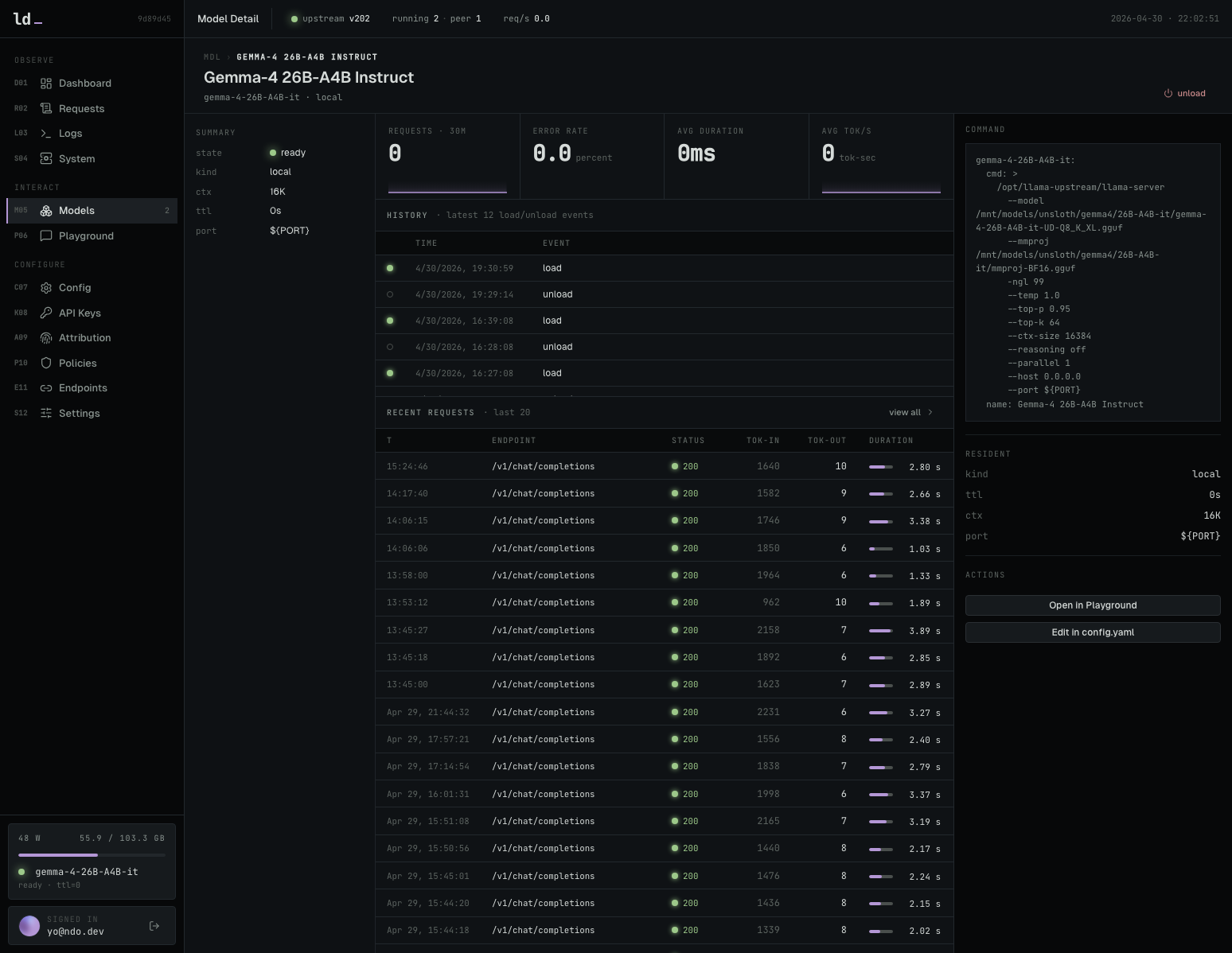
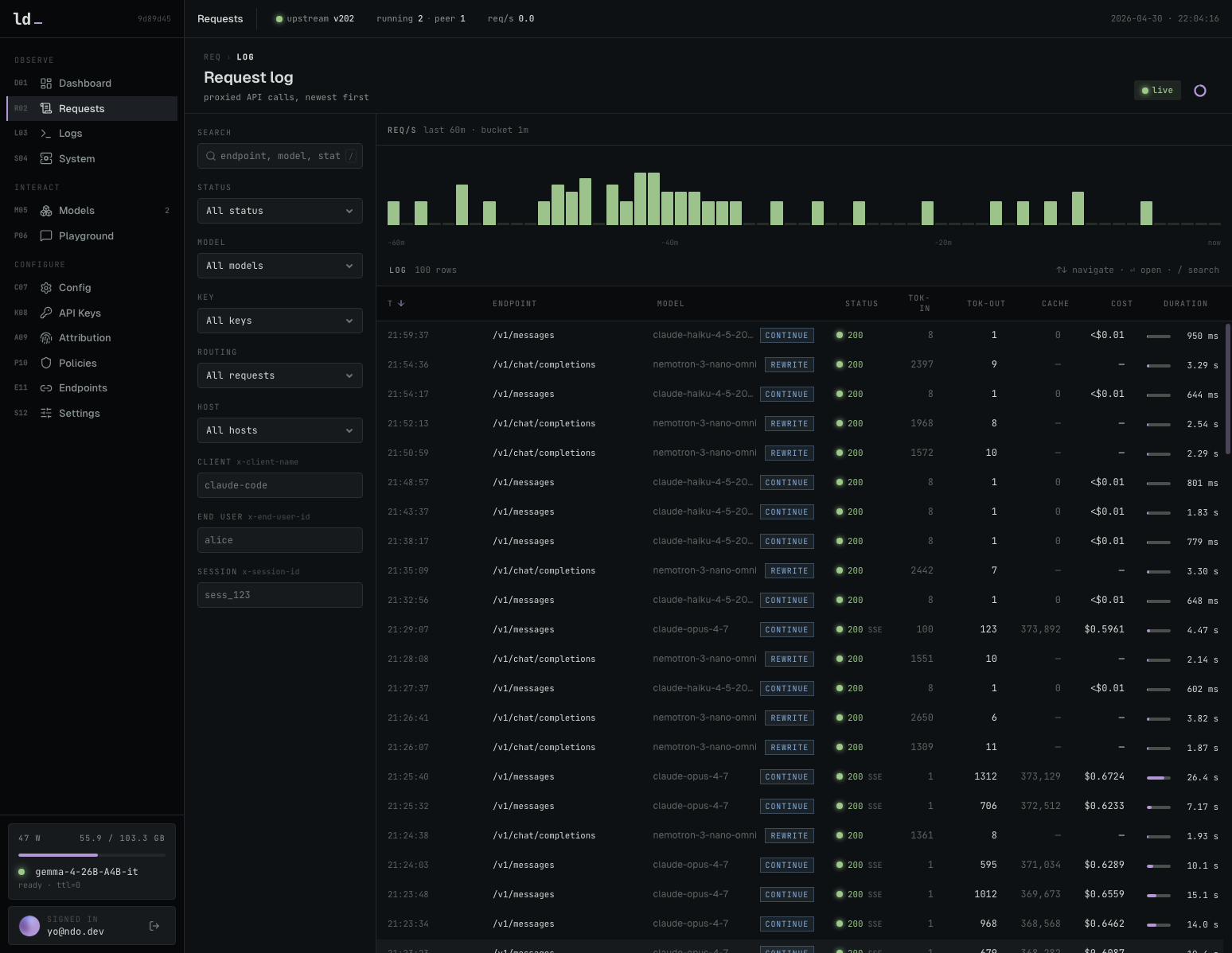
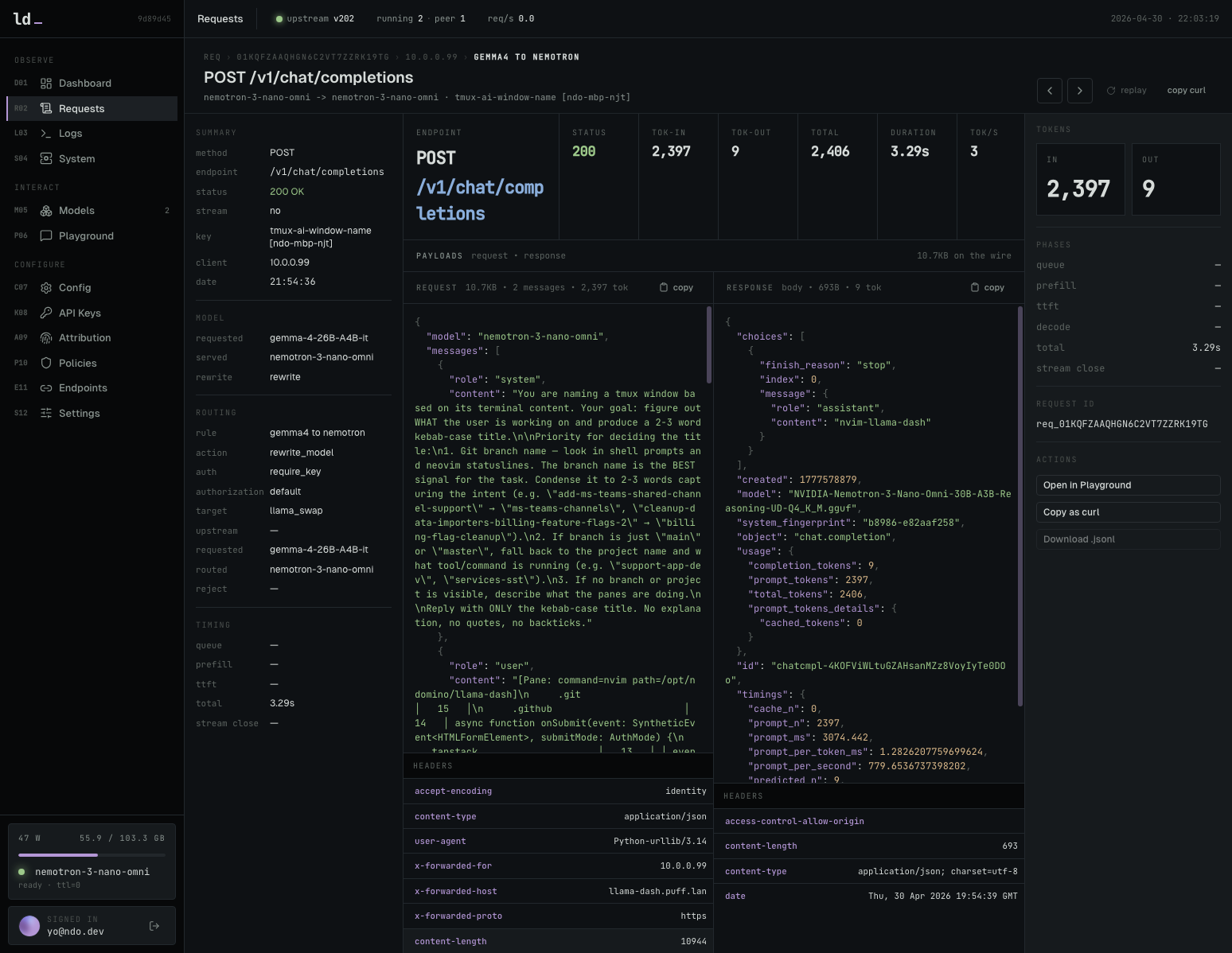
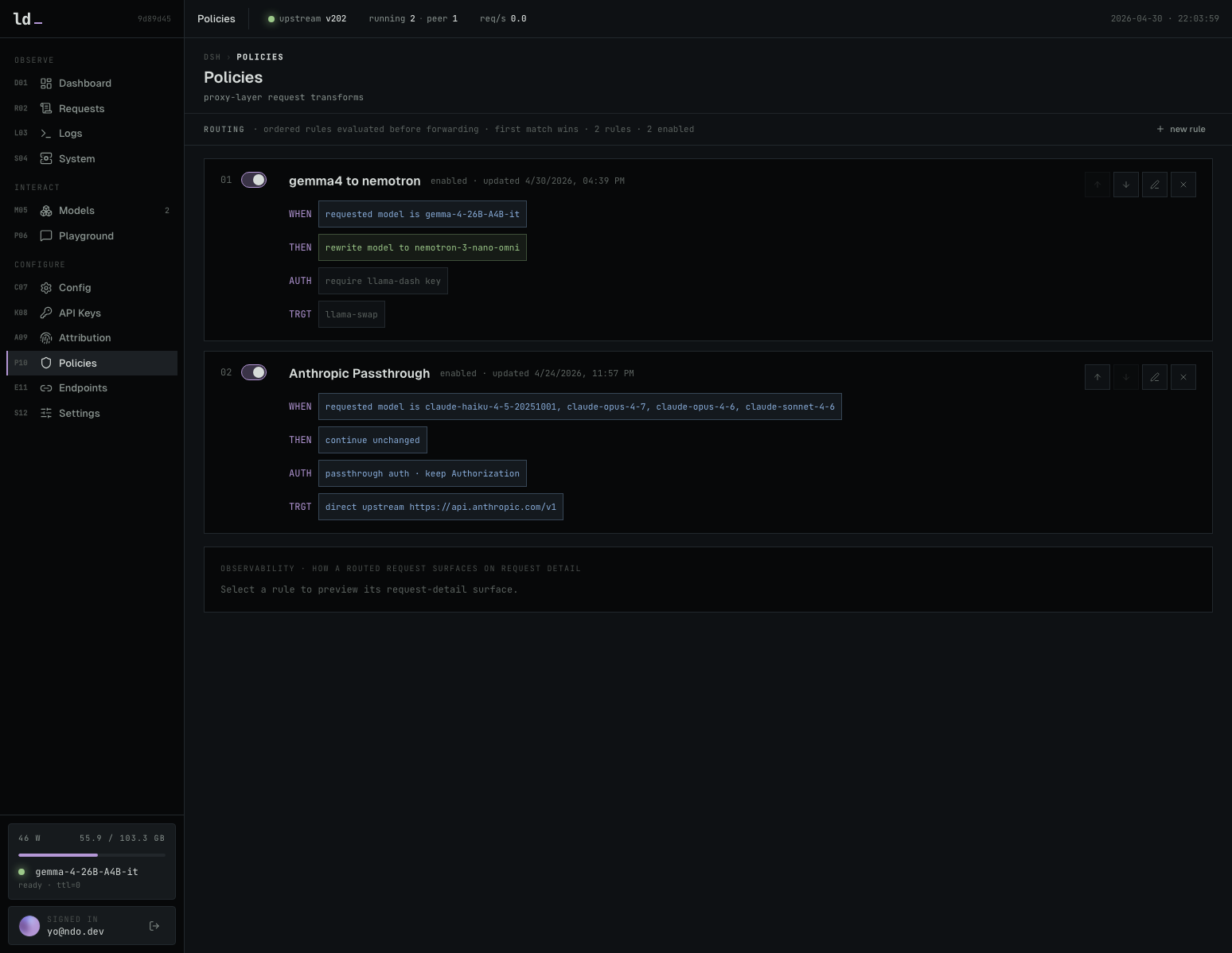
docker compose -f docker-compose.nvidia.yaml up -dNVIDIA GPU 환경에서 llama-dash와 llama-swap을 실행하는 명령어
이미지 분석
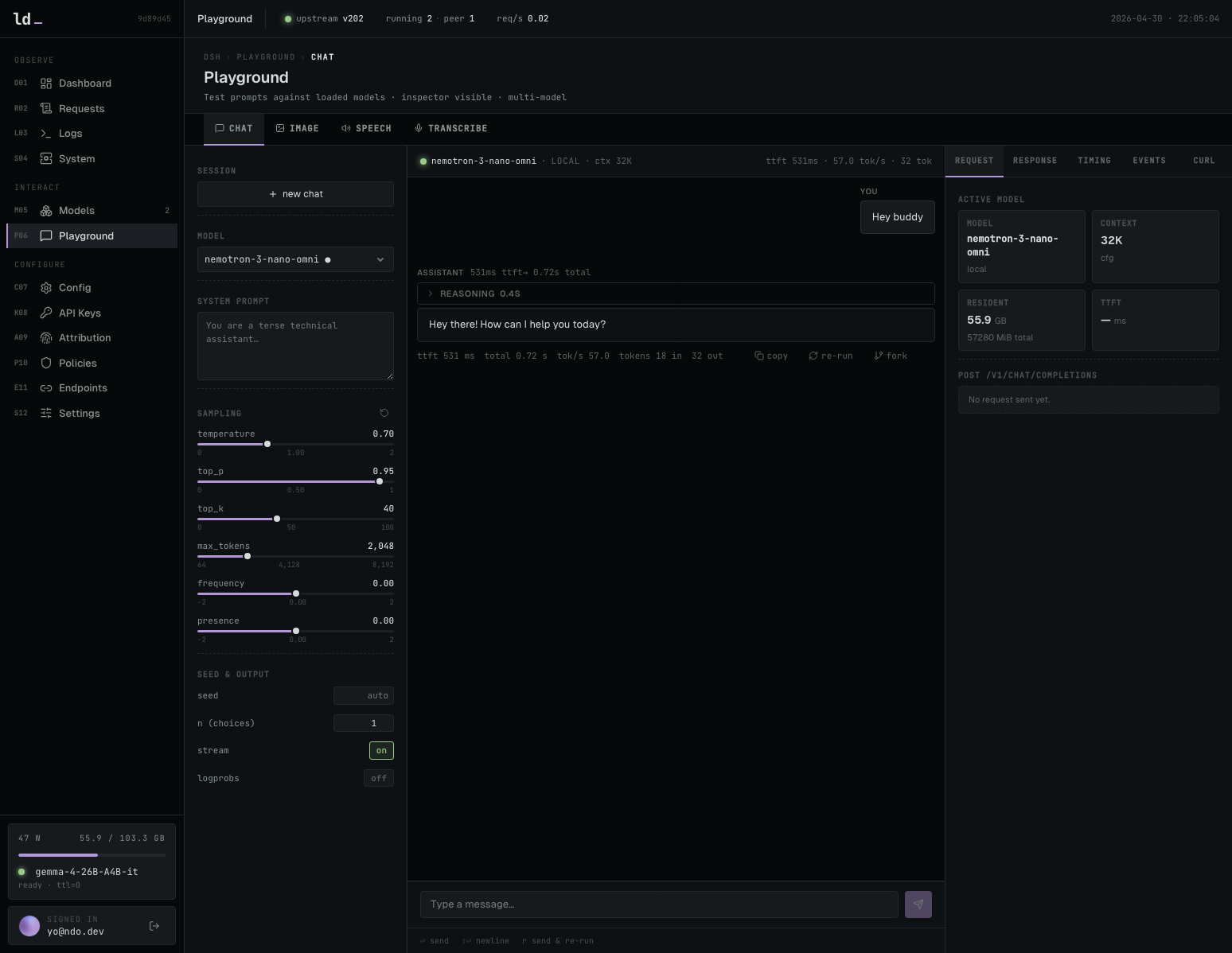
모델의 응답 품질을 즉석에서 검증하고 프롬프트 설정을 조정할 수 있는 도구입니다.
로컬 모델을 테스트할 수 있는 Playground 채팅 인터페이스입니다.
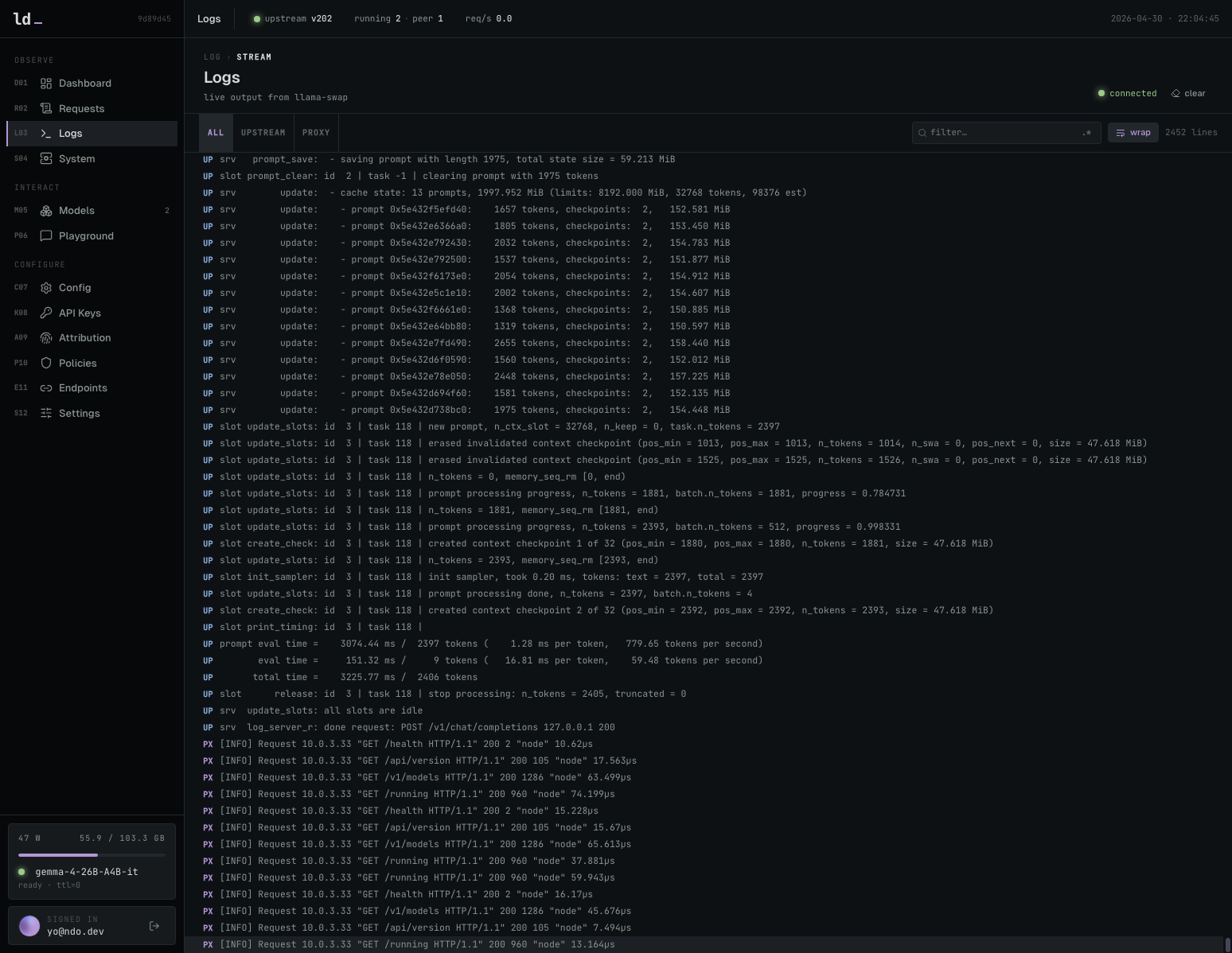
프록시 및 업스트림 서버의 로그를 통합하여 문제 발생 시 원인을 파악합니다.
시스템 로그를 실시간으로 확인할 수 있는 로그 뷰어입니다.
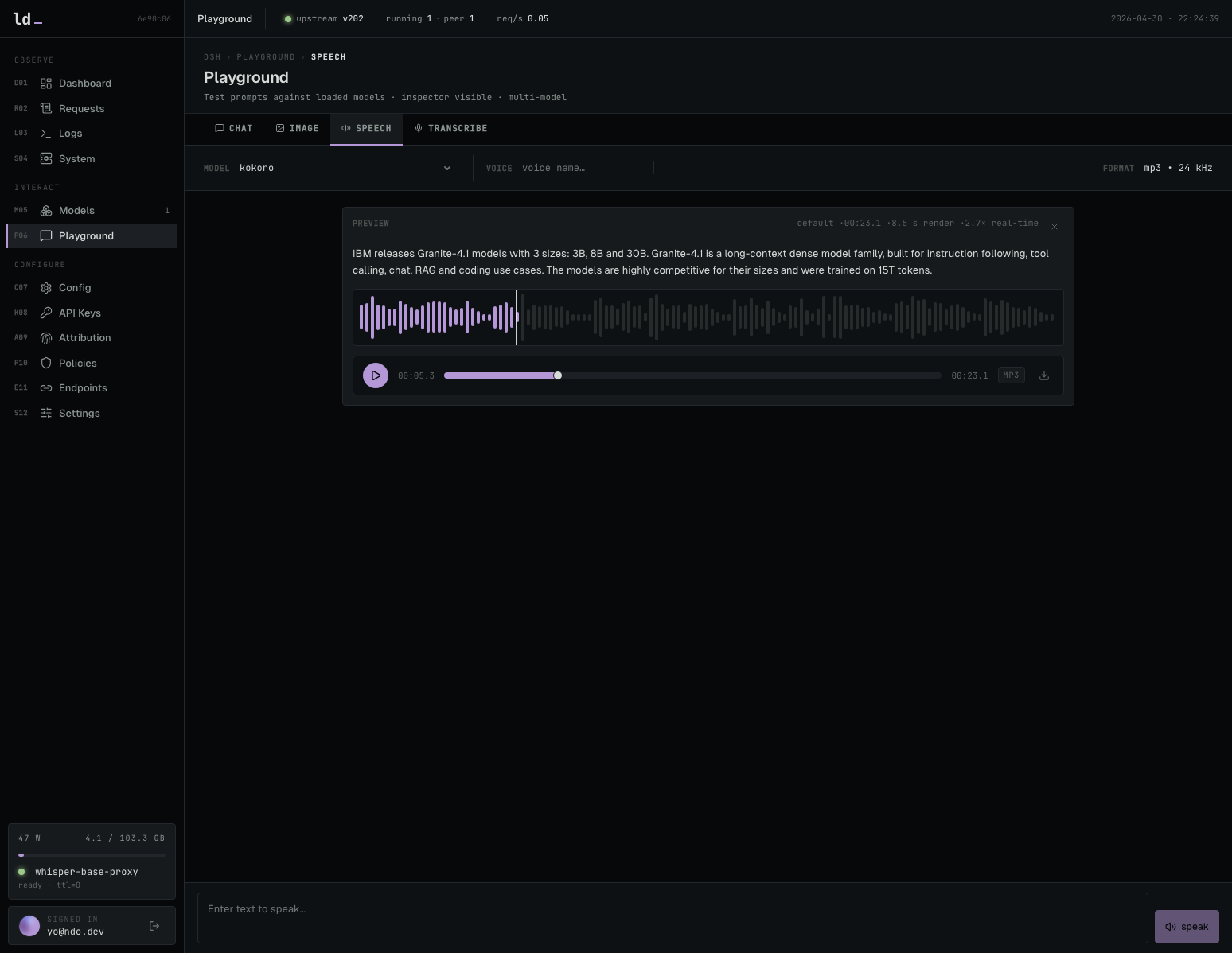
텍스트-음성 변환 등 멀티모달 기능을 로컬에서 테스트할 수 있음을 보여줍니다.
음성 및 오디오 관련 기능을 테스트하는 Playground 화면입니다.
용어 해설
- AI Gateway
- — LLM API 요청을 중계하고 보안, 로깅, 속도 제한, 라우팅 등의 정책을 적용하는 중간 계층입니다. 여러 모델 서비스 간의 트래픽을 통합 관리하고 가시성을 확보하는 데 사용됩니다.
- Inference Engine
- — 학습된 모델을 로드하여 실제 입력 데이터에 대한 예측이나 생성을 수행하는 소프트웨어 런타임입니다. 모델의 실행 속도와 효율성을 결정하는 핵심 요소입니다.
- SSE
- — 서버에서 클라이언트로 실시간 데이터를 단방향으로 스트리밍하는 웹 기술입니다. LLM의 토큰 생성 과정을 실시간으로 화면에 출력할 때 주로 사용됩니다.
- Prometheus
- — 시스템 및 서비스의 메트릭을 수집하고 모니터링하는 오픈소스 도구입니다. 시계열 데이터를 저장하고 쿼리하여 시스템 상태를 시각화하는 데 활용됩니다.
- SQLite
- — 별도의 서버 프로세스 없이 파일 기반으로 작동하는 경량 관계형 데이터베이스입니다. 설정이 간편하여 로컬 애플리케이션의 데이터 저장소로 널리 사용됩니다.
코드 예제
{
"env": {
"ANTHROPIC_BASE_URL": "http://:3000"
}
}Claude Code 클라이언트에서 llama-dash를 프록시로 사용하기 위한 설정 예시
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.