이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
Virtue Foundation은 전 세계 72개국 의료 시설 데이터를 통합하여 의료진과 자원봉사 기회를 매칭하는 플랫폼을 운영한다. 파편화된 웹 데이터를 처리하기 위해 OpenAI GPT 모델을 활용한 단계별 정보 추출 파이프라인을 구축했다. Databricks와 Apache Spark를 통해 2,500만 개 이상의 웹 페이지를 병렬 처리하며, Splink를 사용하여 데이터 중복을 제거했다. 최근에는 LangGraph 기반의 멀티 에이전트 아키텍처를 도입하여 자연어 질의를 통한 데이터 분석 기능을 프로토타입으로 구현했다.
배경
Apache Spark, LLM 파이프라인 설계, 데이터 엔지니어링 기초
대상 독자
데이터 엔지니어, AI 솔루션 아키텍트, 프로덕션 환경에서 LLM 파이프라인을 구축하는 개발자
의미 / 영향
이 사례는 대규모 비정형 데이터를 LLM으로 처리할 때 파이프라인 최적화와 에이전트 아키텍처가 필수적임을 보여준다. 특히 데이터 처리 병목을 해결하기 위한 분산 처리 엔진의 활용은 프로덕션 수준의 AI 시스템 구축에 중요한 기준이 된다.
섹션별 상세
Overture Maps와 Bright Data를 통해 수집된 데이터를 OpenAI GPT 모델로 분류 및 추출한다. 전체 작업을 단계별로 세분화하여 토큰 소비를 최적화하고 정밀도를 높였다.
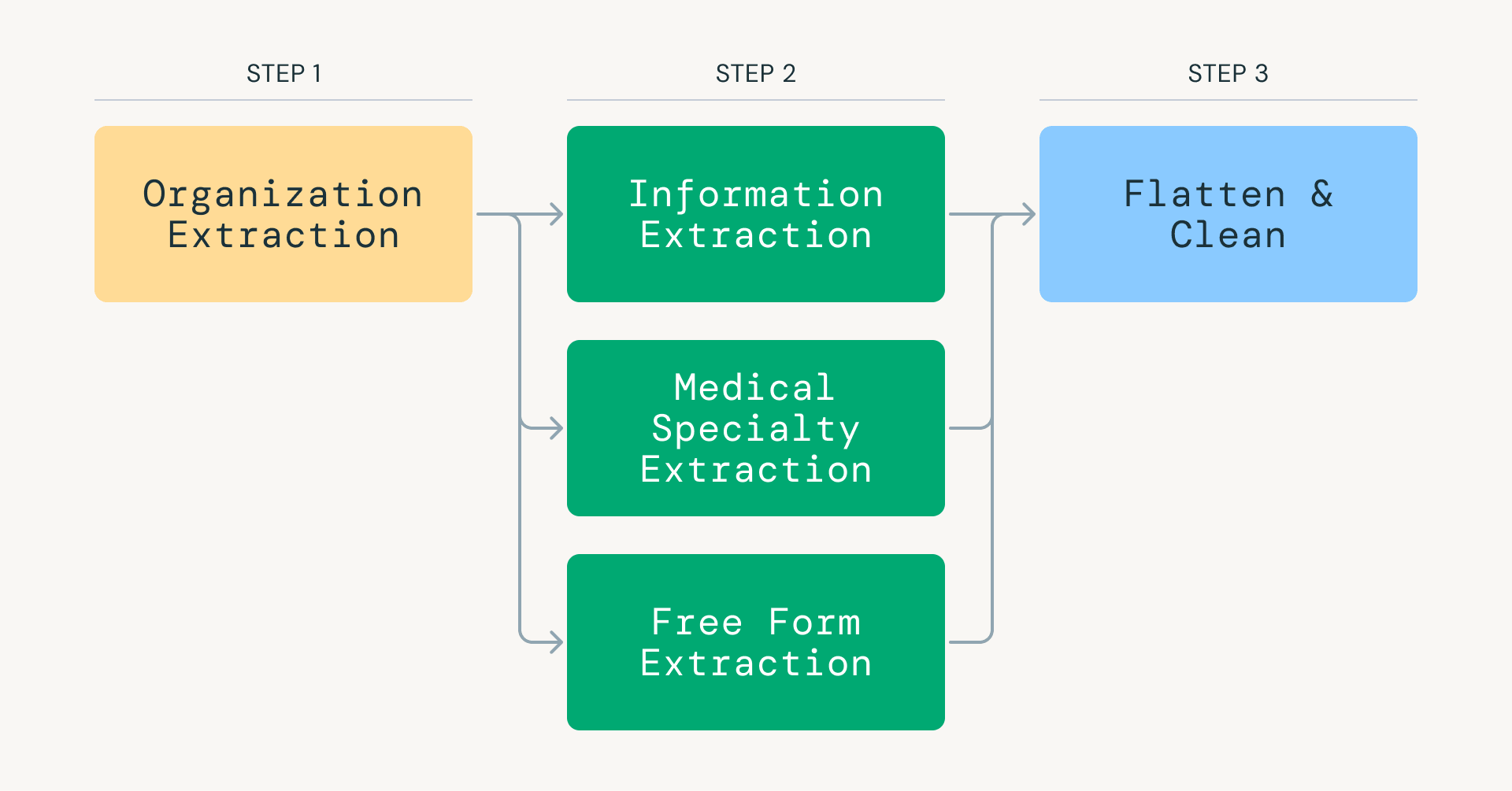
Apache Spark와 Lakeflow Jobs를 사용하여 2,500만 개 이상의 웹 페이지를 병렬 처리한다. 데이터 처리 상태를 추적하는 체크포인트 시스템으로 파이프라인 안정성을 확보했다.
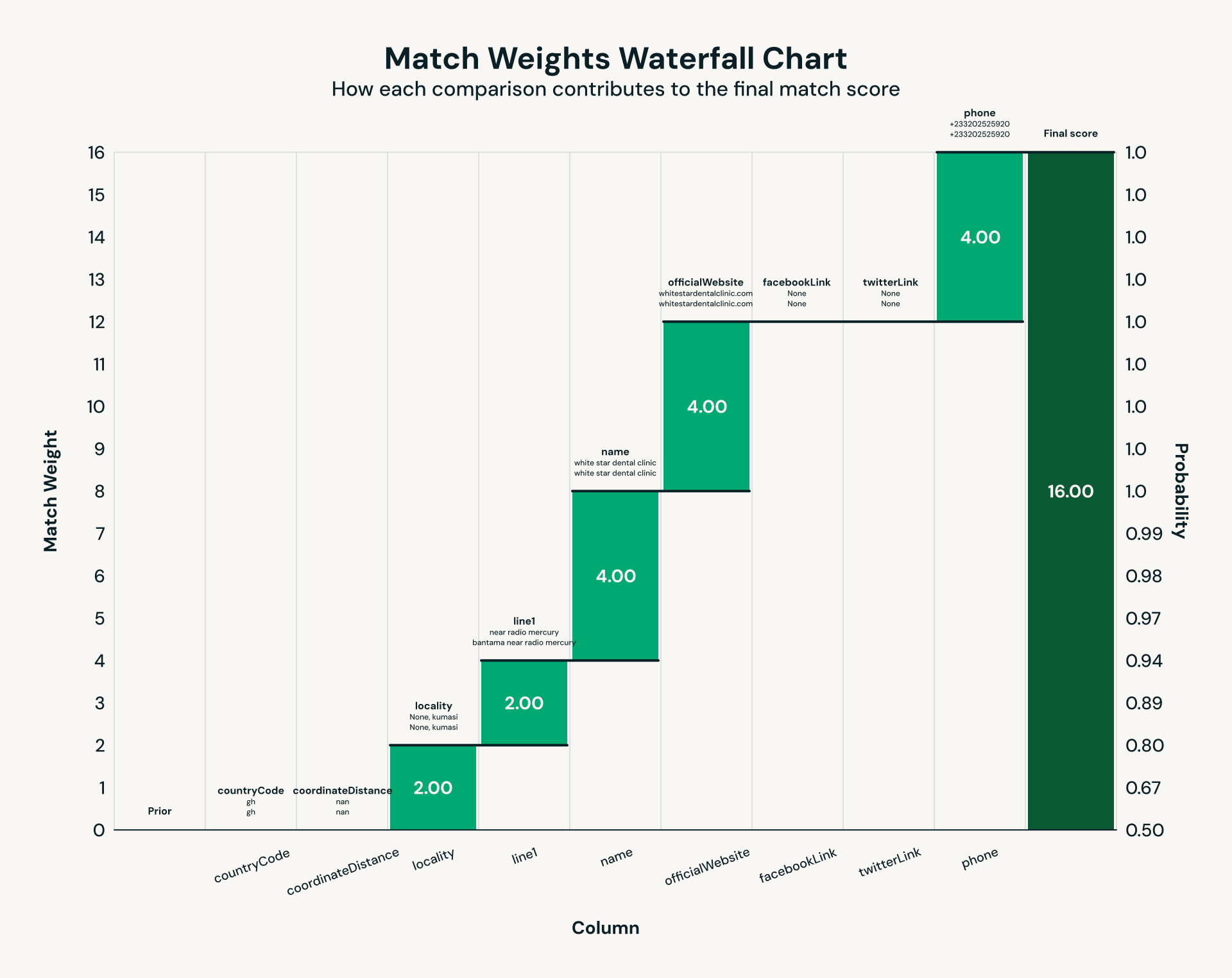
Splink를 사용하여 데이터 소스 간 중복된 의료 시설 정보를 통합한다. Photon 엔진을 적용하여 데이터 파티션 처리 시간을 30분에서 2분으로 15배 단축했다.
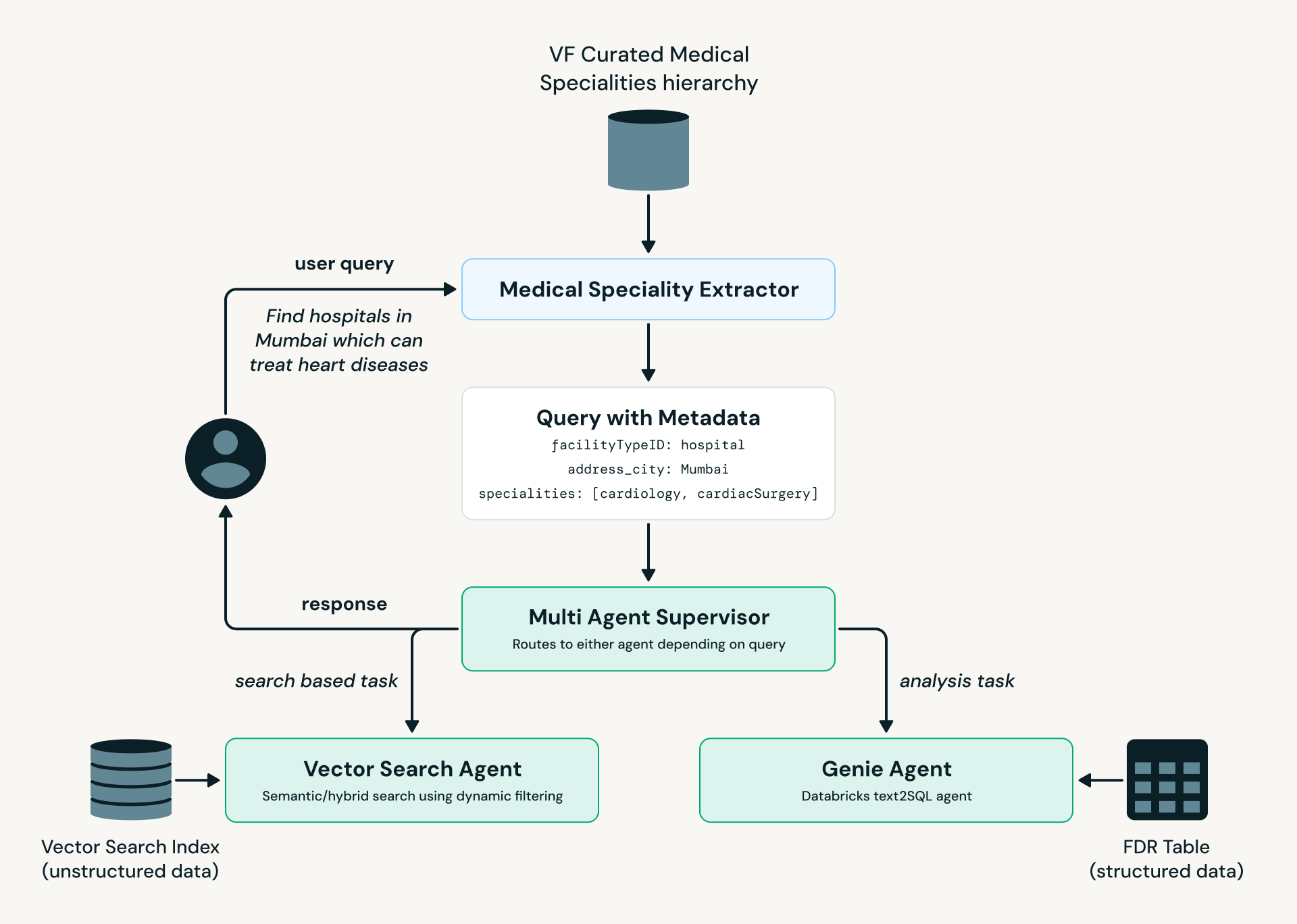
LangGraph를 활용한 에이전트 아키텍처가 자연어 질의를 처리한다. 질의 의도에 따라 Vector Search Agent와 Genie Agent로 작업을 라우팅하여 구조화된 데이터와 비정형 데이터를 동시에 분석한다.
용어 해설
- Entity Resolution
- — 서로 다른 데이터 소스에서 동일한 실체를 나타내는 레코드를 식별하고 통합하는 과정. 데이터 중복을 제거하고 단일한 권위 있는 레코드를 생성하는 데 필수적이다.
- Probabilistic Record Linkage
- — 데이터 필드 간의 유사도를 가중치 기반으로 계산하여 두 레코드가 동일한 실체일 확률을 산출하는 기법. 명확한 식별자가 없는 데이터셋에서 엔티티를 통합할 때 사용된다.
- Multi-Agent Architecture
- — 특정 작업을 수행하기 위해 여러 개의 AI 에이전트가 협력하거나 역할을 분담하는 구조. 복잡한 질의를 의도에 따라 적절한 에이전트로 라우팅하여 처리 효율을 높인다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 20.수집 2026. 05. 20.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.