TL;DR
Amazon SageMaker AI와 vLLM을 결합하여 실시간 음성 인식 애플리케이션을 구축하는 아키텍처를 제공한다. 기존 요청-응답 방식의 지연 문제를 해결하기 위해 SageMaker AI의 양방향 스트리밍과 vLLM의 Realtime API를 활용한다. 클라이언트와 모델 컨테이너 간의 WebSocket 연결을 통해 오디오 데이터와 전사 텍스트를 동시에 스트리밍한다. 이 솔루션은 Voxtral-Mini-4B-Realtime-2602 모델을 사용하여 실시간 음성-텍스트 변환 서비스를 구현한다.
배경
AWS 계정 및 SageMaker AI 권한, Docker 환경, Python 3.12+, Voxtral-Mini-4B-Realtime-2602 모델 접근 권한
대상 독자
실시간 음성 인식 애플리케이션을 개발하는 AI 엔지니어
의미 / 영향
이 아키텍처는 실시간 음성 인식 서비스의 지연 시간을 획기적으로 줄여 음성 에이전트나 콜센터 분석과 같은 고성능 서비스 구현을 가능하게 한다. 특히 SageMaker AI의 관리형 인프라와 vLLM의 유연한 모델 서빙을 결합하여 프로덕션 환경에서의 운영 효율성을 높인다.
섹션별 상세
FROM public.ecr.aws/deep-learning-containers/vllm:0.17.1-gpu-py312-cu129-ubuntu22.04-sagemaker-v1.0-soci LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true WORKDIR /opt/ml/code COPY requirements.txt . RUN pip install --upgrade --no-cache-dir -r requirements.txt COPY app.py . COPY sagemaker-entrypoint.sh entrypoint.sh RUN chmod +x entrypoint.sh ENTRYPOINT ["./entrypoint.sh"]SageMaker AI 양방향 스트리밍을 활성화하는 Dockerfile 설정
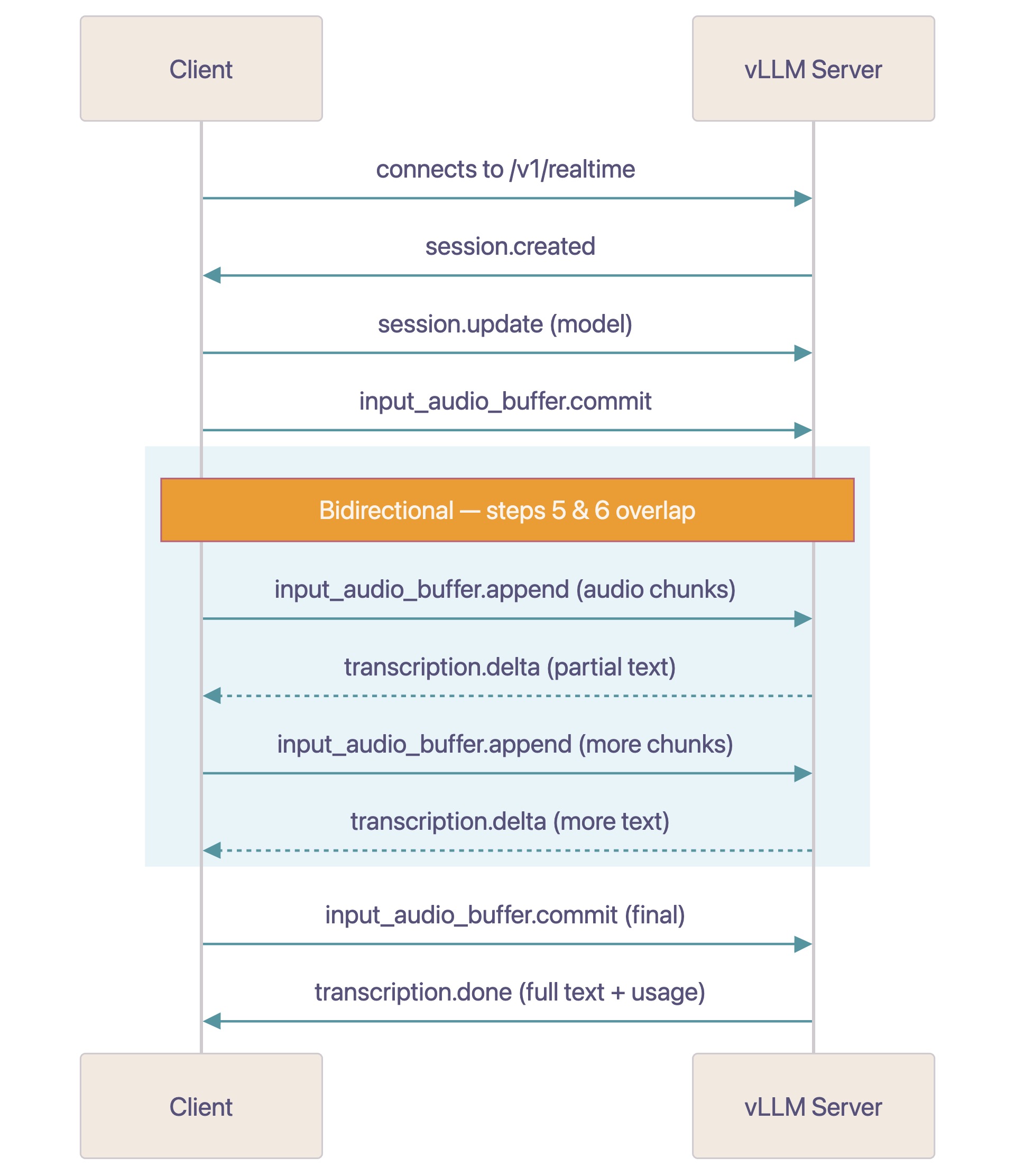
VLLM_WS_URL = "ws://localhost:8081/v1/realtime" @app.websocket("/invocations-bidirectional-stream") async def websocket_bridge(sm_ws: WebSocket): await sm_ws.accept() async with websockets.connect(VLLM_WS_URL) as vllm_ws: async def sm_to_vllm(): while True: message = await sm_ws.receive() if "text" in message and message["text"]: await vllm_ws.send(message["text"]) elif "bytes" in message and message["bytes"]: await vllm_ws.send(message["bytes"].decode("utf-8")) async def vllm_to_sm(): async for msg in vllm_ws: if isinstance(msg, str): await sm_ws.send_text(msg) elif isinstance(msg, bytes): await sm_ws.send_bytes(msg) await asyncio.gather(sm_to_vllm(), vllm_to_sm())SageMaker AI와 vLLM 간의 WebSocket 통신을 중계하는 FastAPI 브릿지 코드
- SageMaker AI bidirectional streaming infrastructure acts as a transparent bridge between HTTP/2 event streams and WebSocket. — Conclusion section
voxtral_model = Model.create( model_name=model_name, primary_container=ContainerDefinition( image=inference_image, model_data_source=ModelDataSource( s3_data_source=S3ModelDataSource( s3_uri=f"{model_artifact}/", s3_data_type="S3Prefix", compression_type="None", ) ), environment=vllm_env ), execution_role_arn=role, )SageMaker AI 엔드포인트에 모델을 배포하는 코드
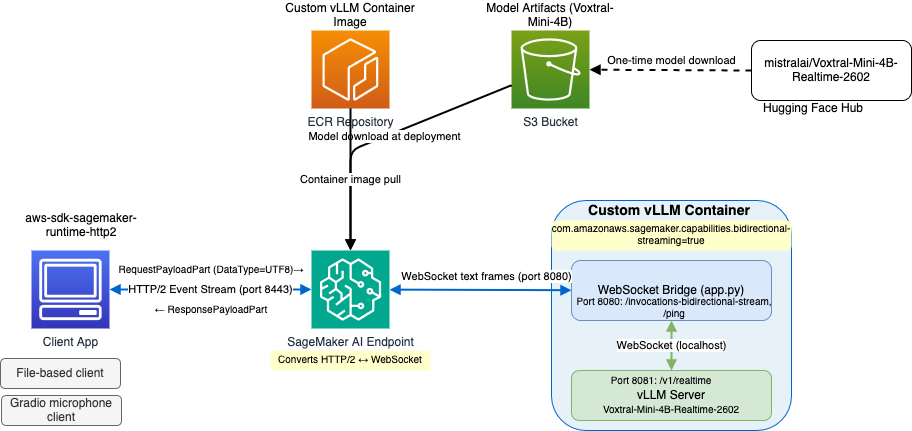
- Voxtral-Mini-4B-Realtime-2602 supports up to 262,144 tokens of context. — Deploy to a SageMaker AI endpoint section
용어 해설
- vLLM
- — 고성능 LLM 추론 및 서빙 엔진. PagedAttention 기술을 통해 메모리 효율을 극대화하며, Realtime API를 통해 WebSocket 기반의 스트리밍 추론을 지원한다.
- WebSocket
- — 클라이언트와 서버 간의 전이중 통신을 지원하는 프로토콜. 실시간 음성 인식처럼 데이터가 지속적으로 오가는 서비스에서 필수적이다.
- CUDA Graph
- — GPU 커널 실행을 그래프 형태로 미리 정의하여 실행 오버헤드를 줄이는 기술. vLLM에서 추론 지연 시간을 낮추는 데 사용된다.
- HTTP/2
- — 웹 통신 프로토콜. 다중화 및 양방향 스트리밍을 지원하여 SageMaker AI에서 실시간 데이터 전송을 가능하게 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.