TL;DR
다양한 데스크탑 소프트웨어를 사용하는 에이전트의 평가와 학습은 화면 기반 신호에 의존하기 쉽다. OpenComputer는 앱별 상태 검증기, 실행 기반 피드백 루프, 검증-지향 태스크 생성, auditable 평가 해Harness를 결합해 실제 소프트웨어 상태를 기반으로 보상을 산출하고 재현 가능성을 확보한다. 이로써 LLM-judge에 의한 평가 편향을 줄이고, 복잡한 애플리케이션 상태의 정합성을 확보한다.
왜 중요한가
다양한 데스크탑 소프트웨어를 사용하는 에이전트의 평가와 학습은 화면 기반 신호에 의존하기 쉽다. OpenComputer는 앱별 상태 검증기, 실행 기반 피드백 루프, 검증-지향 태스크 생성, auditable 평가 해Harness를 결합해 실제 소프트웨어 상태를 기반으로 보상을 산출하고 재현 가능성을 확보한다. 이로써 LLM-judge에 의한 평가 편향을 줄이고, 복잡한 애플리케이션 상태의 정합성을 확보한다.
핵심 기여
앱별 상태 verifiers 구축
각 응용 프로그램에 대해 구조화된 inspection 엔드포인트를 노출하는 verifier Va를 생성하고, 단위/통합 테스트를 통해 안정성 및 재현성을 확보한다.
실행 기반의 자기 진화 검증
약한 verifier를 Calibrations 태스크로Stress 테스트하고, 실행 궤적을 바탕으로 checker 로직/엔드포인트를 수정하는 self-evolving loop를 운영한다.
verifier-grounded task 생성 파이프라인
검증 가능한 엔드포인트를 바탕으로 현실적이면서도 데이터 생성성과 난이도를 고려한 데스크톱 태스크를 합성한다.
실행 기반 평가 해Harness 제공
fresh sandbox에서 에이전트를 실행하고, 스크린샷과 행동 로그를 수집한 뒤 verifier를 통해 자동으로 보상을 산출한다.
핵심 아이디어 이해하기
출발점과 한계: 데스크톱 태스크의 성공은 화면 정보뿐 아니라 애플리케이션 상태, 파일, 메타데이터 등 비가시적 요소에 의존한다. 기존 접근은 화면 기반 판단에 의존하기 쉽고 재현적 보장을 제공하기 어렵다. 해결 원리: 앱별 verifier를 통해 안정적 inspection 채널을 열고, 실행-기반 피드백으로 verifier를 보정한다. 파이프라인은 태스크 제안→ verifier 확장→ 환경 합성→ 평가로 진행되며, 모든 보상은 기계 체크 가능한 검증으로 산출된다. 달라지는 점: LLM-judge에 의존한 평가보다 hard-coded verifier가 실제 소프트웨어 상태를 정확히 반영하므로 인간 판정과의 일치도가 높아진다. 이로써 데스크톱 워크플로우의 다양한 상태를 포괄하는 대규모 벤치마크를 구축하고, 학습 데이터로 활용할 수 있는 확실한 피드백을 제공한다.
방법론
전체 접근 방식은 앱별 verifier 생성 → self-evolving verifier → verifier-aware 태스크 생성 → 실행 기반 평가로 구성된다. [어떤 값을 입력으로] 데스크톱 애플리케이션 a와 목표 g가 주어지면 [계산] Verifyers Va를 통해 엔드포인트를 확정하고, [결과] 태스크 인스턴스 τ=(x,e,c)을 생성한다. [의미] 이렇게 만들어진 태스크는 fresh sandbox에서 에이전트를 평가하는 도구가 되고, rewards는 검증 가능한 체크들의 통과 비율인 R=Npass/Ntotal로 정의된다.
관련 Figure
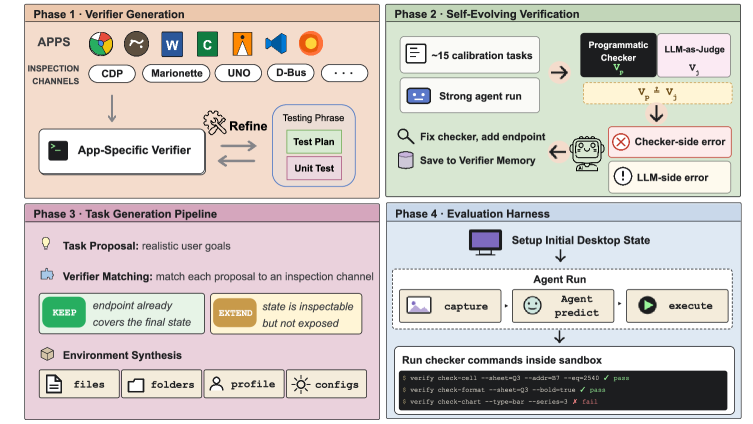
Figure 1은 네 가지 핵심 구성요소와 순환 피드백 루프를 시각화하여, 환경 합성에서 평가까지의 전체 흐름을 이해하게 한다. 이는 methodology의 핵심 아이디어를 직접적으로 보강한다.
OpenComputer 파이프라인의 4단계(Verifier Generation, Self-Evolving Verification, Task Generation, Evaluation Harness)와 각 단계 간 상호작용을 요약한 도식.
주요 결과
주요 벤치마크 결과: 33개 애플리케이션, 1,000개의 finalized 태스크를 대상으로 평가. GPT-5.4의 전체 태스크 성공률은 68.3%, 평균 보상은 88.4%이며 OSWorld-Verified와의 비교에서 우수한 성능을 보인다( GPT-5.4: OSWorld 75.0%, Avg. Reward 88.4% ). Claude-Sonnet-4.6은 64.4%, Kimi-K2.6은 58.8%의 성공률을 기록한다. Qwen 계열과 GUI-OWL은 낮은 성능을 보였으며 OSWorld 점수와의 일반화 차이가 크다. Ablation 연구: self-evolving verification으로 verifier agreement가 85.2%에서 94.1%로 개선되며, 159개 calibration 중 68건이 수정되었다. 반면 450개의 calibration 중 8건은 예산 내에 해결되지 못했다. GUI vs CLI 평가: GUI에서 GPT-5.4가 75.2%의 성공률, 평균 288초/태스크, Claude Sonnet 4.6은 73.0%로 622초 소요; CLI 설정은 Claude Code가 67.2%, 141초로 가장 빠름. OSWorld 대비 OpenComputer의 경향성 차이는 크고, 강건한 상태 기반 검증이 중요하다는 점이 확인되었다.
기술 상세
3.2.1Verifier Generation: 각 애플리케이션에 대해 안정적 inspection 채널을 매핑하고, CLI/엔드포인트를 통해 JSON 출력으로 노출하는 verifier 모듈을 구축한다. Endpoint construction은 surfaces를 탐색하고, 각각에 대해 query endpoint와 check-* 엔드포인트를 구현하며, README에 인터페이스를 문서화한다. Verifier Testing Protocol은 예상 주장, fixtures, 양/음수 케이스, JSON-검증, 일반적인 실패 모드를 다룬다. 3.2.2 Self-Evolving Verification Layer는 Calibration Executions를 통해 verifier의 취약점을 찾고, disagreement를 분류한 뒤 checker 로직/엔드포인트/문서를 수정하는 루프를 고정 예산 하에 수행한다. 3.3 Task Generation Pipeline은 제안-필터-검증-환경 합성의 네 단계로, 이미 끝난 엔드포인트가 있으면 그대로 보존하고, 필요 시 새로운 엔드포인트를 확장한다. 3.4 Evaluation Harness는 fresh sandbox에서 에이전트를 실행하고, trajectory를 screenshot과 함께 기록한 뒤 task c를 만족하는지 검사한다. 보상 R은 Npass/Ntotal으로 계산되며, 필요 시 self-evolving verification의 선택적 적용으로 품질을 관리한다.
한계점
생성된 태스크 중 일부는 하드 코드 검증기로 완전한 검증이 불가능하여 LLM-판단이 보조적으로 사용되며, 본 벤치마크의 주요 결과에서 제외된다. 또한 일부 애플리케이션에서 복잡한 레이아웃/시각적 구성이 요건으로 작용하는 경우가 있어, 프로그램적 검사만으로 완전한 판단이 불가능할 수 있다. 사용 예산과 구현 편의성 간의 트레이드오프가 존재한다.
실무 활용
OpenComputer는 컴퓨터--use 에이전트의 훈련 및 평가를 위한 확장 가능한 인프라를 제공한다. 실행 기반의 검증과 자동화된 태스크 생성을 통해 재현 가능하고 감사 가능한 벤치마크를 구성한다.
- 데스크톱 자동화 에이전트의 대규모 벤치마크 구축 및 평가
- 에이전트 학습 데이터 생성(SFT/RLHF) 및 rejection sampling
- 새로운 애플리케이션 도메인에 대한 verifier 확장 및 보강
- LLM 평가자의 편향에 의존하지 않는 보상 신호 제공
코드 공개 여부: 공개
코드 저장소 보기키워드
추가 이미지 분석
LLM judge가 특정 criterion에서 근거를 충분히 확보하지 못하는 사례를 시각화함으로써, verifier 기반 평가의 필요성과 강점을 명확히 한다.
LLM-as-Judge 오류 예시와 hard-coded verifier 간의 차이를 보여주는 도해
두 케이스를 통해 LLM-judge의 한계와 hard-coded verifier의 필요성의 근거를 강화하고, 평가 파이프라인의 설계 의도를 보강한다.
다른 LLM-judge 오류 사례를 통해 서술된 두 유형의 실패를 비교
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.