TL;DR
현존 벤치마크는 데이터 다양성·생성 설정의 확장성 면에서 한계가 있다. MSAVBench는 비디오, 오디오, 샷 수, 레퍼런스의 네 차원에 걸친 포괄적 커버리지를 제공하고, 샷 경계의 self-correction과 주관 지표의 인스턴스-루브릭 기반 평점, 외부 도구를 활용한 증거 기반 평가를 도입해 현대 MSAV 모델의 다면적 성능을 더 신뢰성 있게 측정한다. 또한 19개 모델에 대한 체계적 비교를 통해 공개형 파이프라인의 개선 가능성과 현행 시스템의 한계를 진단한다.
왜 중요한가
현존 벤치마크는 데이터 다양성·생성 설정의 확장성 면에서 한계가 있다. MSAVBench는 비디오, 오디오, 샷 수, 레퍼런스의 네 차원에 걸친 포괄적 커버리지를 제공하고, 샷 경계의 self-correction과 주관 지표의 인스턴스-루브릭 기반 평점, 외부 도구를 활용한 증거 기반 평가를 도입해 현대 MSAV 모델의 다면적 성능을 더 신뢰성 있게 측정한다. 또한 19개 모델에 대한 체계적 비교를 통해 공개형 파이프라인의 개선 가능성과 현행 시스템의 한계를 진단한다.
핵심 기여
MSAVBench의 네 가지 차원 데이터 설계
Video, Audio, Shot, Reference의 네 차원을 포괄적으로 다루고, 2~15샷의 설정과 현실/비현실적 시나리오를 포함한 프롬프트 스펙을 제공한다.
적응형 하이브리드 평가 프레임워크
샷 경계 오류의 누적 확산을 막기 위해 TransNet V2로 초기 경계를 추출하고, Qwen3.5를 통해 샷을 점검·필요 시 병합/분할하는 self-correction를 도입한다. 필요 시 도구를 활용해 객관적 증거를 수집한다.
인스턴스-루브릭 기반 주관 지표 평가
Narrative coherence 등 주관적 차원은 직접 점수 대신 다지선다형 문항으로 평가하는 인스턴스-루브릭 방식으로 평가의 안정성을 높인다.
도구-근거 기반 평가 및 다중 모달 정렬
Layout-text consistency 등 복합적 속성은 외부 도구의 증거를 바탕으로 최종 판단에 반영하여 다중 모달 정렬 신뢰성을 높인다.
실험적 대조 및 공개 자원
19개 모델의 벤치마크 평가를 통해 모듈형/에이전트형 파이프라인의 가능성을 확인하고, 벤치마크 데이터셋과 평가 코드 MSAVBench를 공개한다.
핵심 아이디어 이해하기
단계적 구성으로 문제를 정의하고 해결하는 구조다. 시작점은 MSAV 생성의 복합성으로, 기존의 단일 샷 또는 더미 수준의 오디오-비디오 평가로는 긴 스토리텔링의 제약을 설명할 수 없다는 점이다. MSAVBench는 (1) 비디오/오디오/샷 수/레퍼런스의 4차원 데이터 디자인, (2) 현실 및 비현실적 프롬프트의 교차-조합으로 긴 형식의 균일한 도메인 일반화 도모, (3) 샷 경계의 self-correction과 다층적 평가 파이프라인으로 잘못된 샷 분할에 따른 오차 전달 최소화, (4) 인스턴스-루브릭과 도구-근거를 통한 주관/객관 평가의 결합으로 인간 평가와의 높은 상관도 확보라는 원리를 따른다. 이로써 긴 서사 구조의 품질, 오디오-비주얼 정합성, 레퍼런스 유지 등 다차원 평가를 동시에 달성한다. 1단계 데이터 설계는 8개 영상 주제군과 6개 언어를 포함한 다양성 확보와 2~15샷의 다단계 난이도 구성을 통해 시나리오의 폭을 확장한다. 2단계 평가 프레임워크는 샷 경계 불확실성으로 인한 오차를 줄이는 자기-수정 루프와, 복합 속성에 대해 도구 기반 증거를 활용하는 허용적 판단으로 신뢰성을 제고한다. 최종적으로 91.5%의 Spearman ρ로 인간 판단과의 고정도 정합을 달성한다.
관련 Figure
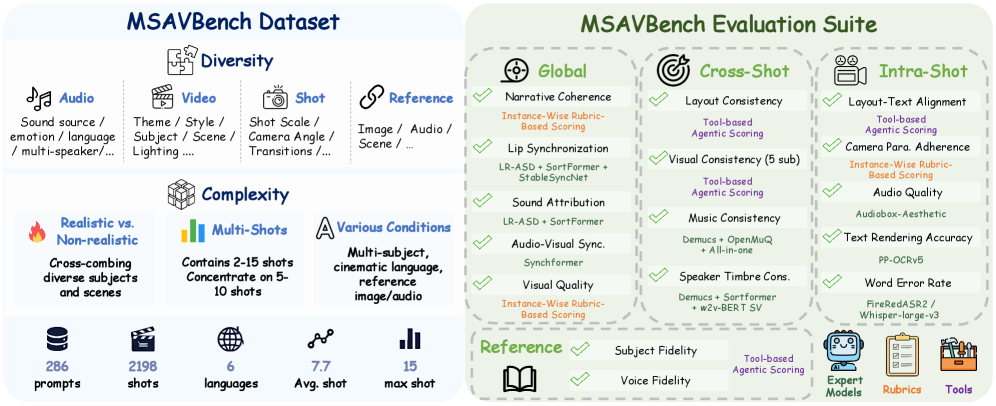
벤치마크의 구성 요소를 시각적으로 요약하여 독자에게 MSAVBench가 다루는 4차원 데이터 디자인과 평가 체계를 직관적으로 전달한다.
Figure 1은 MSAVBench의 데이터셋과 평가 체계를 한 눈에 보여주는 개요 다이어그램이다.
방법론
단계 1: 데이터 설계(4차원, 8개 주제군, 2200개의seed-quadruples, 286 프롬프트, 2198샷) → 단계 2: Prompt-Enhancement를 통한 글로벌-투-샷 스크립트 작성 → 단계 3: 6명의 도메인 전문가가 스크립트 품질 검토 및 정제 → 단계 4: 레퍼런스 미디어 68subject 이미지, 65 오디오 클립, 32 장면 이미지를 구성하고 스크립트의 시맨틱 조건과 매칭을 확보. 샷 경계는 TransNet V2로 초기 추정 후 Qwen3.5로 점검하고 필요 시 병합/분할, 최대 2회 반복. 평가 지표는 총 20개로, Global/Cross-Shot/Intra-Shot/Reference의 4단계 계층으로 구성되고, Specialist 모델/Instance-wise rubric-based scoring/Tool-grounded agentic scoring의 3가지 패널로 구현된다. Visual/Audio 도메인 11개 차원으로 축약한 후 샷-완성도 보정 계수로 최종 점수를 산출한다.
관련 Figure
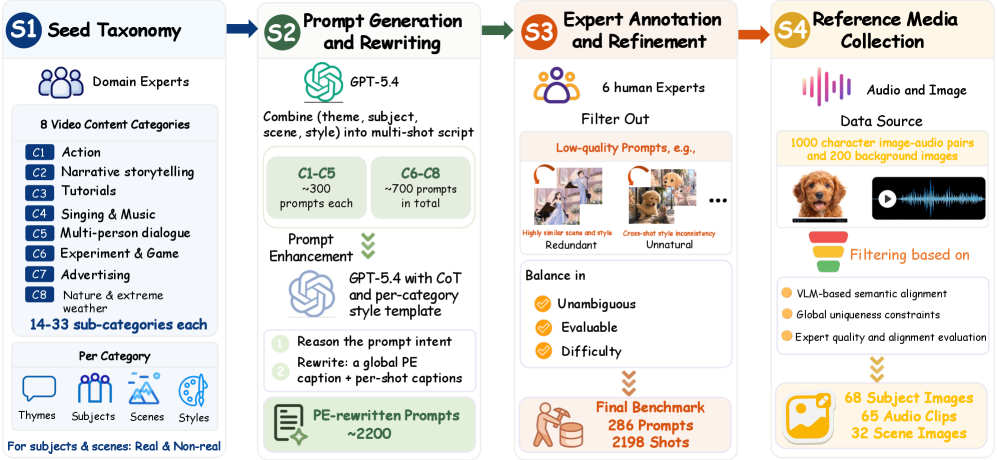
Seed taxonomy → 프롬프트 생성/재작성 → 전문가 검토/정제 → 레퍼런스 미디어 수집의 과정을 도식화하고, 데이터 품질 관리의 자동화 흐름을 제시한다.
Figure 5는 데이터 construction 파이프라인의 요약 흐름을 보여준다.
주요 결과
메인 벤치마크 결과: 19개 모델을 평가한 MSAVBench에서 모듈형/에이전트형 오픈 소스 파이프라인이 클로즈드 시스템과의 격차를 좁히는 방향임을 확인했다. Spearman ρ = 0.915로 인간 판단과 높은 정합을 보였고, 평균 샷 수는 7.7샷(범위 215)이며 프롬프트 수는 286개, 샷 수는 2198개다. 샷 수가 증가할수록 특히 오픈 소스 모델의 성능 저하가 더 두드러졌으며, 1115샷 구간에서 Kling-V3-T2V의 감소폭은 3.5%인데 반해 LongLive+HunyuanFoley의 감소폭은 24.5%에 이르는 등 다샷 일관성의 한계가 확인되었다. 실제로 비현실적(Non-Realistic) 프롬프트에서의 점수 하락도 발생했고, 레퍼런스- conditioned 모델의 시각적 일치도도 공통적으로 난이도가 높은 영역에서 낮아졌다. 특히 Lip synchronization, sound attribution, audio-visual synchronization, 다중 화자 맥락에서의 Spk. timbre 일관성 등의 교차-모달 정렬 문제가 여전히 큰 도전 과제로 남았다. 레퍼런스 기반 AV 생성 부분에서의 시각적 충실도는 오픈 소스 DreamID-Omni에 비해 Wan-R2V, HappyHorse-R2V가 더 우수했고, 음성 톤은 유사도에서 근접한 편이었다(Table 5). 비용/효율 측면에서는 도구 기반 평가와 전문가 모델의 조합이 비용을 크게 낮추는 방향임이 확인되었으며, VLM 백본의 변화에도 안정적인 측정이 가능했다.
관련 Figure

문서에서 제시한 실패 유형(A-E)을 시각적으로 확인할 수 있어, 모듈러 제어 및 다중 모달 정합성의 한계가 구체적으로 드러난다.
Figure 4는 평가에서 제시된 Qualitative failure 케이스를 보여준다.
기술 상세
MSAVBench의 데이터 구성은 4가지 차원(video/audio/shot/reference)으로 구성되고, 각 차원은 하위 속성으로 세분화된다. Stage 1에서 도메인 전문가가 8개의 영상 장르 및 세부 하위 카테고리를 정의하고 주제-대상-장면-스타일의 4튜플을 생성한다. Stage 2에서 GPT-5.4가 초기 프롬프트를 샘플링하고 Prompt-Enhancement 모델이 글로벌-투-샷 스크립트로 재작성한다. Stage 3에서 6명의 도메인 전문가가 스크립트를 검토하고 중복/허위 묘사를 제거한다. Stage 4에서 68subject 이미지, 65 오디오 클립, 32scene 이미지를 수집하고 Gemini 3.1 Pro로 태깅한 후 정합성 확인을 거친다. 평가 파이프라인은 20개 메트릭을 네 가지 레벨로 구성하며, Global( Narrative coherence, Lip synchronization, Sound attribution, Audio-visual Synchronization, Visual quality ), Cross-Shot, Intra-Shot, Reference로 구분한다. 샷 경계 오류를 줄이기 위해 TransNet V2로 초기 경계를 추출하고, Qwen3.5를 이용해 샷을 반복적으로 점검하고 필요 시 병합/분할하며, 최종적으로 샷-캡션 정합성 재조정이 가능하다. 평가 방식은 10개의 메트릭에서 전문 모델, 5개의 메트릭에서 인스턴스-루브릭 기반 점수, 5개의 메트릭에서 도구-근거 기반 점수로 구성된다.
한계점
논문은 현재 다중 샷 AV 생성을 네이티브하게 지원하는 오픈소스 모델이 부재하므로, 벤치마크의 일부 구성은 기존 모델의 파이프라인에 의존한다는 한계를 지적한다. 또한 멀티모달 평가의 일부 구성요소가 여전히 VLM 기반 판단에 의존하여 비용이 증가할 수 있으며, Open-source 기반의 완전한 다샷 AV 생성 모델이 나타나면 벤치마크의 구성요소를 확장할 필요가 있다.
실무 활용
MSAVBench는 다중 샷 AV 생성 연구의 표준화된 벤치마크와 평가 프레임워크를 제공함으로써, 연구자는 다양한 데이터 설정과 영상-오디오의 정합성 문제를 체계적으로 진단하고, 오픈 소스 파이프라인의 개선 방향을 모색할 수 있다.
- 다중-shot AV 생성 모델의 품질 진단
- 오픈 소스 파이프라인의 모듈화 설계 비교
- 샷 경계 자동 보정과 루브릭 기반 주관 평가의 효과 분석
- 레퍼런스 조건의 AV 생성 품질 평가
- 합성 콘텐츠의 시나리오 설계 및 감독 수준 제어 연구
코드 공개 여부: 공개
코드 저장소 보기관련 Figure
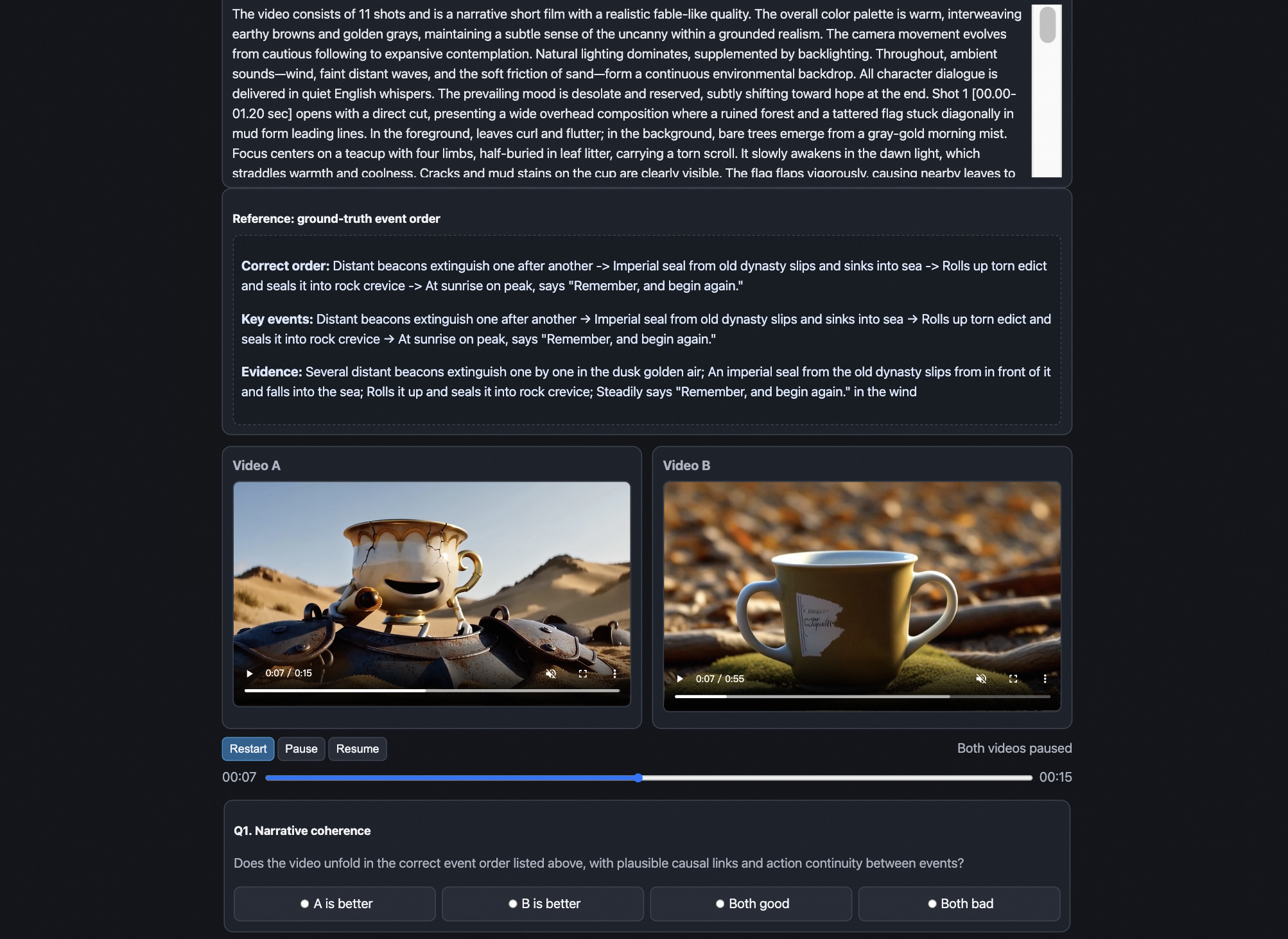
실험 인터페이스의 작동 방식과 평가 워크플로우를 구체적으로 보여주며, 인간 평가와 자동 평가의 상호작용을 설명하는 데 도움을 준다.
Arena 페이지 시뮬레이션 인터페이스 예시로, 패널 간 비교와 평가 워크플로우를 시연한다.
키워드
추가 이미지 분석
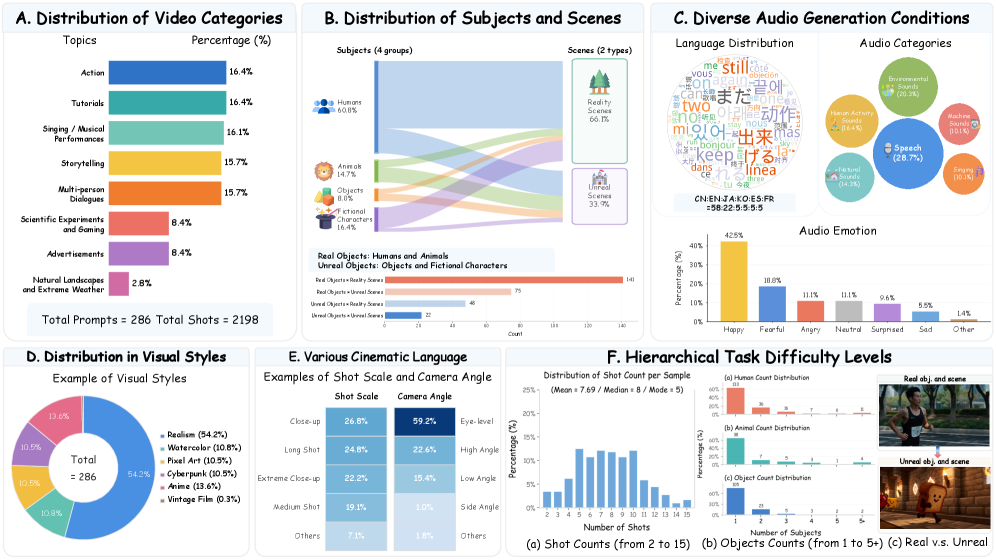
데이터 구성의 다양성과 난이도 구성의 실질적 범위를 보여주며, 286 프롬프트/2198샷의 스케일과 다층적 품질 평가의 근거를 제공한다.
Figure 2는 프롬프트 분포와 주제 간 균형, 샷 수 분포 등 데이터 다양성의 분포를 시각화한다.
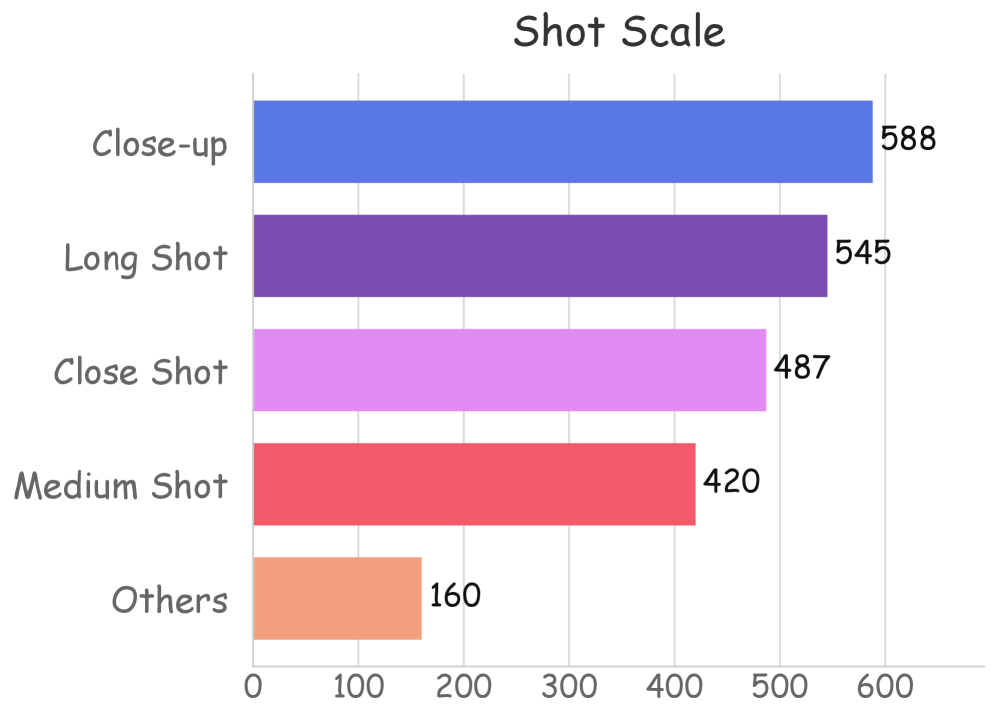
샷 구성의 다양성과 시네마틱 언어의 분포를 보여주며, 평가 지표의 다차원적 특성을 시각적으로 보강한다.
Figure 6은 프롬프트Suite의 샷 스케일, 카메라 각도, 트랜지션, 톤/색채의 분포를 차트로 제시한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.