TL;DR
동적 3D 장면의 고품질 4D 메시지 생성을 위한 학습 데이터 의존성을 낮추고, 프레임 간 일관성을 유지하면서도 수십 초 단위의 속도로 처리한다. backbone이 고정된 상태에서 어텐션 체인을 활용해 앵커 메시지와 프레임 간 매핑을 얻으므로 추가 학습 없이도 4D 추적과 카메라 추정 같은 다운스트림 작업에 활용 가능하다. 더 길어진 시퀀스에서도 correspondences를 보강해 드리프트를 줄이고 안정성 있는 롤아웃을 달성한다.
왜 중요한가
동적 3D 장면의 고품질 4D 메시지 생성을 위한 학습 데이터 의존성을 낮추고, 프레임 간 일관성을 유지하면서도 수십 초 단위의 속도로 처리한다. backbone이 고정된 상태에서 어텐션 체인을 활용해 앵커 메시지와 프레임 간 매핑을 얻으므로 추가 학습 없이도 4D 추적과 카메라 추정 같은 다운스트림 작업에 활용 가능하다. 더 길어진 시퀀스에서도 correspondences를 보강해 드리프트를 줄이고 안정성 있는 롤아웃을 달성한다.
핵심 기여
Attention Chain 정의와 활용
Anchor vertex에서 latent tokens로의 Vertex-to-Token, 프레임 간 Latent Token 간의 Token-to-Token, 프레임의 surface 포인트로의 Token-to-Surface를 차례로 연결하는 Spatio-Temporal Attention Chain을 제시한다. 이는 4D generator의 내부 어텐션을 보강 없이도 직접 활용해 dense 매핑을 얻도록 한다.
Training-free 4D mesh generation 프레임워크
ActionMesh의 고정된 뼈대를 활용하되, Stage II 학습 네트워크를 제거하고 four-form의 attention-chain과 간단한 스킨ning으로 애니메이션을 얻는다. 학습 없이도 9s 내외의 속도로 16-frame 클립의 4D 메시지를 생성한다.
Long-sequence autoregressive 안정화
16-frame 윈도우에서의 denoising 과정 중 가장 중요한 латент 토큰 쌍(t, t′)을 추적하고 이를 신뢰도에 따라 가중치를 재조정하는 방식으로 correspondences를 강화한다. 이를 통해 240프레임까지의 롤아웃에서도 드리프트를 억제한다.
2D/4D 포인트 추적 및 카메라 추정 확장
2D 패치-토큰-프레임 간 어텐션을 연결해 이미지-메시지 간 브리지(2D→3D) 매핑을 만들고, PnP를 통해 카메라 자세를 회복한다. 이로써 4D 메쉬뿐 아니라 2D 트래킹과 월드 좌표 추적에도 활용 가능하다.
핵심 아이디어 이해하기
출발점: 기존 4D 메쉬 생성 파이프라인은 학습 기반의 애니메이터/상호작용 모듈에 의존해 속도와 확장성에 한계가 있다. 어텐션은 입력 간의 관계를 확률 분포로 표현하므로, anchor 프레임의 3D 토큰과 이후 프레임의 토큰 간의 관계를 확률적으로 전달하는 기제로 작동한다. 이 아이디어를 4D 생성 backbone 내부의 고정된 어텐션으로 읽어 들여 Va→Za → Zf → Vf의 체인을 구성하면, 추가 학습 없이도 픽셀과 3D 표면 간의 dense 매핑을 얻을 수 있다. 이를 통해 16프레임 윈도우에서 프레임 간 매핑을 강화하고, 긴 시퀀스에서도 안정적인 4D 메시지 생성을 달성한다. 체인의 끝에서 얻은 sparse 매핑을 컨트롤 랜드마크로 확장해 전체 메시를 topology 보존 형태로 애니메이션하고, 2D/4D 트래킹 및 카메라 포즈 추정까지 확장한다.
방법론
- Va → Za: Stage 0에서 앵커 메시 Va를 3D 디코더의 cross-attention AVa→Za를 통해 N개의 잠재 토큰 Za로 표현한다. 각 Va에 대해 어떤 토큰이 관련되는지 확률 분포를 얻을 수 있다. 2) Za → Zf: Stage I의 denoising 단계에서 프레임 f의 토큰 Zf로의 연결 AZa→Zf를 얻어 anchor 프레임의 정보를 프레임 f로 전달한다. 3) Zf → Vf: 프레임 f에서 디코더가 Zf를 Vf로 변환하는 implicit field에서 후보 표면 Sf를 구성하고, 각 후보를 프레임 f의 토큰과 cross-attention으로 연관짓는다. 4) 합성: AVa→Za [v, :]와 AZa→Zf [t, t′]를 곱해 v가 프레임 f의 토큰 t′에 미치는 확률 분포를 얻고, sv,f(u)로 표면 포인트 u와의 내적을 계산한다. 이를 top-Nv,f 지점에서 소프트맥스 합으로 ṽf로 변환한다. 5) 애니메이션: sparse 컨트롤 랜드마크를 추출하고, 1D Gaussian으로 시간 축에서 가중치를 두고, Geodesic Rigid Skinning으로 전체 메시에 전달한다. 6) 롤아웃 확장: 240프레임까지의 롤아웃에서 2-단계 denoising은 유지하고, 남는 두 단계에서 중요한 latent 토큰 쌍을 강화한다. 7) 보정: 카메라 포즈 추정(PnP)으로 global rigid 변위를 보정해 월드 좌표계에 맞춘다.
관련 Figure
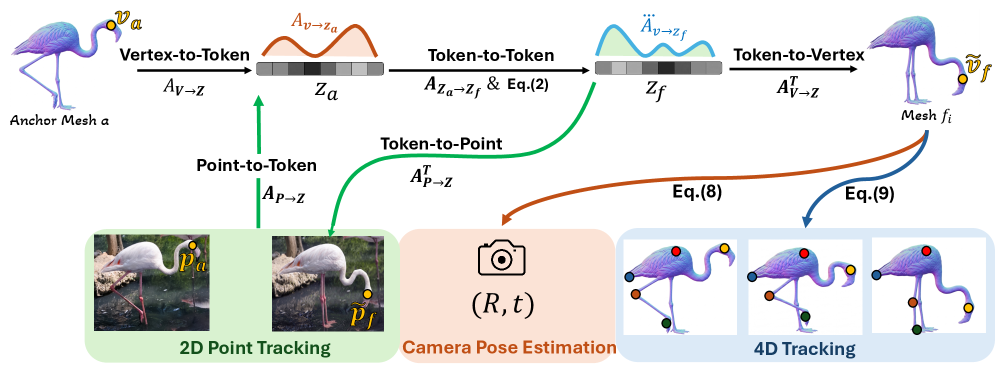
해당 그림은 attention chain의 구성요소를 한 눈에 보여주며, Va→Za, AZa→Zf, Zf→Vf의 흐름을 통해 프레임 간 매핑이 어떻게 이루어지는지 설명한다.
Figure 1: Anchor Mesh에서 Vertex-to-Token, Token-to-Token, Token-to-Vertex를 잇는 attention chain의 흐름을 시각화한다.
주요 결과
메인 벤치마크에서 ActionBench 기준 CD-3D 0.048, CD-4D 0.077, CD-M 0.163, Normal Consistency 0.97를 기록하며, 벤치마크 상의 대부분 지표에서 최상위 성능을 달성했다. 비교 대상은 Trellis, TripoSG, DM4D, LIM, V2M4, SG4D, ActionMesh이며, End-to-end 소요 시간은 9초로 다른 방법의 수십에서 수백 초 대비 크게 빠르다. Consistent4D의 렌더링 측정에서도 Ours + CPE가 LPIPS 0.0823, CLIP 0.9468, DreamSim 0.0319로 최상위에 근접했다. 2D 포인트 트래킹은 DAVIS-foreground에서 Zero-shot 최강으로 평가되었고, BADJA에서도 경쟁력이 높았다. 4D 포인트 트래킹은 PO에서 APD3D가 +28.4 포인트 향상, DR에서 +23.7 포인트 향상을 보이며 Zero-shot ActionMesh Stage II 대비 크게 향상되었다. 카메라 추정까지 포함하면 월드 좌표의 4D 트래킹 성능이 상향되며, 학습 없이도 4D+카메라 추정이 가능하다.
관련 Figure
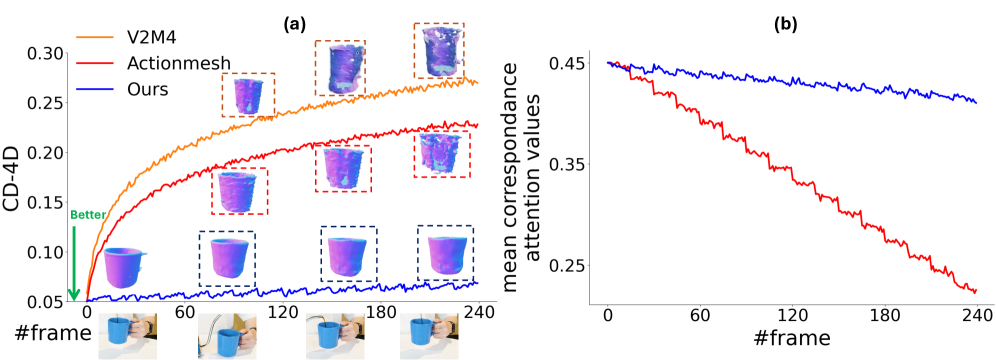
드리프트 억제와 correspondences 보강의 효과를 시각적으로 제시하며, 시퀀스 확장 시 안정성을 설명한다.
Figure 2: 긴 시퀀스 롤아웃에서 drift와 correspondences reinforcement의 효과를 비교한다.

부분적으로 비정합적 실루엣을 줄이고, 카메라 정합이 더 정확하게 보이는 것을 시각적으로 보여줌으로써 본 방법의 품질 우수성을 보강한다.
Figure 3: ActionMesh 대비 ours의 4D Mesh Generation 품질 비교(좌측 ActionMesh, 우측 our).

다양한 입력 영상에서 ours가 더 샤프하고 템포럴 아티팩트가 적은 것을 보여준다.
Figure 5: 다양한 시퀀스에서의 4D Mesh 생성 품질 비교(좌 ActionMesh, 우 ours).

장기 시퀀스에서의 안정성을 시각적으로 강조하며, correspondences reinforcement의 효과를 시연한다.
Figure 6: 240프레임 롤아웃의 장기 시퀀스에서의 드리프트 감소 및 안정성 유지.
기술 상세
- 아키텍처: Stage 0의 이미지-3D anchor 재구성, Stage I의 비디오-4D 메쉬 생성, Stage II의 topology-preserving 디코딩을 학습 없이 대체한다. 2) 수학적 기반: Attn(X, Y) = Attn 행렬의 소프트맥스 기반 확률 매핑으로 Va→Za, Za→Zf, Zf→Vf를 계산하고, sv,f(u) = Σt′ Av,Zf(t′) A^T Zf→Vf(u, t′)로 후보 표면 포인트의 점수를 얻은 뒤, ṽf = Σu∈Nv,f πv,f(u) x(f)u로 연속 매핑을 수행한다. 3) Prior work 대비 차별점: 학습된 Stage II를 제거하고 frozen backbone의 어텐션에서 직접 3D-2D 매핑 정보를 추출한다. 4) 구현/세부: TripoSG(Anchor) + Φθ(16-frame denoiser) 기반으로 Zf를 생성하고, 4단계의 denoise만 사용하여 drift를 줄인다. 5) 롤아웃 확장: 16-frame 윈도우를 재인코딩하며, 각 윈도우에서 주요 토큰 쌍(t, t′)를 보강한다. 6) 2D/4D 확장: Pa→Za, Za→Va, and Pv→Za, Za→V a를 연결해 픽셀-메시 매핑 및 PnP 카메라 포즈 추정에 활용한다.
한계점
<Mesh quality dependent on image-to-3D 모델과 denoiser의 품질>; Sparse smoothing과 local-rigid deformation이 미세 모션을 감소시킬 수 있음; 장시간 롤아웃에서 주의가 필요하고, attention이 확산될 경우 성능 저하 가능성.
실무 활용
훈련 없이도 4D 메쉬를 빠르게 생성하고, 2D/4D 추적 및 카메라 포즈 추정을 지원하는 파이프라인이다. 고정된 4D 백본에서 attention chain을 읽어 anchor 메쉬의 구조를 유지하며, 짧은 윈도우와 보정으로 대규모 시퀀스까지 확장 가능하다.
- 실시간 또는 근실시간 영상에서의 동적 객체의 4D 메시지 재구성
- 비디오에서 2D 포인트 및 4D(world-coordinate) 포인트 트래킹
- 입력 영상으로부터 카메라 포즈를 회복하여 3D 씬에 메시지 삽입/합성
- 비디오 기반 4D 씬 재구성 및 시청각 콘텐츠의 정합성 개선
코드 공개 여부: 미확인
관련 Figure
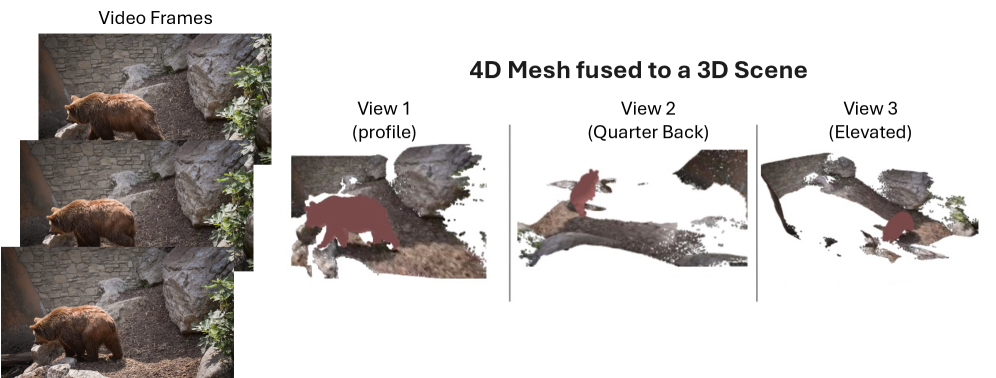
2D 이미지-3D 매칭과 월드 좌표 시스템에서의 배치를 시각적으로 설명하며, 카메라 포즈 추정의 가능성을 직접 보여준다.
Figure 4: 4D Mesh를 3D 씬에 정합하는 카메라 포즈 추정 및 씬 배치 흐름.
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.