TL;DR
긴 컨텍스트에서 prefix를 재사용할 때 매 스텝마다 prefix에 대한 self-attention이 필요하면 비용과 지연이 증가한다. Attention-State Memory(ASM)는 training-free로 prefix를 memory에 외부화하고 inference 시 조회하여 prefix-attention을 제거한다. ManyICLBench와 NBA 벤치마크에서 ASM은 1K–8K 메모리 예산에서 ICL 대비 성능을 유지하거나 향상시키고 prefix-attention 지연을 감소시킨다.
왜 중요한가
긴 컨텍스트에서 prefix를 재사용할 때 매 스텝마다 prefix에 대한 self-attention이 필요하면 비용과 지연이 증가한다. Attention-State Memory(ASM)는 training-free로 prefix를 memory에 외부화하고 inference 시 조회하여 prefix-attention을 제거한다. ManyICLBench와 NBA 벤치마크에서 ASM은 1K–8K 메모리 예산에서 ICL 대비 성능을 유지하거나 향상시키고 prefix-attention 지연을 감소시킨다.
핵심 기여
Attention-State Memory(ASM)
훈련 없이 구성 가능한 lookup-based memory로, prefix와 query 토큰 간의 attention outputs를 미리 계산하여 per-layer memory에 저장하고 inference 시 조회·병합한다.
Cross-query Prefix Reuse를 위한 Online-Softmax Identity 확장
온라인-소프트맥스 아이덴티티를 확장해 서로 다른 query 블록 간 prefix 재사용이 가능하도록 구성한다. 이로써 prefix의 영향 재생성 없이 prefix 주입을 대체한다.
오프라인.calibration으로 메모리 구성
프리픽스-대응 응답 트레이스의 forward passes를 통해 (q, a_p(q), Z_p(q))를 수집한 뒤, K-means로 centroids를 구성하고 attention-상태를 centroid로 집계한다.
온라인 검색으로 비용 절감
질의와 가장 유사한 centroid를 cosine similarity로 검색하고, 찾아낸 attention state를 merge하여 prefix-attention 없이 어텐션을 수행한다.
GQA 확장 및 시간-복잡도 관리
Group-Query Attention(GQA)에도 ASM을 확장해 KV head당 centroid를 하나로 관리하도록 하며, hierarchical lookup으로 retrieval을 O(log K)로 축소한다.
핵심 아이디어 이해하기
단계 1: 어텐션 분해성에 의해 prefix-attention은 서로 독립된 블록의 어텐션 상태(a(q), Z(q))로 표현 가능하다. 단계 2: Sufficiency에 의해 같은 쿼리에 대한 인접 블록의(attn) 상태를 합쳐 원래의 prefix-attention을 재현할 수 있다. 단계 3: Composability에 의해 서로 다른 블록의 상태를 merge 연산으로 합치면 접속된 블록들의 어텐션 결과를 loss 없이 복원할 수 있다. 단계 4: 이를 바탕으로 오프라인에서 representative 쿼리 집합을 clustering으로 요약하고, 온라인에서 nearest centroid로부터 얻은(attA, Z) 값을 질의의 self-attention에 merge한다. 단계 5: retrieval은 단일 차원 lookups가 아니라 RoPE 처리 방식(pre-RoPE vs RoPE-unified)과 whitening 여부에 따라 다르게 구성되며, hierarchical lookup으로 비용을 줄인다.
방법론
- 전체 접근: 오프라인-calibration과 온라인-inference로 구분된다. 오프라인에서 프리픽스(p)와 응답 트레이스(t) 조합의 forward를 수행해 각 layer(i)에서의 q와 prefix-attention state(a_p(q), Z_p(q))를 수집한다. K-means로 q 표현을 클러스터링하고 각 클러스터를 centroid(¯q_k, ¯a_k, ¯Z_k)로 요약한다. 이때 attention-aware aggregation(Eq.5)을 적용해 centroid를 구성한다. - online inference에서 질의 q에 대해 각 layer마다 가장 가까운 centroid c⋆(q)를 찾고, 해당 ¯a_c⋆(q), ¯Z_c⋆(q)를 가져와 amerge(q) = merge( (a(q), Z(q)), (¯a_c⋆(q), ¯Z_c⋆(q)) )의 방식으로 prefix-attention을 대체한다. - merge 연산은 a_merge(q) = (¯Z_a(q) a_A(q) + ¯Z_B(q) a_B(q)) / (¯Z_A(q) + ¯Z_B(q)) 이고 Z_merge(q) = ¯Z_A(q) + ¯Z_B(q) 이다. - GQA 확장에서는 그룹 당 KV-head 하나의 centroid를 사용하고, 집계된 쿼리를 그룹별로 클러스터링하거나 그룹 간에 연결하여 centroids를 구성한다. - retrieval 비용은 선형 검색에서 계층적 검색으로 O(K)에서 O(log K)로 감소한다. 각 질의는 RoPE 처리 방식과 whitening 여부에 따라 lookup 키를 구성한다. - chunked prefix 구성: 길이가 긴 prefix를 여러 조각으로 나눠 독립 forward에 의해 인코딩하고, merge로 합쳐 전체 prefix를 재현한다. 이는 peak 메모리 사용을 크게 줄이고 성능 손실 없이 16K prefix에서도 full-prefix 수준에 근접하게 한다.
관련 Figure
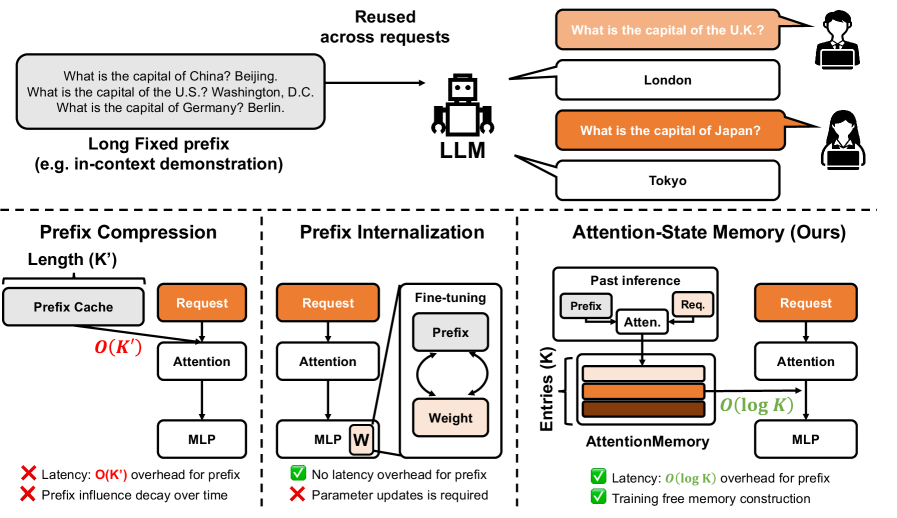
ASM의 위치를 시각적으로 보여주며, prefix-attention을 재사용하는 방식이 self-attention 재계산을 제거하는 핵심 아이디어임을 뒷받침한다. 또한 O(log K) 조회와 training-free memory construction의 이점을 강조한다.
Figure 1: Long Fixed prefix를 재사용하는 세 가지 방법의 비교( Prefix Cache/ Prefix Internalization/ Attention-State Memory ).
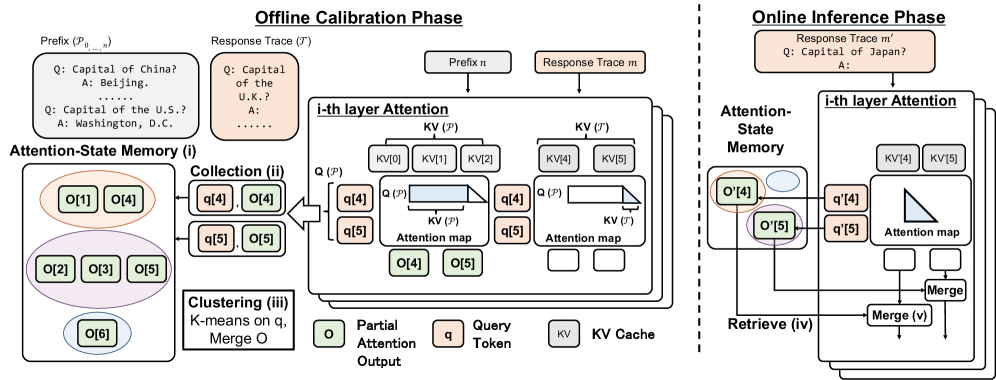
ASM의 오프라인 칼리브레이션과 온라인 추론 과정을 시각화한다. collection·clustering·retrieve·merge의 흐름이 논문의 핵심 방법론과 밀접하게 연결됨을 보여준다.
Figure 2: Attention-State Memory의 Offline Calibration Phase와 Online Inference Phase의 구성도.
주요 결과
4가지 핵심 벤치마크를 통해 ASM의 성능과 효율성을 검증한다. ManyICLBench에서 1K–8K memory budget에서 ASM은 ICL 대비 평균적으로 성능이 유지되거나 향상된다. 예를 들어 math_counting에서 1K에서 24.0%, 16K에서 26.0%의 정확도를 달성했고 gpqa_cot에서 16K에서 23.7%를 기록했다. NBA 벤치마크에서는 Zero-shot 21.2%, ICL(20K) 24.1%에 비해 ASM이 4K 엔트리에서 25.5%로 최상위를 차지했다. 이는 20%의 memory footprint로 full-context의 성능을 능가한다는 결론을 뒷받침한다. 또한 chunked prefix 구성의 경우 16K prefix를 4K 단위로 분할 인코딩해도 16K 전체 단일 forward 대비 성능 저하가 크지 않으며(예: banking77에서 16K-Chunked 78.5 vs 16K-단일 79.0) prefix의 정보가 보존된다. 속도 측면에서 ASM은 linear lookup 대비 hierarchical lookup을 도입해 retrieval을 O(log K)로 감소시키고, 최적 구성에서 full-attention 대비 4K 엔트리에서 성능이 비슷하거나 상회하며 16K에서 1.8×의 속도up를 달성한다.
기술 상세
- 아키텍처 구조: ASM은 per-layer dictionary(C(i))를 가지며, 각 엔트리는 q_bar^(i)_k, a_bar^(i)_k, Z_bar^(i)_k로 구성된다. q_bar는 lookup key이며, a_bar, Z_bar는 compressed attention state다. - 오프라인 칼리브레이션: collection 단계에서 [p, t] 시퀀스에 대해 KV 캐시를 얻고, 각 layer i의 Q(i)^(t)에서 prefix-attention state를 기록한다. clustering 단계에서 q 표현들의 centroid를 구성하고, Eq.(5)로 attention 상태를 집계한다. - 온라인 추론: 각 layer에서 질의 q의 nearest centroid를 검색하고, 얻은 (¯a_k, ¯Z_k)을 사용해 amerge(q)를 계산한다. - lookup-key 구성: RoPE 처리(pre-RoPE vs RoPE-unified)와 whitening 여부를 선택해 lookup key를 구성한다. - GQA 확장: 그룹당 KV head가 공유되므로 하나의 centroid를 그룹별로 구성하고, per-group fidelity와 lookup 비용 간의 트레이드오프를 조정한다. - 효율성: K 엔트리의 조회를 계층적 검색으로 O(log K)로 감소시키고, prefix chunking으로 긴 prefix도 관리 가능하다. - 한계: prefix drift가 큰 길고 다_turn 대화의 경우 query 분포가 확산되며, non-stationary workloads에 대한 lookup 전략 재설계가 필요할 수 있다.
한계점
프리픽스 드리프트가 큰 장기 대화 환경에서 query 분포가 비정상적으로 확산되면 현재의 단일 centroids 기반 조회가 한계를 보일 수 있다. 이 경우 query-dependent retrieval 대신 비정상 분포에 맞는 대체 lookup 전략이 필요하다.
실무 활용
실무 적용 가능성이 높다. 긴 프리픽스를 다수의 쿼리에서 재사용해야 하는 상황에서 training 없이 구성된 ASM은 prefix-attention의 비용과 지연을 줄일 수 있다.
- 대규모 대화 에이전트에서 재사용되는 프리픽스 관리
- RAG 파이프라인의 프리픽스 비용 절감
- 다수의 질의에서 동일 ký Prefix를 재사용하는 시스템에서의 latency 감소
- 긴 문서 기반의 질의 응답에서 prefix 정보 손실 최소화
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.