TL;DR
om-LLMs는 영상 프레임과 오디오 토큰을 텍스트 토큰과 결합해 멀티모달 추론을 수행한다. 다수의 비텍스트 토큰이 LLM 전체에 걸쳐 처리되면 계산량과 메모리 사용이 급증한다. 기존 토큰 선택 방법은 단일 모달에 편향되거나 LLM 내부에서 고정 비율로 토큰을 제거해 교차모달 의존성의 진화를 포착하지 못한다. 제안은 층별 의존성 패턴에 기초해 단계적으로 토큰을 선택·삭제함으로써 성능 저하를 최소화하면서 FLOPs와 프리필 대기시간을 감소시킨다.
왜 중요한가
om-LLMs는 영상 프레임과 오디오 토큰을 텍스트 토큰과 결합해 멀티모달 추론을 수행한다. 다수의 비텍스트 토큰이 LLM 전체에 걸쳐 처리되면 계산량과 메모리 사용이 급증한다. 기존 토큰 선택 방법은 단일 모달에 편향되거나 LLM 내부에서 고정 비율로 토큰을 제거해 교차모달 의존성의 진화를 포착하지 못한다. 제안은 층별 의존성 패턴에 기초해 단계적으로 토큰을 선택·삭제함으로써 성능 저하를 최소화하면서 FLOPs와 프리필 대기시간을 감소시킨다.
핵심 기여
Block-wise layer 의존성 통찰
om-LLMs에서 시각/오디오 토큰 의존성은 층별로 블록 단위로 나타나며, 깊이가 증가할수록 의존성이 약해진다. 얕은 블록은 시각/오디오 토큰에 크게 의존하나, 중간 블록에서 감소하고, 말단 블록에서는 비텍스트 토큰의 필요성이 거의 없어지는 경향이 있다.
SEATS: training-free stage-adaptive token selection
pre-LLM에서 diversity 기반의 window단위 토큰 선택, 중간 LLM 층에서 쿼리 관련 토큰 선택과 상향식 예산 배분, 말단에서 비텍스트 토큰의 완전 제거를 결합하는 무훈련 모듈로 구성된다.
Stage-wise TRR Decay Schedule
Shallow 블록은 TRR를 유지하고, Middle 블록은 점진적으로 감소하는 TRR를 적용하며, Late 블록은 더 큰 감소를 허용하거나 0으로 설정한다. Ls, Lm1, Lm2, Ll로 구분된 3개 중간 서브블록에서 지수적 감소를 적용해 초반에는 약하고 후반에는 더 강하게 토큰을 prune한다.
Top-down budget allocation across windows and modalities
쿼리 관련 점수에 기반해 윈도우 간 예산을 할당하고, 윈도우 내부에서 시각/오디오 모듅에 대해 비율을 재할당한다. 이를 통해 윈도우별, 모달리티별 중요도에 맞춘 토큰 보존 비율을 조정한다.
강건한 실험적 검증
Qwen2.5-Omni-7B 및 Qwen3-Omni-30B에서 5개 오디오-비주얼 벤치마크에 대해 full-token 대비 성능을 유지하면서 FLOPs를 9.3× 감소시키고, 10% TRR에서 4.8× 프리필 속도향상을 달성했다. 35% TRR에서 평균 성능은 full-token 대비 최대치를 넘어섰으며, 35%에서 Qwen3-Omni-30B의 경우 55.4로 full-token 55.5에 근접했다.
핵심 아이디어 이해하기
단계별 의존성 변화에 따라 토큰 제거 전략을 다르게 설계한다. 1) pre-LLM 단계에서 window 단위로 시각/오디오 토큰의 다양성을 유지하며 중복을 제거한다. 2) LLM 내부에서는 층 구간을 얕은 블록/중간 블록/말단 블록으로 구분하고, 각 블록에 대해 TRR를 다르게 부여하는 block-wise decay 스케줄을 적용한다. 3) 모달리티 간 예산은 상향식(top-down)으로 윈도우 간 relevance 점수와 모달리티 간 교차 주의(attention) 점수를 바탕으로 재분배한다. 4) 말단 레이어에서 cross-modal fusion이 거의 완료되면 비텍스트 토큰을 모두 제거해 이후 텍스트 토큰만 처리하게 한다.
관련 Figure
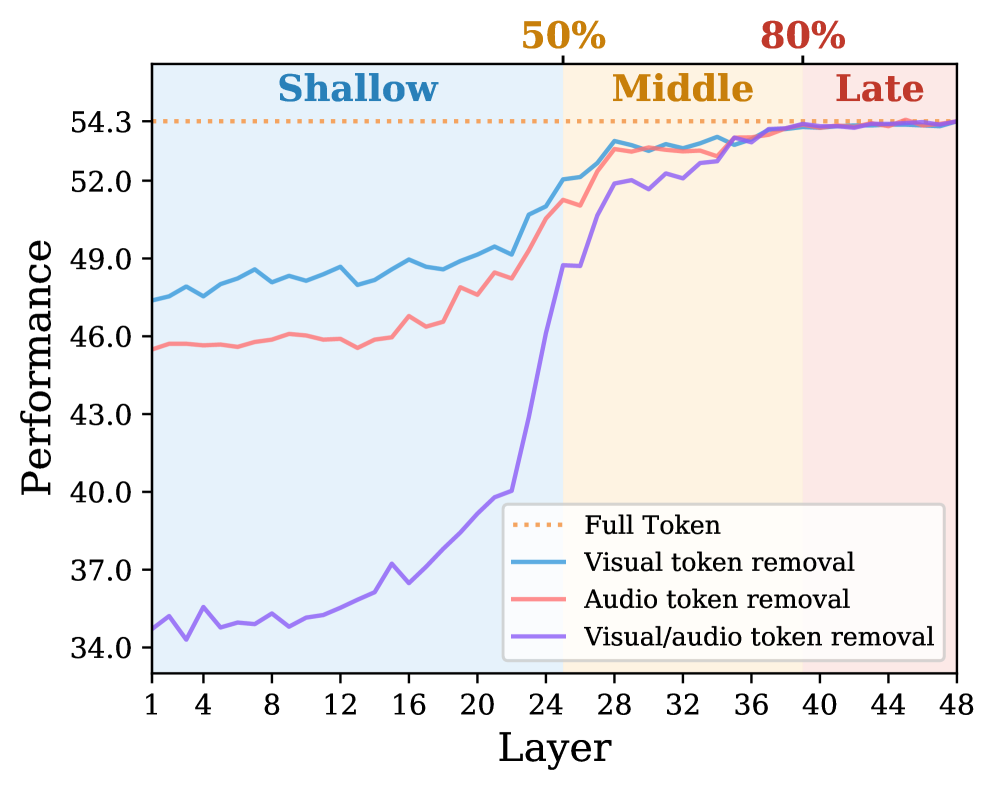
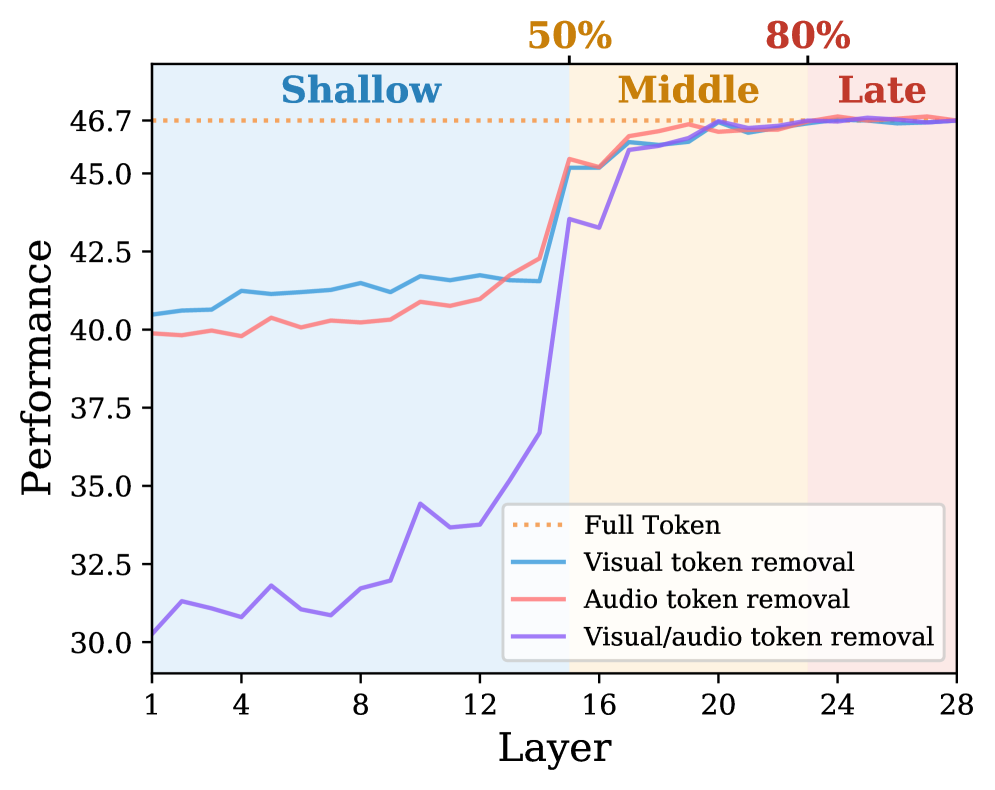
얕은 블록에서 시각/오디오 토큰 제거가 성능 저하를 크게 유발하고, 중간 블록에서 일부 회복되며, 말단 블록에선 큰 영향이 없다라는 블록-의존성 패턴을 보여준다.
Figure 2: 층별 TRR의 Shallow/Middle/Late 구간에서의 토큰 제거 영향
방법론
전략은 3단계로 구성된다. Step 1: Stage I. Pre-LLM token selection은 window 단위의 DivPrune를 확장한 winDivPrune로 구현되며, per-window per-modality 거리 행렬과 token의 attentions를 가중치로 사용한다. Step 2: Stage II. Inner-LLM token selection은 블록 구간(Ls, Lm1, Lm2, Ll)별 TRR를 설정하는 TRR decayschedule을 적용하고, inter-window budget allocation과 intra-window 재할당을 통해 Bt, Bt,v, Bt,a를 계산한다. Step 3: Query-guided token selection은 각 윈도우에서 query와 시각/오디오 토큰 간 cross-attention 점수를 이용해 Bt,v, Bt,a를 배정하고, 최종적으로 Bt,v 토큰을 선택한다. 끝으로 Late-Layers에서 Non-textual tokens를 제거한다.
관련 Figure
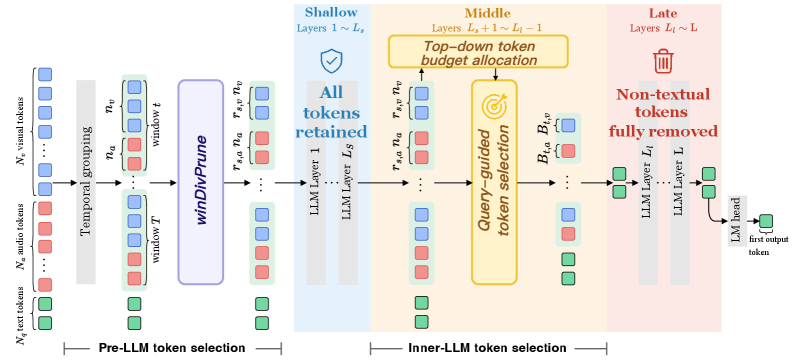
세 단계(SEATS의 파이프라인: Stage I Pre-LLM, Stage II Inner-LLM, Late Non-textual Removal)와 윈도우-기반/토큰 예산 할당 흐름을 시각적으로 제시한다.
Figure 3: SEATS의 Three-stage 구조 개요도
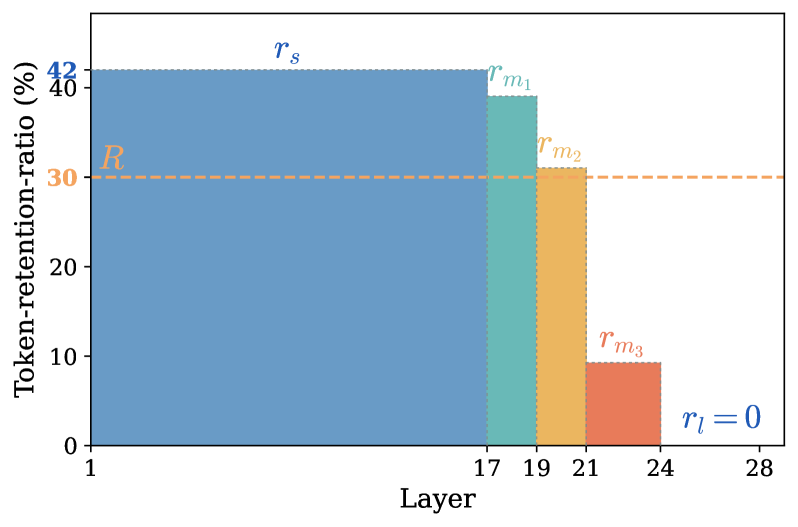
Layer별 TRR의 분해와 δ의 적용 예시를 보여주며, 3개의 Middle 서브-블록에서 TRR 감소가 적용되는 방식을 시각화한다.
Figure 4: LLM Layer별 TRR 분해와 예시(Qwen2.5-Omni-7B)
주요 결과
주요 벤치마크에서 SEATS는 full-token 대비 성능을 유지하면서 FLOPs를 크게 절감했다. Qwen2.5-Omni-7B에서 35% retention 시 평균 성능 49.3으로 full-token 48.7를 넘겼으며, 10% retention에서 평균 46.9로 full-token 대비 96.3%의 성능을 유지했다. 같은 설정에서 4.8× 프리필 속도향상 및 9.3× FLOPs 감소가 보고된다. 35% retention의 Qwen3-Omni-30B에서도 55.4로 full-token 55.5에 거의 근접했고, 10% retention에서도 53.0으로 부족 없이 큰 폭의 효율 향상을 보였다. Ablation 연구에 따르면 Stage II의 존재가 평균 성능 증가에 기여하며, Inter-/Intra-window 재할당의 결합이 성능을 최적화한다. Late-block에서 Non-textual Token 제거의 제거는 프리필 시간 증가를 야기하지만 최종 성능에 미미한 영향만 준다.
관련 Figure
이 도표는 SEATS가 낮은 토큰 선택 비용과 프리필 대기시간으로 더 나은 성능을 달성함을 시각적으로 보여준다. 10% TRR에서의 9.3× FLOPs 감소와 4.8× 프리필 속도향상 같은 수치를 직접 비교하는 근거가 된다.
Figure 1: Training-free token selection methods의 효율-성능 트레이드오프와 SEATS의 우수성
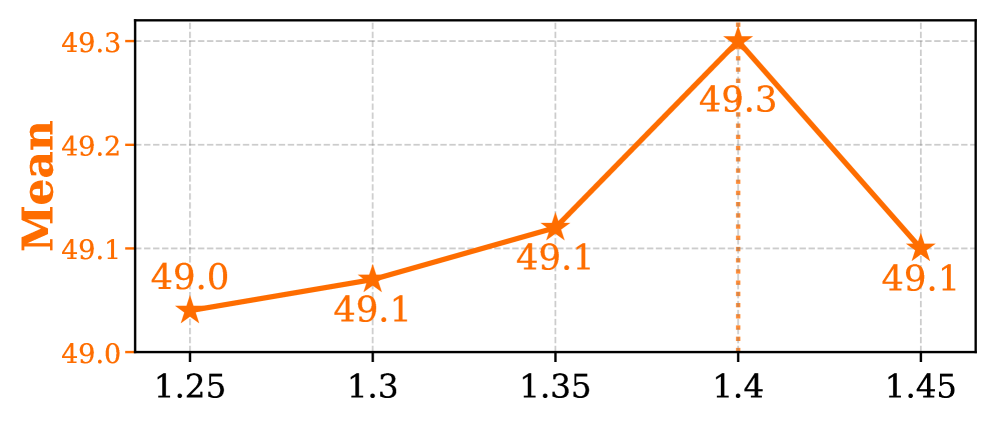
λ 값의 변화에 따른 성능 민감도 분석으로, 1.4 근처에서 최적의 평균 성능을 보임을 확인한다.
Figure 5: λ 하이퍼파라미터에 따른 Mean 성능 변화
기술 상세
Stage I에서 winDivPrune은 per-window per-modality 거리 행렬을 사용해 diversity와 saliency를 결합한 최대-최소 다양성 문제를 해결한다. rs,v와 rs,a는 각각 λ·Rv, λ·Ra로 설정되며, pre-LLM에서의 토큰 숫자는 rs,v·Nv + rs,a·Na로 감소한다. Stage II는 Ls, Lm1, Lm2, Ll로 구분된 3개 중간 블록과 Late 블록으로 구성되며, rm1, rm2, rm3은 δ의 지수적 감소를 적용해 TRR를 점진적으로 감소시킨다. δ는 (L − Llλ + λ)R/C의 형태로 계산되며 C는 상수이다. Inter-window token budget allocation은 각 윈도우 t의 St를 기반으로 Bt를 계산하고, intra-window는 Bt,v와 Bt,a를 St,v와 St,a 비율로 재할당한다. Query-guided Visual/Audio Token Selection은 Bt,v를 상위 Bt,v 토큰으로, Bt,a를 Bt,a 토큰으로 선택한다. Late 레이어에서 비텍스트 토큰 제거는 남아 있는 텍스트 토큰만 LLM Head로 전달한다.
한계점
현재 프레임워크는 백본에 의존하는 휴리스틱 하이퍼파라미터에 의존하며, 새로운 om-LLMs에 자동으로 적응하는 구성 및 스트리밍 추론 확장은 향후 연구 과제이다.
실무 활용
SEATS은 기존 om-LLMs에 플러그인처럼 적용 가능하며, 훈련 없이 단계적 토큰 선택으로 추론 비용과 메모리 사용을 대폭 줄인다.
- 리소스 제약 환경에서의 om-LLM 디플로이
- 실시간 비디오/오디오 분석 기반 응답 시스템
- 롱폼 비디오/오디오 질의응답 시스템에서의 효율적 인퍼런스
- 저지연형 멀티모달 챗봇 서비스
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.