TL;DR
상업용 AI 탐지기가 포스트-트레이닝Artifacts와 로컬 컨텍스트에 크게 의존한다는 실증적 패턴을 보인다. HIP는 베이스 모델을 패러프레이션 학습으로 재정의하고 이를 반복 적용해, 의미 보존을 유지하면서 탐지기의 인간화 판단에 더 잘 맞는 출력을 만들어낸다. 이러한 현상은 탐지기 설계가 텍스트의 기저 분포 변화에 더 민감해질 필요가 있음을 시사한다.
왜 중요한가
상업용 AI 탐지기가 포스트-트레이닝Artifacts와 로컬 컨텍스트에 크게 의존한다는 실증적 패턴을 보인다. HIP는 베이스 모델을 패러프레이션 학습으로 재정의하고 이를 반복 적용해, 의미 보존을 유지하면서 탐지기의 인간화 판단에 더 잘 맞는 출력을 만들어낸다. 이러한 현상은 탐지기 설계가 텍스트의 기저 분포 변화에 더 민감해질 필요가 있음을 시사한다.
핵심 기여
상업용 탐지기에서 베이스 모델의 출력이 인스트럭션 튜닝된 출력보다 더 인간적으로 평가된다는 실증 패턴 확인
GPTZero와 Pangram에서 human-prefix 조건 하에 Llama3-8B 및 Qwen3-8B의 베이스 모델 출력이 instruction-tuned 출력보다 인간으로 분류될 확률이 높은 현상을 관찰한다.
Detector-agnostic HIP 파이프라인 도입
데이터 준비, 최소 미세조정, 반복 패러프레이징의 3단계로 구성된 HIP를 제안하며, 베이스 모델의 이어쓰기 동작에 낮은 distortion을 유지하면서도 detector evasion 성능을 강화한다.
다양한 모델군에서 HIP의 일반화 확인
Qwen3-Base/Instruct, Llama3-Base/Instruct 등 4개 패밀리의 여러 사이즈에서 HIP가 의미 보존과 탐지 회피 간의 트레이드오프를 강건하게 개선함을 보인다.
탐지기 설계에 대한 시사점 제시
포스트-트레이닝 artifacts와 로컬 컨텍스트에 민감한 탐지기가 나타나므로, 향후 탐지는 이러한 요소를 모델링하는 방향으로 설계되어야 한다고 주장한다.
baselines 대비 HIP의 Ablation 비교
Simple Paraphrase, DIPPER, SilverSpeak, StealthRL 등과의 비교에서 HIP가 가장 강력한 semantic-evasion 대역을 형성하는 frontier를 달성함을 보인다.
핵심 아이디어 이해하기
단계1: 인간 텍스트에서 얻은 맥락(human prefix)이 AI 텍스트를 인간에 가깝게 보이게 한다는 관찰과, 단계2: 패러프레이저를 베이스 모델에 미세조정해 인간적continuation의 경향을 강화하는 것이 가능하다는 직관이 있다. 단계3: 반복/paraphrase를 통해 로컬 컨텍스트를 점진적으로 인간 쪽으로 재배치하면 detector의 인간성 평가점수를 높이되 의미 손실은 점차 누적될 수 있다. 이로써 탐지기는 인스트랙션 튜닝의 흔적과 포스트-트레이닝의 아티팩트에 의존하는 경향이 강화된다. HIP는 이 두 가지 직관을 실제 파이프라인으로 구현한다.
방법론
세 가지 단계의 접근법으로 구성된다. 1) Data Preparation: hi(인간 passage)와 ai(인공지능 패러프레이즈) 쌍을 D = {(ai, hi)}로 구성하며, Ccand→Cdedup→Cclean 순으로 전처리하고, ANOMALYFREE(a) 및 SEMANTICPRESERVATIONOK(a, h)를 만족하는 a만 D에 포함한다. 2) Minimal Fine-Tuning: Mbase를 미세조정해 Mpara를 얻고, 입력-출력 포맷은 <source_text> AI paraphrase a </source_text>와 <target_text> Original human passage h </target_text>를 사용한다. 손실은 completion span에만 적용한다. 3) Iterative Paraphrasing: x(0)에서 시작해 N=10 라운드동안 p(t) = FORMATASPROMPT(x(t-1))를 통해 x(t)를 Mpara로 생성하여, x(N)까지 반복하며 의미 보존과 인간화의 트레이드오프를 얻는다.
관련 Figure
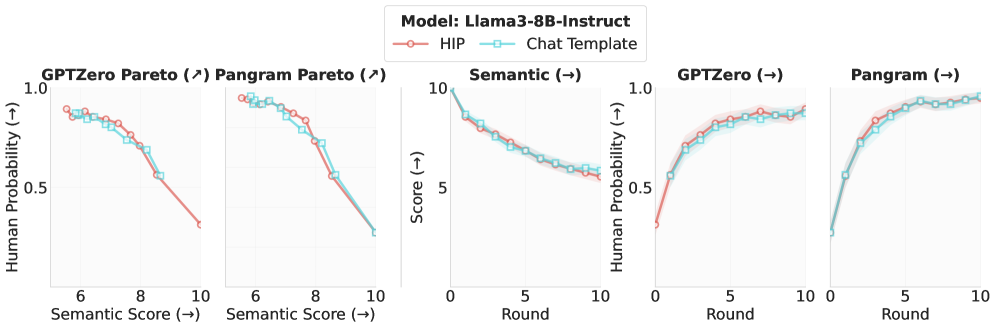
비교를 통해 HIP의 효과가 채택된 템플릿의 차이에 크게 의존하지 않음을 보이나, Instruct+HIP 및 Instruct+FT 컨트롤의 패널에서 탐지기 인간성 지표의 회복이 관찰된다.
Instruct 모델에서 HIP 대 n-템플릿 비교를 다루는 그림으로, HIP의 네 가지 구성요소를 native chat template과 비교한다.
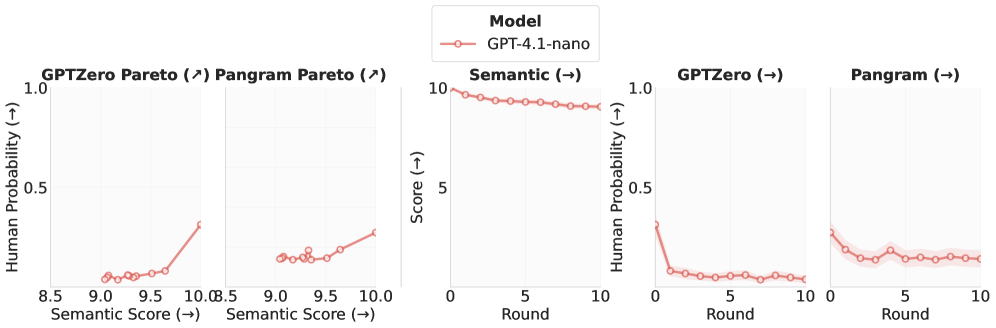
OpenAI API 기반 HIP의 트레이드오프는 오픈-Weight 모델에서와 달리 제한적 효과를 보인다. semantic 보존은 높게 유지되나 detector-human probability은 크게 향상되지 않는다.
HIP on OpenAI GPT-4.1-nano의 파인튜닝 API 실험 결과를 보여주는 도표.
주요 결과
주요 벤치마크에서 HIP는 베이스/인스트럭트 양쪽에서 detector human-probability를 상승시키고, 반대로 semantic score는 둔화된다. Four model families(Qwen3-Base, Llama3-Base, Qwen3-Instruct, Llama3-Instruct)에서 HIP는 baselines보다 더 강력한 트레이드오프를 보이고, 라운드가 진행될수록 인간성 점수가 증가하는 경향을 보인다. Ablation: Instruct + HIP 및 Instruct + FT는 현재 OpenAI API에서의 HIP가 동일한 효과를 재현하지 못했다. HIP on Instruct 모델의 native chat template과의 비교에서도 큰 차이가 없었다. output-layer-only adaptation은 HIP의 주된 효과를 재현하지 못했다.
관련 Figure
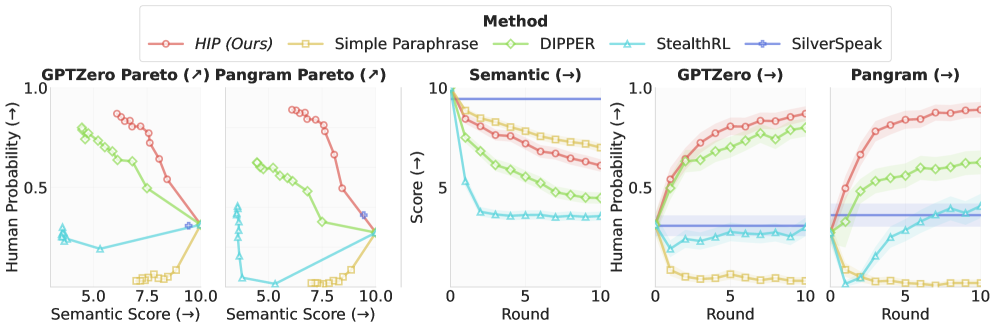
패널은 각 모델군에서 HIP가 의미 보존과 탐지기 인간성 사이에서 어떤 트레이드오프를 형성하는지 시각적으로 보여준다. 이에 따라 HIP가 여러 모델 크기에서 일반화될 수 있음을 확인한다.
HIP across model families를 보여주는 다패널 도표로, GPTZero/Pangram의 인간 확률과 의미 보존 점수를 교차시키는 Pareto 프론티어를 제시한다.
기술 상세
전체 아키텍처: base model(Mbase) → paraphraser(Mpara)로의 경량화된 파인튜닝. 데이터 준비: hi, ai 쌍 형성, D={(ai, hi)}. 학습 형식: <source_text> AI paraphrase a </source_text> <target_text> Original human passage h </target_text>, completion만 손실에 포함. 학습 하이퍼파라미터: 1 에폭, max_seq_len=2048, batch_size=16, lr=5e-5, LoRA 랭크128, 스케일 128, dropout 0.05; 70B 모델에 대해서는 QLoRA 사용. Inference: vLLM, N=10 회 반복. 평가: semantic preservation은 GPT-5-nano로 0-10 스케일로 점수화, GPTZero/Pangram으로 human-likeness 평가. Continuation evaluation에서 human-prefix와 AI-prefix를 구분해 비교. Baselines: Simple Paraphrase, DIPPER, SilverSpeak, StealthRL.
관련 Figure
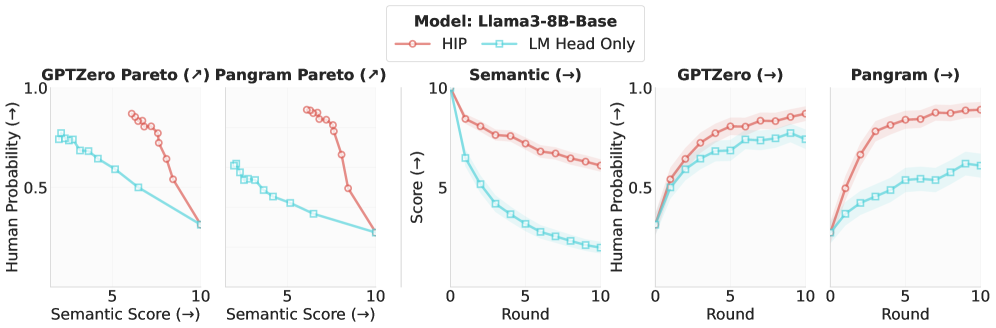
출력층만의 적응은 HIP 주 효과를 재현하기 어렵고, 특히 Qwen3-8B에서 의미 보존이 상대적으로 높은 반면 탐지기 인간성은 부족하여 본 연구의 주요 메커니즘이 깊은 표현 학습에 의존함을 시사한다.
HIP with Output-Layer-Only Adaptation의 비교 도식. 로지트 맵의 출력층만 적응한 경우의 트레이드오프를 보여준다.
한계점
OpenAI API를 통한 HIP 전이 결과는 메인 오픈-Weight 모델과 차이가 있으며, Instruct 모델에서의 HIP 일반화가 제한적이다. OpenAI Fine-Tuning API를 통한 HIP는 동일한 낮은 distortion을 달성하지 못한다는 점이 확인된다.
실무 활용
HIP의 인간화 패러프레이징은 탐지 회피 연구와 탐지기 설계 방향에 중요한 시사점을 제공한다. 실무적으로는 탐지 회피를 위한 수단으로 악용될 수 있으나, 탐지기 취약성 진단 및 방어 방향 설정에 활용 가능하다.
- 탐지기 강건성 연구에서 포스트-트레이닝 효과를 재현하고 개선 방향을 탐색
- LLM 감지 회피에 대한 방어 모델 설계 시 인간-맥락 의존성 최소화 전략 평가
- 교육/검증 맥락에서 베이스 모델과 인스트럭트 모델의 차이 분석을 위한 프롬프트 설계
- 대화형 시스템의 안전성 평가에서 인간-유사성과 기계-생성 간 차이 분석
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.