TL;DR
저자 식별은 프리트레이닝된 백본이 스타일 특성을 선형적으로 읽을 수 있게 구성되어 있음에도, 이를 해석하는 읽기 방식의 차이가 AA 성능 차이를 만들어낸다. 본 연구는 availability–use 이분화를 통해 encoder가 이미 정보를 보유하고 있지만, 어떤 스코어링이 이를 언제 어떤 깊이에서 활용하는지가 핵심 문제임을 보인다. LI/PLI 계열은 더 깊은 층에서 신호를 활용하도록 허용하여 mean pooling 대비 성능을 크게 끌어올리는 경향이 확인된다.
왜 중요한가
저자 식별은 프리트레이닝된 백본이 스타일 특성을 선형적으로 읽을 수 있게 구성되어 있음에도, 이를 해석하는 읽기 방식의 차이가 AA 성능 차이를 만들어낸다. 본 연구는 availability–use 이분화를 통해 encoder가 이미 정보를 보유하고 있지만, 어떤 스코어링이 이를 언제 어떤 깊이에서 활용하는지가 핵심 문제임을 보인다. LI/PLI 계열은 더 깊은 층에서 신호를 활용하도록 허용하여 mean pooling 대비 성능을 크게 끌어올리는 경향이 확인된다.
핵심 기여
Availability–use dissociation in AA
저자들은 스타일릭 특성이 encoder의 모든 층에서 선형적으로 읽히는 반면, scoring mechanism이 이를 읽는 깊이와 형태를 좌우함을 입증한다. 프리트레이닝 백본은 동일하지만, 출력 스코어링 방식에 따라 정보의 활용이 달라진다.
Scoring mechanism determines consolidation depth
mean pooling은 중간층에서 저자 신호를 응집하고, Late Interaction(LI) 및 Patch-level LI(PLI)는 나중 층으로 신호 consolidation을 연기한다. 이는 gradient 구조의 차이와 학습 역학으로 설명된다.
Gradient structure explains readout differences
End-to-end LISA 분석에서 mean pooling은 모든 토큰에 고르게 그라디언트를 전달하는 dense gradient를 가지며, LI는 선택된 토큰에만 그라디언트를 전달하는 sparse gradient를 보인다. PLI는 patch 단위에서 중간 정도의 밀도를 갖는다.
Residual stream patching locates consolidation points
Residual stream patching을 통해 각 layer를 고정한 상태에서 신호 회복을 측정하고, mean pooling은 layer 10에서, LI는 16-17에서, PLI는 15에서 consolidation이 발생함을 확인한다.
Training dynamics reveal distinct learning trajectories
8개의 체크포인트에서의 분석은 mean pooling이 위상적으로 상향-하향으로 깊이에 따라 신호를 축적하는 반면, LI는 초기에는 얕은 신호에 의존하다가 상위 층으로 이동하고, LI/PLI의 고유 경로가 확인된다.
관련 Figure
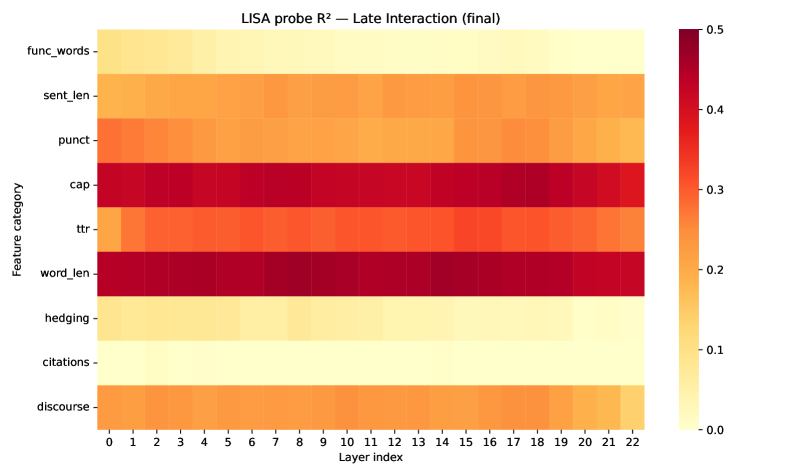
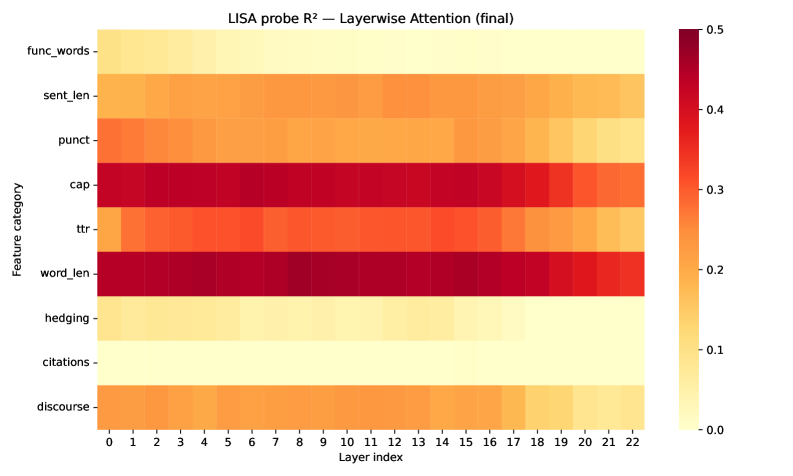
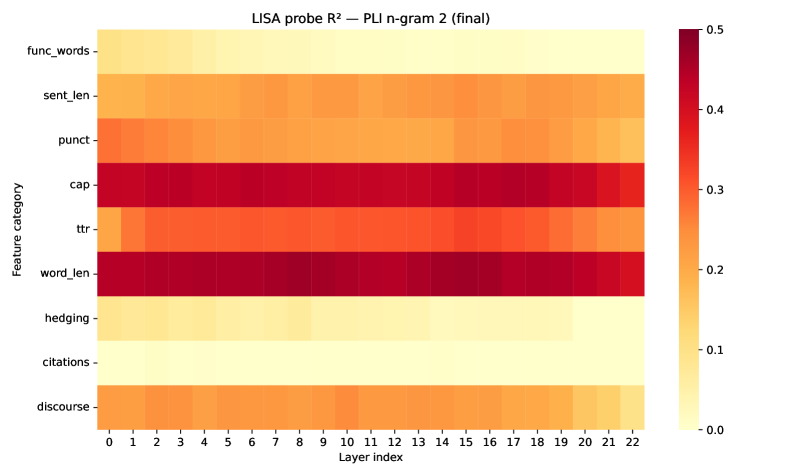
레이어별 스타일 특성의 선형 가용성을 시각화한 히트맵. word_len, cap, punct, fw 등 상위 특징의 선형 가용성은 모델 간 차이가 작다.
Figure 3: LISA probe R² heatmaps (final)
핵심 아이디어 이해하기
- 프리트레이닝된 백본은 저자 stylistic feature를 모든 층에서 읽을 수 있도록 이미 인코딩한다. 2) 하지만 AA의 성능 차이는 encoder가 학습하는 정보가 아니라 scorer가 그 정보를 얼마나, 어디에서 읽어내는지에 달려 있다. 3) mean pooling은 모든 토큰의 정보를 합쳐 단일 벡터로 스코어링하기 때문에 consolidation bottleneck가 발생하고, LI/PLI는 토큰 단위로 정보를 보존하기 때문에 더 깊은 계층까지 신호를 활용할 수 있다. 4) gradient 분포의 차이가 초기 학습 경로를 결정하고, 이는 학습 역학에서 서로 다른 트랙을 만든다. 5) 실험은 depth 프로파일과 patching, 스코어링 유형 간의 일관된 차이를 확인한다.
관련 Figure
세 가지 읽기 경로(Pretrained encoder, Single-token Scoring, Causal Depth Profile)가 도식으로 제시되어 availability-use 이론의 시각적 근거를 제공한다.
Figure 1: Encoder-Reader 구조와 CA 깊이 프로파일의 개념적 개요
방법론
전체 접근은 백본(ModernBERT-base) 하나, 코퍼스 하나, 손실 함수 하나를 공유하는 컨트롤된 설정에서 세 가지 스코어링 메커니즘을 비교하는 것부터 시작한다. 스코어링은 Mean pooling with cosine similarity, Late interaction(LI, 토큰-수준 MaxSim), Patch-level late interaction(PLI, n=2)로 구성된다. 학습은 InfoNCE 손실을 최소화한다: L = − log exp(s(a,p)/τ) / (exp(s(a,p)/τ) + ∑ exp(s(a,n′)/τ)). Layerwise hypernetwork를 통해 각 층에서의 가중치를 사용하여 레이어별 Availability를 측정한다. 2) Residual stream patching을 도입해 각 layer를 교체하는 실험을 수행하고, Recovery(ℓ) = (s(ℓ)patched − scorrupt) / (sclean − scorrupt) × 100으로 회복률을 정의한다. 3) LISA probes를 도입해 layer별 R2를 측정하고, 단일 벡터 대비 토큰-레벨 정보를 확인한다. 4) 트레이닝 다이나믹스는 8개 체크포인트에서의 패턴을 분석한다. 5) 148개의 probe triplets로 Tier A/B/C를 구성해 patching 실험의 일반성을 확인한다.
관련 Figure
Tier A/B/C에서 토큰 길이 분포를 보여 주며, 전체가 약 130토큰 주위로 군집한다. 이 분포는 제어된 probe 세트 구성을 설명한다.
Figure 2: Probe Set Token Length Distribution
주요 결과
메인 벤치마크는 mean pooling이 R@20 0.121, R@100 0.294, nDCG@20 0.063, nDCG@100 0.101인 반면 LI는 0.485/0.678/0.364/0.408로 우수하다. PLI n=2는 0.497/0.700/0.365/0.411로 LI와 비슷한 성능을 보인다. E5(제로샷) 대비 차이가 크다. LISA probes는 word length, capitalization, type-token ratio, punctuation density가 가장 잘 읽히며, 모델 간 차이가 미미하다. Rank recovery 분석에서 Tier A의 mean pooling은 약 layer 9에서 chance를 넘고, LI/PLI는 layer 14–16에서 초고속 회복에 도달한다. consolidation point는 mean pooling에서 layer 10, LI/PLI에서 16/15로 확인된다. 점수 민감도 분석에서 LI가 가장 민감하고, PLI가 중간, mean pooling은 가장 낮다. training dynamics 분석에서 mean pooling은 상단에서 하향으로 학습이 확산되며, LI는 초기에는 낮은 층의 얕은 특징에 의존하다가 상위 층으로 이동한다. PLI는 중간층의 허브를 통해 신호를 축적하는 경향을 보인다.
관련 Figure
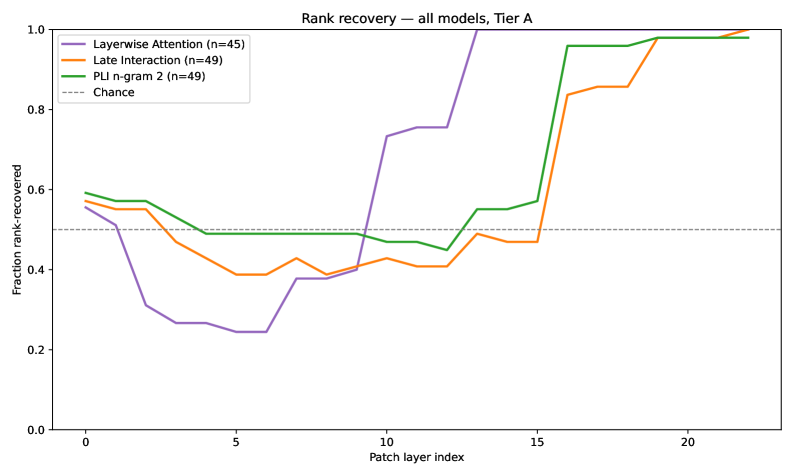
Tier A에서 mean pooling은 layer 9 근처에서 회복 시작, LI/PLI는 14–16 부근에서 회복 시작으로 깊이 차이를 보임. 이는 컨솔리데이션 깊이가 스코어링에 의해 좌우됨을 시사한다.
Figure 4: Rank recovery across the three models (Tier A).
LI가 가장 민감하고, PLI가 중간, mean pooling이 가장 낮다. 레이어별 점수 변화의 크기를 통해 읽기 방식에 따른 영향력을 비교한다.
Figure 5: Score sensitivity per layer
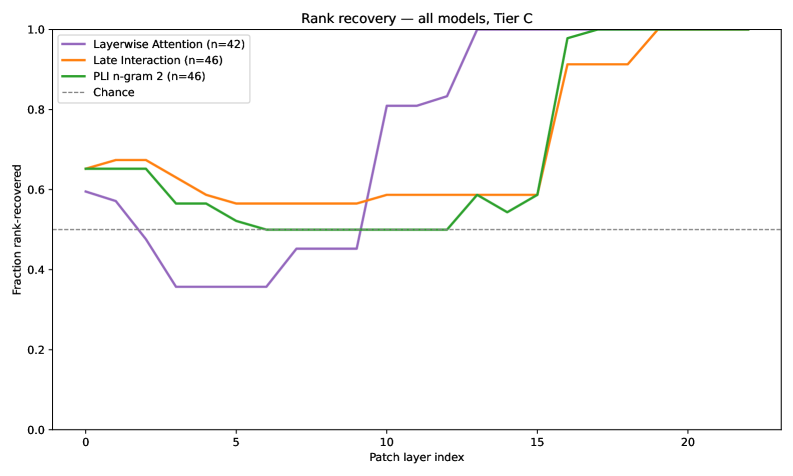
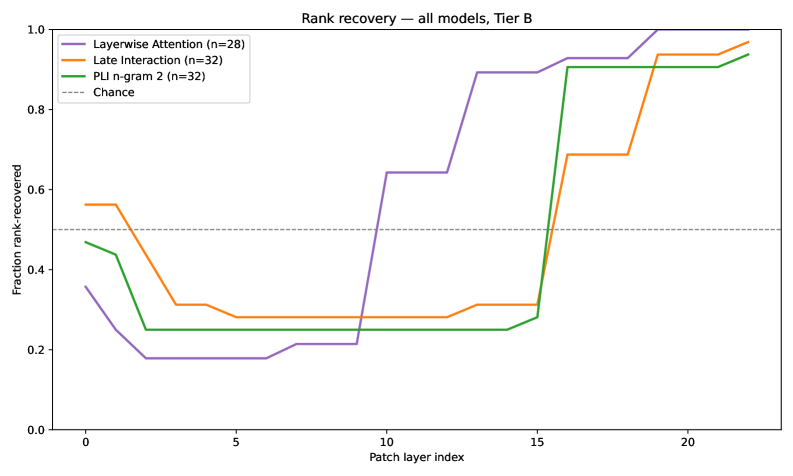
Tier별 추가 비교를 통한 일관된 깊이-읽기 패턴 확인. Tier B의 hard-confound은 더 큰 실패율로 나타나므로 LI/PLI의 강인성을 강조한다.
Figure 7: Rank recovery (Tier A/B/C) across models
기술 상세
아키텍처: ModernBERT-base 백본(23층, 768 차원, 149M 파라미터). 입력으로 문장 triplets(a, p, n) 사용. encθ: a, p, n의 토큰 표현 Ha = [ha1, ..., ham]. s(a, p)와 s(a, n) 간의 점수를 산출. 스코어링 함수 세 가지: 1) Mean pooling: 각 토큰 임베딩의 평균을 내고 코사인 유사도로 점수 산출. 2) LI: anchor 토큰 j에 대해 각 i에 대해 cos(ha_j, hp_i)의 최대값을 합산. 3) PLI: 패치 단위로 토큰을 n=2 빔으로 묶고 각 패치에서 mean-pooled 패치와 LI를 결합해 점수 산출. 손실은 InfoNCE; τ는 온도 하이퍼파라미터. Residual stream patching: clean/patched/corrupted 패스를 통해 각 layer ℓ에서의 회복도 Recovery(ℓ) 및 Rank 회복을 계산. Rank 회복 임계치를 0.75로 정의하고 consolidation point를 layer 9(Mean pooling), 16(LI), 15(PLI)로 설정. LISA probes: 9가지 스타일 특성에 대해 layer별 R2를 측정. 학습 역학은 8개 체크포인트에서의 patching 결과를 분석하고, 세 가지 학습 경로를 도출한다. 3가지 스코어링 간의 gradient 분포 차이로 인해 깊이-의존성이 달라진다.
한계점
백본을 ModernBERT로 고정하였고, 다른 아키텍처에서의 Inflection 레이어 위치는 달라질 수 있다. PLI의 패치 크기(n=2)만 분석했으며, n=3 이상에 따른 경향은 추가 연구 필요.
실무 활용
저자 신호의 가용성과 활용 차이를 분리하면, AA 시스템의 설계에서 어떤 scorer를 선택하느냐가 성능에 결정적임을 보여준다. 프리트레이닝 백본은 stylistic features를 이미 제공하지만, 읽는 방식이 달라져 실제 성능 차이를 만든다.
- AA 시스템 설계 시 LI/PLI 기반 읽기 경로를 채택하여 긴 텍스트에서 저자 신호를 더 효과적으로 활용
- 스타일 기반 피처를 선형 탐지기로 평가해 모델의 해석 가능성 향상
- 트레이닝 다이나믹스를 참고해 컨트랄리티에 맞는 스코어링 전략 선택
- 컨트롤 백본으로 프리트레이닝된 모델의 일반화 시험 및 계층별 정보 활용성 비교
코드 공개 여부: 공개
코드 저장소 보기키워드
추가 이미지 분석
각 모델의 체크포인트에서의 회복률 변화를 시각화. Mean pooling은 상단에서 시작해 점차 깊은 층으로 확산, LI는 초기 shallow 신호에서 시작해 상위 층으로 이동, PLI는 중간층 허브를 형성하는 경향을 보인다.
Figure 6: Training dynamics
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.