TL;DR
현대의 멀티모달 대형언어모델은 대부분 오프라인 설정에서 평가되어 실시간으로 입력이 진행되는 맥락에서의 반응과 타이밍을 검증하기 어렵다. Omni-DuplexEval은 Real-Time Description과 Proactive Reminder의 두 시나리오를 통해 비디오 스트리밍이 진화하는 과정에서 모델이 지속적으로 응답하고, 언제 응답할지 결정하며, 응답 내용을 일관되게 제시하는 능력을 함께 평가한다. 현재 모델은 사람과 비교해 응답 타이밍과 내용의 전반적 일관성에서 큰 격차를 보이며, 실세계의 대화형 에이전트로서의 신뢰성 향상을 위해선 타이밍 판단과 내용 생성의 균형이 필요하다고 분석된다.
왜 중요한가
현대의 멀티모달 대형언어모델은 대부분 오프라인 설정에서 평가되어 실시간으로 입력이 진행되는 맥락에서의 반응과 타이밍을 검증하기 어렵다. Omni-DuplexEval은 Real-Time Description과 Proactive Reminder의 두 시나리오를 통해 비디오 스트리밍이 진화하는 과정에서 모델이 지속적으로 응답하고, 언제 응답할지 결정하며, 응답 내용을 일관되게 제시하는 능력을 함께 평가한다. 현재 모델은 사람과 비교해 응답 타이밍과 내용의 전반적 일관성에서 큰 격차를 보이며, 실세계의 대화형 에이전트로서의 신뢰성 향상을 위해선 타이밍 판단과 내용 생성의 균형이 필요하다고 분석된다.
관련 Figure

질의의 언어적 특성과 응답의 다양성에 대한 힌트를 제공한다.
단어구름 형태의 키워드 시각화
질의의 다양성과 응답의 표현 범위를 시각적으로 보여준다.
다중 축 워드클라우드 예시
콘텐츠 다양성과 시간-정합성 평가의 시각적 맥락을 제공한다.
another word cloud visualization emphasizing 임베딩/콘텐츠 관련 용어
핵심 기여
시나리오 기반 벤치마크 설계
Real-Time Description과 Proactive Reminder의 두 가지 대표 시나리오로 구성되며, 각 시나리오는 9개 과제로 나뉘고 총 660개의 비디오와 시간대별 주석으로 구성된다.
자동 평가 프레임워크(LLM-as-a-Judge)
응답의 의미적 정확성과 시간적 정합성을 공동 평가하는 프레임워크를 제안한다. 콘텐츠 일치성과 시간 민감성을 각각 평가하고 가중치를 부여해 최종 점수를 산정한다.
데이터 셋 및 주석 설계
비디오 660개, 오디오-비주얼 스트림, 오픈형 질의 형태의 질문, 시간대별 정밀 주석 및 ground-truth 응답이 포함되며, Real-Time Description과 Proactive Reminder 각각에 맞춘 ground-truth이 제공된다.
현대 듀플렉스 MLLMs의 성능 분석
LiveCC-Base, StreamingVLM, LiveCC-Inst, MMDuet2, MiniCPM-o 4.5 등 주요 모델의 듀플렉스 성능을 평가하고, 인간 대비 격차를 정량화한다. 최상위 모델도 Avg 39.6에 그치며 Proactive Reminder에서 20.0에 머무른다.
실시간 듀플렉스의 한계 분석
완전성-시기성(trade-off)과 언제/무엇을 말할지 결정하는 문제 등 두 가지 핵심 도전과제를 확인한다.
핵심 아이디어 이해하기
실시간 멀티모달 시스템은 입력이 지속적으로 흐르는 스트림이며, 모델은 특정 시점에서의 요구에 맞춰 응답을 생성해야 한다. 본 논문의 핵심은 이러한 '시간-민감성'과 '콘텐츠 일치성' 두 축에서의 성능 평가를 하나의 프레임으로 통합하는 것이다. Real-Time Description은 비디오 및 오디오의 연속적 변화를 따라가며 지시와 일치하는 연속적 응답을 생성하는 능력을 요구하고, Proactive Reminder는 스트리밍 신호를 모니터링하여 이벤트 발생 시점에 적절한 응답을 생성하는 능력을 평가한다. 이를 위해 four-window 샘플링, 다중 모달 맥락 추출, 의미 재현 여부 판단 등 다단계 평가 파이프라인을 도입하고, LLM-as-a-Judge를 통해 시퀀스 단위의 타임스탬프 기반 점수를 산정한다. 실험 결과, 현시점의 듀플렉스 MLLMs는 Real-Time Description에서 충분한 전체 맥락 반영과 시점 맞춤성을 모두 달성하지 못하고, Proactive Reminder에서도 적시에 응답하는 능력이 크게 부족하다. 이로써 실세계의 대화형 멀티모달 시스템 구현에 필요한 시간-정합성 균형의 중요성을 확인한다.
관련 Figure

태스크 간 관계를 시각화하며, 각 태스크가 Real-Time Description의 핵심 요구사항에 어떻게 기여하는지 보여준다.
Real-Time Description의 6개 하위태스크를 구분하는 트로피 계층 구조
방법론
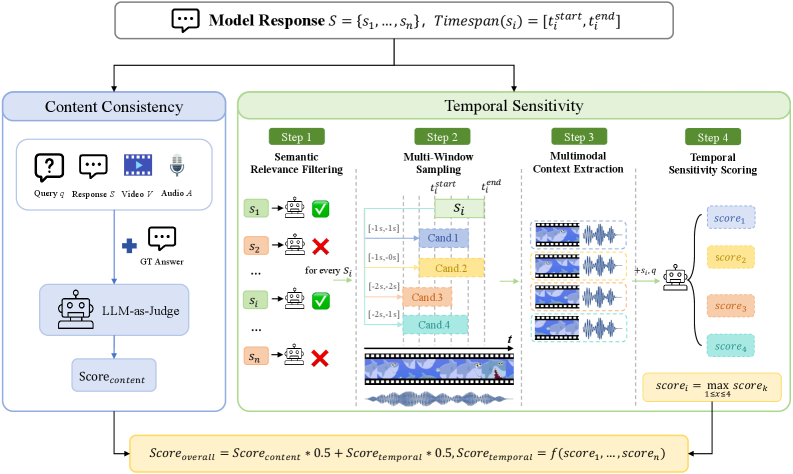
전체 접근 방식은 두 가지 핵심 시나리오를 구성하는 벤치마크 설계에서 시작한다. Real-Time Description은 비디오가 진행되는 동안 연속적이고 시점에 맞춘 응답을 생성하도록 요구하며, Proactive Reminder는 이벤트 발생 시점을 감지하고 적절한 응답을 생성하도록 요구한다. 데이터세트 구성은 다양한 온라인 소스의 비디오를 수집해 품질과 다양성을 확보하고, 각 샘플에 대해 Real-Time Description의 6개 하위태스크(Counting, Interaction Relation, Omni, World Knowledge, OCR, Fine-grained Movement)와 Proactive Reminder의 3개 태스크를 포함한다. 평가 파이프라인은 Step 1 Semantic Relevance Filtering, Step 2 Multi-Window Sampling, Step 3 Multimodal Context Extraction, Step 4 LLM 평가로 구성되며, Real-Time Description의 경우 Content Consistency과 Temporal Sensitivity를 통해 문장 단위의 흐름과 시점 정합성을 모두 평가한다. Proactive Reminder는 이벤트 타임스탬프 이후 10초 내 응답의 성공 여부와 응답의 적합성(Instruction-compatibility)을 평가한다. 실험은 4개의 벤치마크 모델(LiveCC-Base, StreamingVLM, LiveCC-Inst, MMDuet2, MiniCPM-o 4.5)을 대상으로 수행되며, GPU는 NVIDIA A100 시스템에서 단일 장비로 실행했다. Calibrations은 인간 평가와의 Spearman 상관을 활용해 자동 평가를 보정했고, 최종 프레임워크는 Content Consistency와 Temporal Sensitivity를 0-3 스케일로 측정 후 0-100으로 매핑한다.
관련 Figure

이 도식은 Real-Time Description과 Proactive Reminder 두 시나리오를 직관적으로 연결하며, 데이터 흐름과 벤치마크의 구성 요소를 한눈에 보여준다.
Omni-DuplexEval의 오프라인 대 온라인 평가 비교를 시각화한 도식
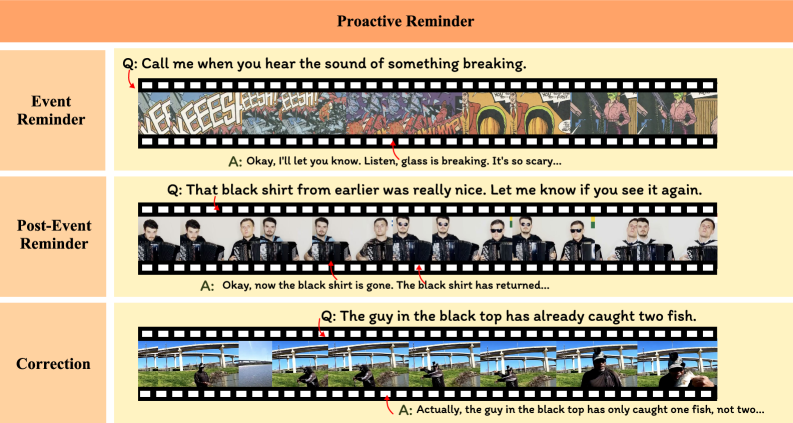
이 도표는 이벤트 발생 시점에서의 응답과 수정 응답의 흐름을 보여주며, Proactive Reminder의 평가 포인트를 강조한다.
Proactive Reminder의 이벤트-, 후속 이벤트- 및 수정 태스크 예시
주요 결과
주요 결과는 다음과 같다. Real-Time Description과 Proactive Reminder 두 시나리오의 모델 성능을 합산한 Avg에서, 인간-듀플렉스(Human-Duplex) 대비 모든 모델이 큰 격차를 보였다. 최상위 모델인 MiniCPM-o 4.5의 Avg 점수는 39.6으로, 인간의 81.8에 비해 현저히 낮다. Real-Time Description의 하위 태스크별 성능은 CT, IR, Omni, WK, OCR, FM 순으로 평가되며, 인간 오프라인의 평균은 83.0으로 나타났고 인간-듀플렉스의 Avg는 70.8이다. Proactive Reminder의 경우 ER, PER, CR의 합산 평균은 각각 100.0, 100.0, 100.0으로 인간 오프라인의 최고치와 비교해 훨씬 낮다. 실험은 또한 Temporal Sensitivity에서 인간-오프라인의 평균이 약 84.3, Counterpart 벤치마크의 평균은 34-60대에 분포하는 등 모델의 시간적 정합성에 큰 한계가 있음을 보여준다. 더 나아가, 자동 평가 프레임워크와 인간 평가 간의 상관관계는 Content Consistency에서 0.9 이상, Temporal Sensitivity에서 약 0.8에 이르는 높은 정렬성을 보였다. 이에 따라 모델은 실시간 비디오의 전체 맥락을 포착하는 능력보다, 시점에 정확하게 반응하는 능력이 취약하다는 결론이 도출된다. 또한 Proactive Reminder에서 No Answer 비율이 커지는 경향이 있으며, 이는 응답 트리거링의 미흡이 큰 문제임을 시사한다.
관련 Figure
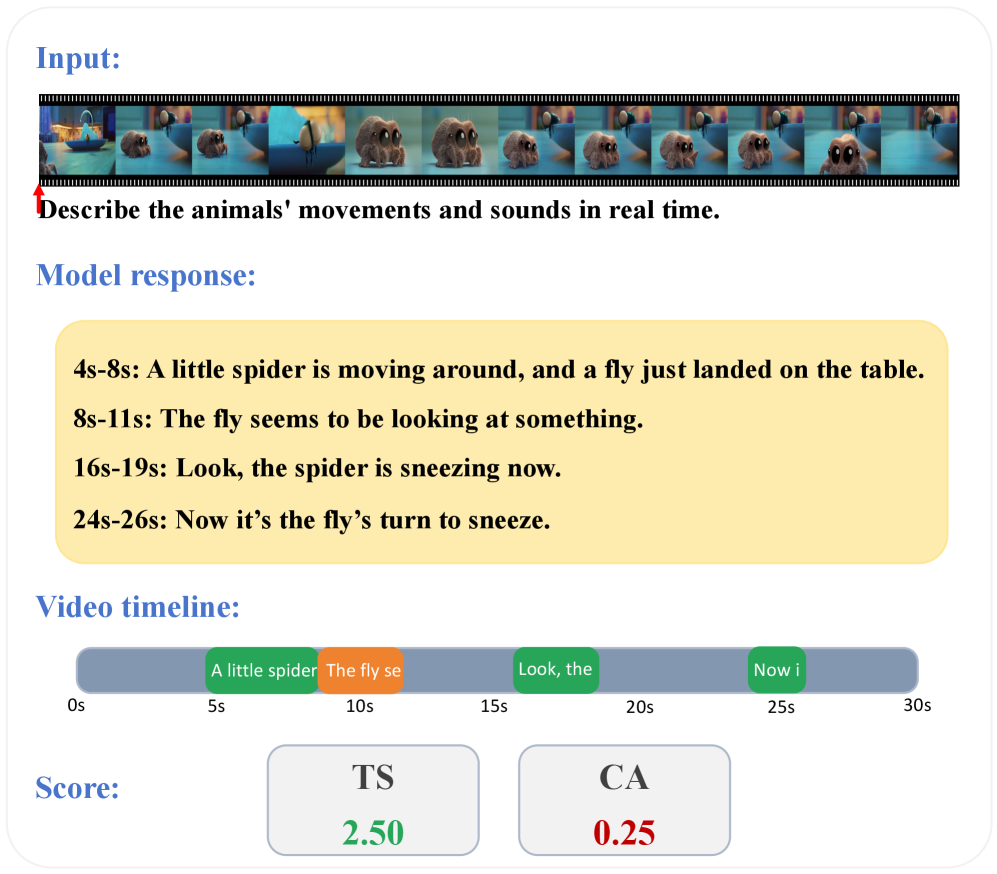
각 타임스탬프에서의 모델 응답과 Ground-Truth의 비교를 시각적으로 제시하여 시점 정합성의 어려움을 강조한다.
Real-Time Description의 태스크별 예시 응답 흐름
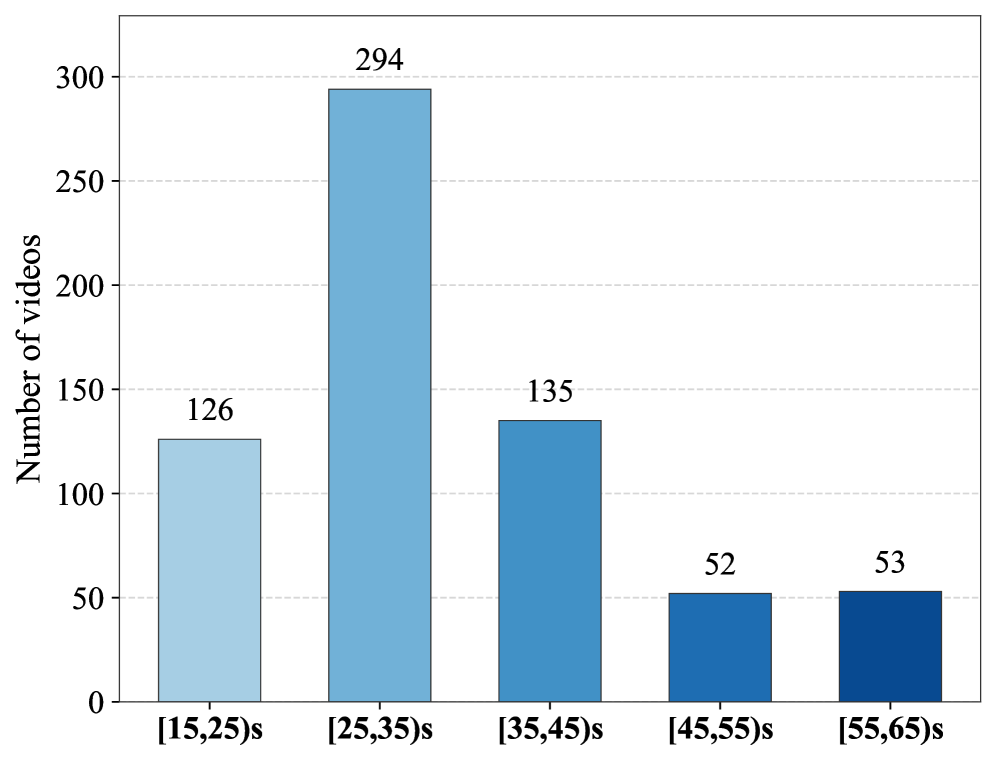
샘플의 다양성과 실세계 적용 가능성을 시각화하며 벤치마크의 일반화 가능성을 뒷받침한다.
데이터셋의 특성(비디오 길이 분布, 카테고리 분포, 텍스트 질의의 어휘 특성)
기술 상세
Real-Time Description과 Proactive Reminder의 두 시나리오를 기반으로 하는 아키텍처. Real-Time Description의 경우 6개 하위 태스크(Counting, Interaction Relation, Omni, World Knowledge, OCR, Fine-grained Movement)로 구성되며, 각 문장 s_i는 시간 구간 [t_start_i, t_end_i]에 매핑된다. 평가 파이프라인은 4단계로 구성된다: (1) Semantic Relevance Filtering으로 불필요한 문장을 제거, (2) Multi-Window Sampling으로 2초 간의 지연 보정 범위를 고려한 4개의 윈도우에서 가장 높은 LLM-평가 점수를 선택, (3) Multimodal Context Extraction으로 프레임/오디오를 샘플링, (4) Temporal Sensitivity 점수 산정 및 Content Consistency와의 가중합으로 최종 Score를 0-100으로 매핑한다. Temporal Sensitivity는 S_rel의 각 문장에 대해 window별 정합도를 LLM으로 평가하고, Irrelevant Sentence 비율 r과 지연 보정 인자 λ를 반영해 최종 점수를 산출한다. Proactive Reminder는 이벤트 타임스탬프 tevent 이후 10초 이내의 응답 세그먼트를 LLM-판정자에게 평가하게 하며, 각 이벤트별로 점수를 합산해 샘플 레벨 점수를 산출한다. Calibration은 인간 평가와의 Spearman 상관을 최대화하도록 Prompts와 샘플링 전략 등을 반복적으로 개선했다. 데이터셋 구성은 비디오 길이 1분 이내의 샘플 660개로, 엔드투엔드 응답의 시퀀스, Ground-Truth 타임스탬프, 오디오-비주얼 신호를 포함한다.
실무 활용
Omni-DuplexEval은 실시간 듀플렉스 멀티모달 시스템의 평가를 위한 표준화된 벤치마크를 제공한다. 오픈형 질의에 기반한 응답과 시간적 정합성을 함께 고려하는 자동 평가 프레임워크를 통해 개발자와 연구자가 실시간 인터랙션의 강건성과 적시성 등을 체계적으로 검증할 수 있다.
- 실시간 영상 앱에서의 대화형 어시스턴트 성능 평가
- 스트리밍 스포츠 중계의 자동 주석 및 요약 타이밍 평가
- 교육용 멀티모달 어시스턴트의 실시간 피드백 및 질의응답 시스템 개발
- 라이브 콘텐츠 편집 및 자막 생성 시점과의 정합성 평가
- 현실세계의 멀티모달 로봇/에이전트의 이벤트 감지 및 타이밍 최적화
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.