TL;DR
다차원 품질을 필요로 하는 RLVR에서 단일 스칼라 보상은 다양한 실패 모드를 은폐하고 특정 기준의 학습 가능성에 비례한 신호를 주지 못한다. 루브릭은 프롬프트별 여러 기준을 독립적으로 평가하지만, 전통적 합산 방식은 인간의 가중치가 최종 결과의 중요성과 현재 학습 신호의 유용성 둘 다를 나타낸다고 가정한다는 점에서 한계가 있다. POW3R은 루브릭 목표를 보존하면서 학습에 기여하는 기준에 집중하도록 within-category pressure를 재조정한다. 이를 통해 학습 신호의 분포를 넓히고, dead/saturated한 기준의 영향을 줄이며, 학습 효율과 최종 루브릭 점수를 함께 개선한다.
왜 중요한가
다차원 품질을 필요로 하는 RLVR에서 단일 스칼라 보상은 다양한 실패 모드를 은폐하고 특정 기준의 학습 가능성에 비례한 신호를 주지 못한다. 루브릭은 프롬프트별 여러 기준을 독립적으로 평가하지만, 전통적 합산 방식은 인간의 가중치가 최종 결과의 중요성과 현재 학습 신호의 유용성 둘 다를 나타낸다고 가정한다는 점에서 한계가 있다. POW3R은 루브릭 목표를 보존하면서 학습에 기여하는 기준에 집중하도록 within-category pressure를 재조정한다. 이를 통해 학습 신호의 분포를 넓히고, dead/saturated한 기준의 영향을 줄이며, 학습 효율과 최종 루브릭 점수를 함께 개선한다.
핵심 기여
Rubric-pressure diagnostic의 도입
루브릭 기반 RL에서 static 가중치가 학습 신호를 어떻게 왜곡하는지 진단하는 프레임워크를 제시한다. 평가 항목의 pass 비율(pj)과 분산(vj)을 통해 어떤 기준이 학습에 기여하는지 확인하고, dead/saturated 항목은 학습 신호를 제거한다.
POW3R: 정책 인식 루브릭 보상
각 기준의 rollout-contrast를 측정하고, 이를 경계된 팩터로 혼합·클리핑하여, saturation/dead인 기준은 학습 floor를 유지하고 contrast를 보이는 기준에는 추가 신호를 부여한다. 또한 카테고리별로 Within-category mass를 보존하며 가중치 priors를 유지한다.
세 가지 기준 비교에서의 일관된 개선
MM/HB 양 setting과 세 가지 모델군에서 POW3R가 24/30 비교에서 최고 성능을 달성하고, 동일 목표를 2.5–4× 적은 학습 스텝으로 달성한다. 외부 벤치마크에 대한 VLM 벤치마크 점수도 유지한다.
효율성 측면의 실험적 증거
dev reward 46.0으로 도달하는 데 POW3R은 83스텝으로 도달해 Static scalar(249)보다 3.0×~4.0× 빠르며, 학습 속도와 성능의 증가가 일정한 시점부터 나타난다.
핵심 아이디어 이해하기
- 다차원 루브릭의 인간 가중치(wj)가 최종 결과의 중요성에 대한 가이드 역할은 하지만, 현재 학습 신호로서의 유용성은 항상 같지 않다. 압축된 단일 점수로 합치는 경우, 일부 고가중치 항목은 rollout에서 구분점을 제공하지 못하여 gradient 신호를 제공합니다. 결국 고가중치가 항상 학습에 기여하는 것은 아니다. 2) POW3R는 각 항목의 rollout-contrast를 기준으로 가중치를 조정하되, 루브릭의 목표를 보존한다. 평가 카테고리 내에서의 가중치 분모를 고정하고, 각 항목의 judge verdicts의 분산과 pass율을 바탕으로 αj(t)를 업데이트한다. 3) 카테고리 내에서 가중치를 재배치해도 카테고리의 총 무게 합은 보존되며, 이를 통해 final answer의 질은 유지하되 학습 신호는 현재 정책이 구분할 수 있는 항목으로 집중된다. 4) 이 방식은 프롬프트 단일 점수로의 단순 합산이 가져오는 학습 비효율을 줄이고, 훈련 속도 및 모델의 두 가지 주요 지표(루브릭 보상 및 strict completion)에서 우수한 성과를 실현한다.
관련 Figure
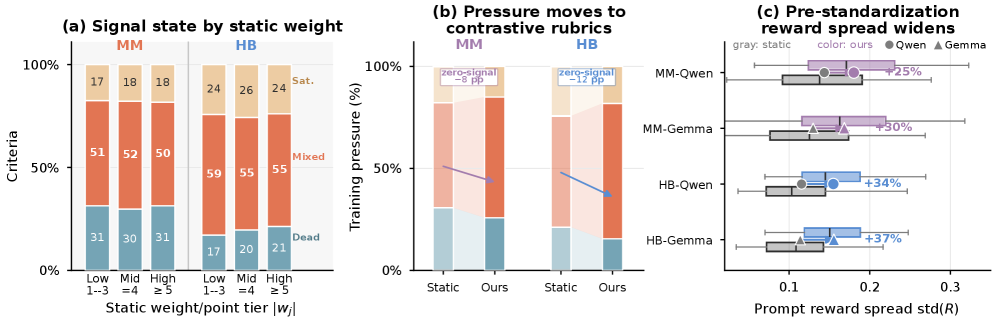
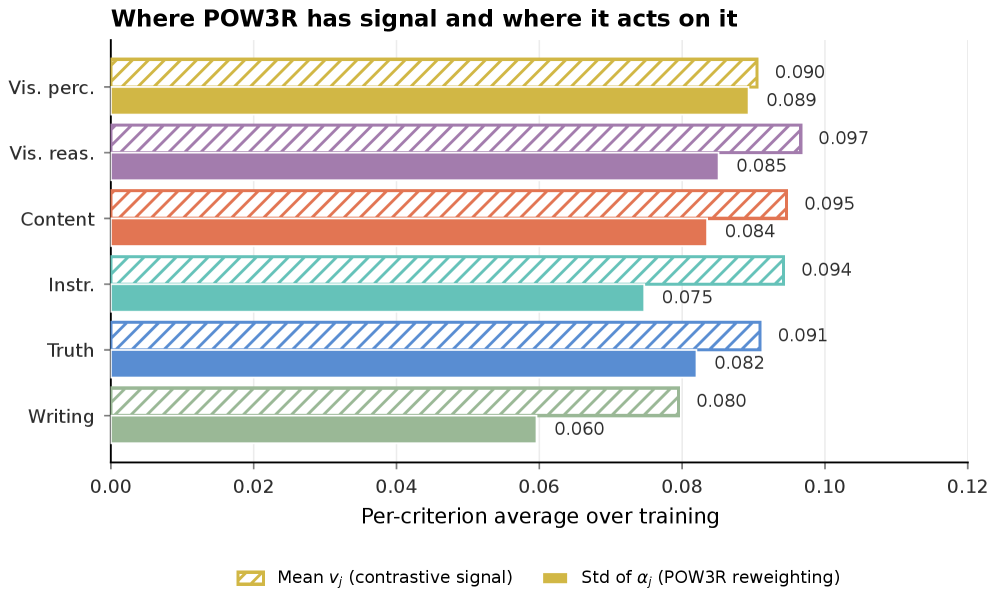
각 기준의 training pressure와 signal 상태를 시각화하여 dead/saturated 기준의 비중과 그로 인한 학습 신호의 손실을 확인한다. POW3R의 필요성인 정책 인식 보상의 도입 근거를 시각적으로 제시한다.
Rubric-pressure diagnostic를 시각화한 그림.
방법론
[입력 → 연산 과정] 정책: GRPO 기반 포스트 트레이닝; Group Relative Policy Optimization(GRPO) 실행; G=16, T=1.0, 최대 3584 tokens, KL 계수 β=0.1, PPO 클립 ε=0.2, gradient clip=0.5. [수식: 퍼 롤아웃 보상 매핑] R(o;q) 각 롤아웃 o에 대해 주어지고, group 내 평균과 표준편차 std(R)를 이용하여 A_hat_i,t를 계산한다. [수식: pow3r 동적 보상] t번째 epoch에서 w̃_j^(t) = w_j α_j^(t)로 정의하고, W̃_k^(t)(q) 합산 후 R_dyn(o;q) = 1/K_q ∑_k 1/W̃_k^(t)(q) ∑_j∈C_k(q) w̃_j sj(o,q)로 구성한다. [학습 신호 재가중] α_j^(t) = clip((1−λ) + λ ρ_j, α_min, α_max) 및 EMA 업데이트 및 재정규화로 카테고리 내에서 mass를 유지한다. [평가 및 트레이닝] judge로부터 criterion별 verdict를 얻고, 훈련과 held-out 평가에서 동일 시스템 프롬프트를 사용한다. POW3R은 dead/saturated 기준의 weight를 줄이고, contrastive 기준의 압력을 증가시켜 prompt 수준의 보상 분산을 넓힌다.
관련 Figure
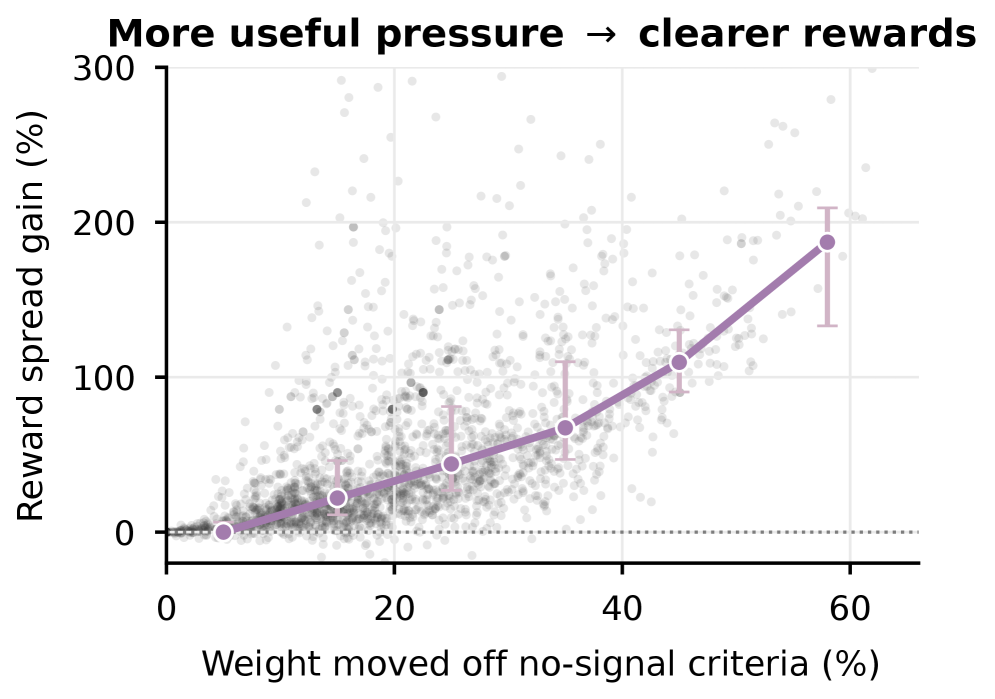
정책 인식 가중치가 dead/saturated가 아닌 기준에 집중되면서, rollout 간 차이가 증가해 reward spread가 넓어진다. 이는 POW3R의 학습 신호 개선 메커니즘의 핵심 증거이다.
2차 그림은 컨스트래스트 루브릭으로의 압력 이동을 보여준다.
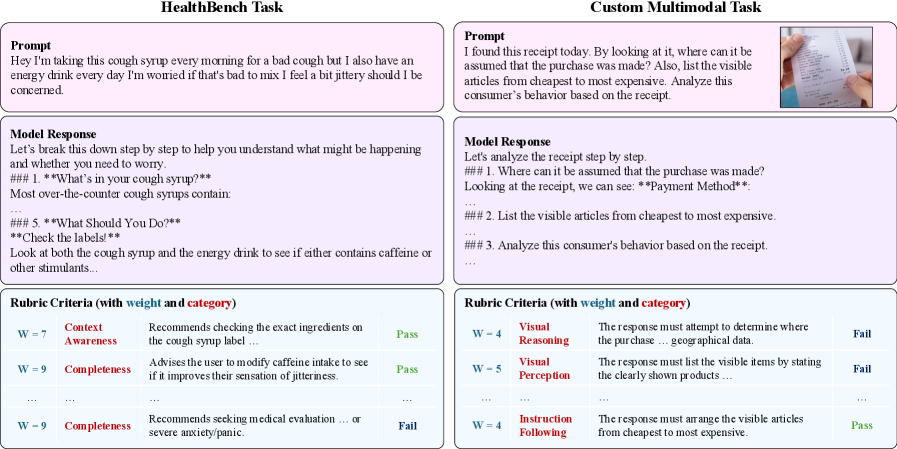
MM/HB의 프롬프트-루브릭 설계를 시각적으로 나타내며, 평가 항목이 프롬프트에 따라 달라지는 다차원 구성을 보여준다. POW3R의 동적 재가중의 필요성을 도출하는 근거를 제공한다.
교육 설정 및 시스템 프롬프트 구성을 담은 도식 이미지.
MM/HB 두 설정에서의 예시 task를 제시하여, 각 기준에 대한 점수 부여와 verdict의 취급 원리를 시각적으로 설명한다.
illustrative tasks의 예시를 담은 그림.
주요 결과
주요 결과는 다음과 같다. MM 데이터셋에서 Qwen3-VL-4B, Qwen3-VL-8B, Gemma-3-4B에 대해 POW3R dynamic이 각각 48.8, 51.6, 37.8의 rubric 점수와 20.2, 22.6, 10.3의 strict completion 점수를 달성하며, Base/Binary/Static scalar/Category-balanced 대비 모두 우수하다. HealthBench 영어 테스트 세트에서도 POW3R dynamic이 Overall 점수에서 가장 높은 32.7점을 기록했고, Qwen3-4B에서 46.0 대비 46.0의 baseline 대비 우수한 개선을 보였다. 또한 POW3R는 동일한 GRPO 설정에서 2.5–4×의 학습 속도 향상을 보였으며, 외부 벤치마크에서도 24/30 사례에서 최상위를 차지하면서 VLM 벤치마크 점수도 유지했다. Figure 4는 두 객체 지배(dominance) 관점에서 POW3R가 모든 base-policy 라인에서 최상위임을 보여주고, Figure 5-7은 category별 신호, 학습 진척도, 및 단일 프롬프트에서의 개선이 일관되게 나타남을 시각화한다.
관련 Figure
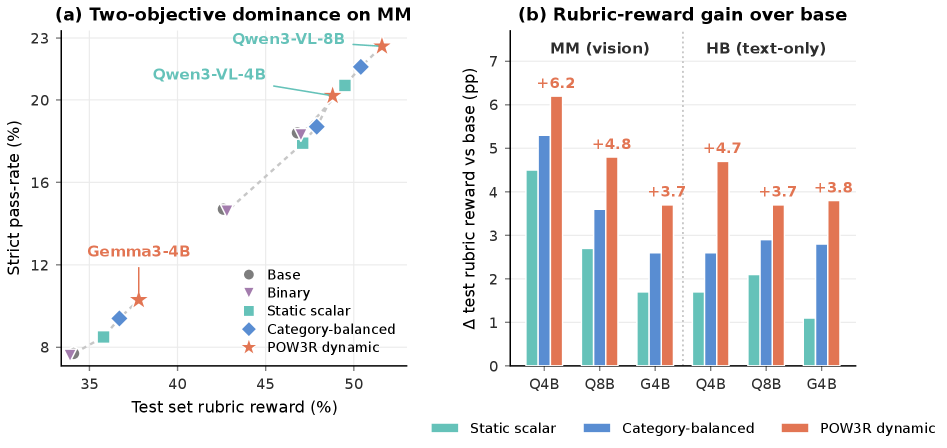
POW3R가 두 가지 평가 축에서 Pareto 최적에 위치함을 시각적으로 확인한다. mean rubric reward와 strict completion 양 측면에서 POW3R가 우수함을 보여준다.
Two-objective dominance를 보여주는 산점도 차트.
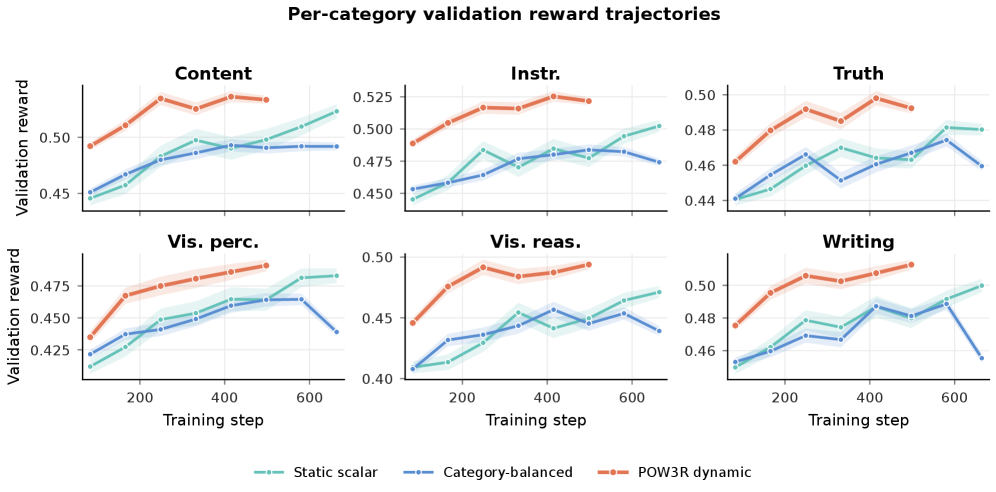
카테고리별 학습 진행에 따라 POW3R의 효율성과 개선 영역(Content, Instruction Following 등)이 어떻게 나타나는지 시각적으로 보여준다.
Per-category validation reward trajectories 그림.
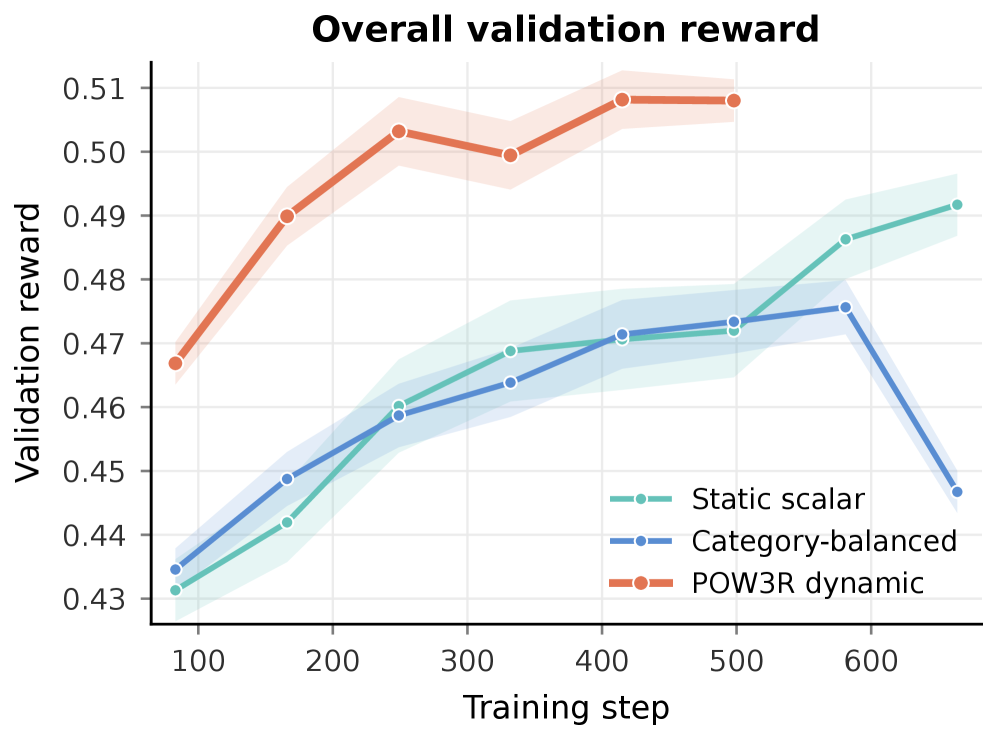
학습 도중 POW3R가 Static scalar/Category-balanced를 앞선 모습을 연속적으로 보여준다. 학습 단계가 진행될수록 POW3R의 우위가 뚜렷해진다.
Overall validation reward trajectory 그림.
기술 상세
GRPO를 기반으로 한 다중 기준 보상 구조에서, 각 기준 j의 pass 비율 pj와 분산 vj=pj(1−pj)를 사용해 α_j^(t) 업데이트를 수행한다. 카테고리 k에 대해 W̃_k^(t)(q) = ∑{j∈C_k(q)} w_j α_j^(t)으로 가중치를 재계산하고, R_dyn(o;q) = (1/K_q) ∑{k: C_k(q)≠∅} (1/W̃_k^(t)(q)) ∑_{j∈C_k(q)} w_j α_j^(t) s_j(o,q)로 최종 보상을 구성한다. 학습은 GRPO의 PPO 기반 업데이트를 사용하며, 훈련 데이터는 MM/HB로 구성된다. 평가 시에는 held-out judge(GPT-5.4-mini)로 재평가한다.
실무 활용
루브릭 기반 RLVR의 보상 설계를 학습 시간의 설계 선택으로 다룰 수 있음을 보여준다. POW3R은 기존 루브릭 대상의 품질 목표를 유지하면서 학습 신호를 현재 정책이 구분할 수 있는 기준으로 재배치한다. 이로 인해 멀티모달/텍스트 기반의 다중 기준 평가에서 더 안정적이고 빠른 수렴이 가능하며, 다양한 도메인에서 루브릭의 적용 가능성이 커진다.
- Long-form medical writing에서 다차원 정확성·충실도·참조 근거를 균형 있게 달성
- 멀티모달 대화 시스템에서 perception과 reasoning을 함께 개선
- 코드 리뷰/에듀테크에서 정확성, 완전성, 명확성 등 다면적 기준의 품질 향상
- 문서 요약 및 연구 논문 분석에서 사실성(Truthfulness)과 명료성의 균형
코드 공개 여부: 비공개
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.