TL;DR
현실 세계 환경은 소음, 원거리 마이크, 에코, 전송 손실 등 다중 요인이 복합적으로 작용한다. 기존 모델은 단일 요인에 초점을 맞추거나 한정된 합성 조건에서 학습되어 일반화가 제한된다. VOICES-IN-THE-WILD-2M 데이터셋과 A2S-SFT, DG-WGPO를 결합해 음향-의미 간 연결을 단계적으로 강화하고, RL 기반의 동적 보상으로 복합 조건에서도 의미 재구성과 정확도 향상을 달성한다.
왜 중요한가
현실 세계 환경은 소음, 원거리 마이크, 에코, 전송 손실 등 다중 요인이 복합적으로 작용한다. 기존 모델은 단일 요인에 초점을 맞추거나 한정된 합성 조건에서 학습되어 일반화가 제한된다. VOICES-IN-THE-WILD-2M 데이터셋과 A2S-SFT, DG-WGPO를 결합해 음향-의미 간 연결을 단계적으로 강화하고, RL 기반의 동적 보상으로 복합 조건에서도 의미 재구성과 정확도 향상을 달성한다.
핵심 기여
VOICES-IN-THE-WILD-2M 데이터셋 구축
7 가지 메타-시나리오와 54 개의 합성 시나리오를 갖춘 2.4M 샘플의 음향 시뮬레이션 데이터셋으로, 11k 시간 분량의 녹음/샘플을 포함한다.
A2S-SFT 도입
음향 인식에서 중-고 WER 구간에서의 의미 재구성 능력을 높이기 위해 encoder+aligner의 WER-graded curriculum, LLM 측 LLM-side LoRA 적응, 그리고 엔드-투-엔드 조합 학습의 세 단계를 도입한다.
DG-WGPO 도입
토큰-수준의 미세 보정 보상(Rfine)과 문장-수준의 재구성 보상(Rstruc)을 WER-게이팅된 역합성으로 결합하고, WER 임계 τ에 따라 가중치를 동적으로 조절한다. 고난이도 샘플에서 의미 재구성과 잡음 회복에 초점을 둔다.
환경-적응형 플러그앤플레이 인퍼런스 라우팅
간단한 MFCC 기반 구조의 라우터로 입력이 깨끗한지 여부를 예측하여 Mega-ASR의 LoRA-강화 백본과 원본 Qwen3-ASR 백본 간 경로를 선택한다. 인퍼런스 오버헤드는 무시할 만큼 작다.
강건성 및 합성 현장 조건에서의 최상위 성능
Voices-in-the-Wild-Bench에서 2.73/4.57 WER를 달성하고, CHiME-4, VOiCES, NOIZEUS에서 평균 WER 6.70으로 SOTA를 상회한다. 0dB NOIZEUS 조건에서도 19.80(WER)로 강한 경쟁력을 보인다.
Case study 및 Ablation 인사이트
Case study에서 far-field 재구성, 콘텐츠 hallucination, 엔티티 재구성에서 Mega-ASR이 SOTA 모델 대비 향상된 성능을 보였고, ablation에서 Rstruc/Rfine/Rrep의 각 기여를 확인했다.
핵심 아이디어 이해하기
단계1에서 음향 요소를 atomic하게 모델링한 뒤, 7가지 atomic 효과를 조합해 54개의 compound 시나리오를 구성한다. 단계2에서 A2S-SFT를 통해 음향 인식의 저-중-고 WER 구간에서의 의미 추론과 재구성을 점진적으로 강화한다. 단계3에서 DG-WGPO를 도입해 토큰-수준의 지역적 정보 회복과 문장-수준의 전체 의미 보존 사이를 WER에 따라 동적으로 융합하고, 필요 시 라우팅으로 노이즈 수준에 맞춘 백본을 선택한다.
방법론
- 프레임워크 개요: Acoustic Encoder+Aligner, LLM, 그리고 정책 모델로 구성된 MEGA-ASR를 통해 음향-의미 간 연결을 학습한다. 2) A2S-SFT: Phase I에서 encoder+aligner를 WER<30%→WER<50%→WER<70% 순으로 점진 학습, Phase II에서 LLM LoRA를 고정한 채 음성 기반 의미 적응, Phase III에서 Encoder+Aligner+LLM의 공동 학습. 3) DG-WGPO: Rwer(WER 보상)와 Rrep(반복 보상)로 고정 보상을 제공하고, Rdynamic에서 Rfine과 Rstruc를 τ(WER 임계값)에 따라 다르게 가중하여 두 계층의 보상을 동적으로 융합한다. 4) 인퍼런스 라우팅: 경량 MFCC 기반 이진 분류기로 입력의 품질을 판단해 깨끗한 경우 Qwen3-ASR 백본으로, 악조건인 경우 Mega-ASR LoRA로 라우팅한다. 5) 구현/학습: 2GPU 분산 학습, Phase I/II/III 각각의 하이퍼파라미터 및 LoRA 랭크(r)=8, αdyn=0.6, αs=0.4, τ=0.3 등 고정값. RL은 6,000 스텝, K=16 롤아웃, 0.4Rsimple+0.6Rdynamics로 설정.
관련 Figure

7 도메인과 54 하이브리드 시나리오의 구성과 규모를 시각화하며, 데이터 구성의 복합성 및 스케일의 의미를 보강한다.
VOICES-IN-THE-WILD-2M의 도메인·시나리오 구성 인포그래픽
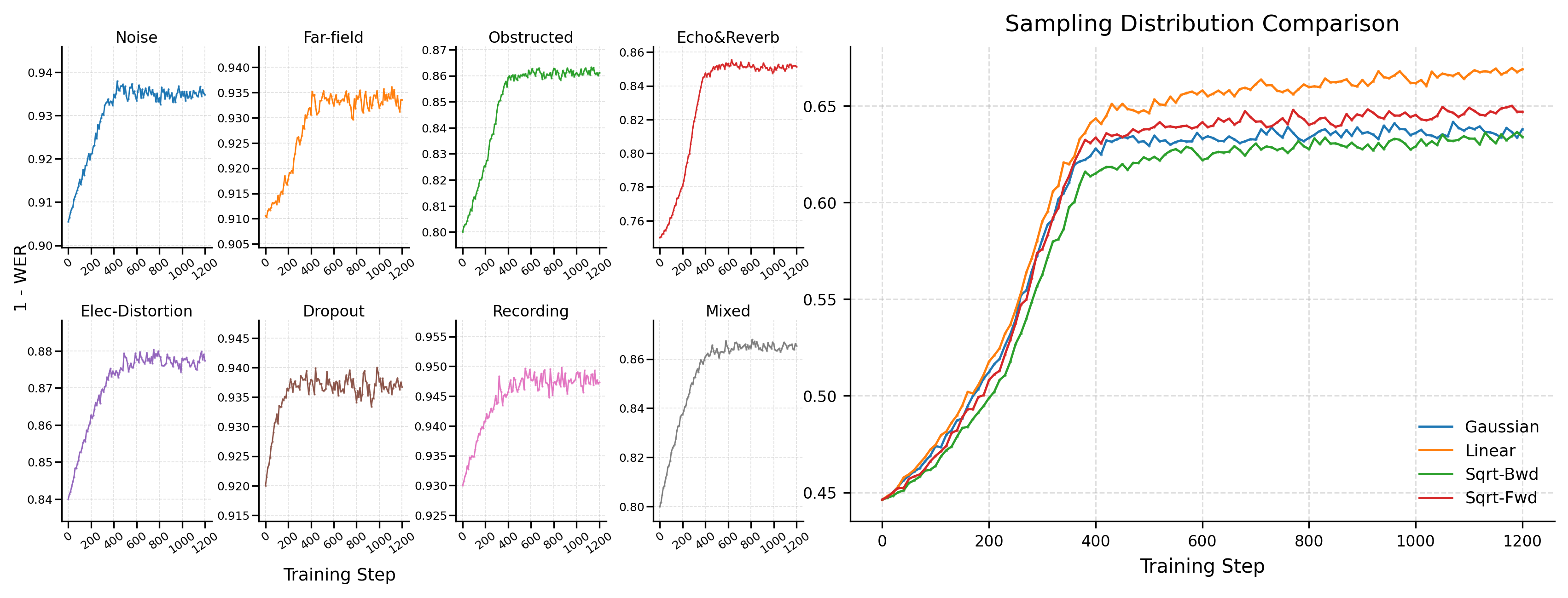
난이도 샘플링 분포의 차이를 보여주며, Linear 매핑이 균형적인 난이도 분포를 달성하는 근거를 시각적으로 제시한다.
Sampling Distribution 비교 그래프
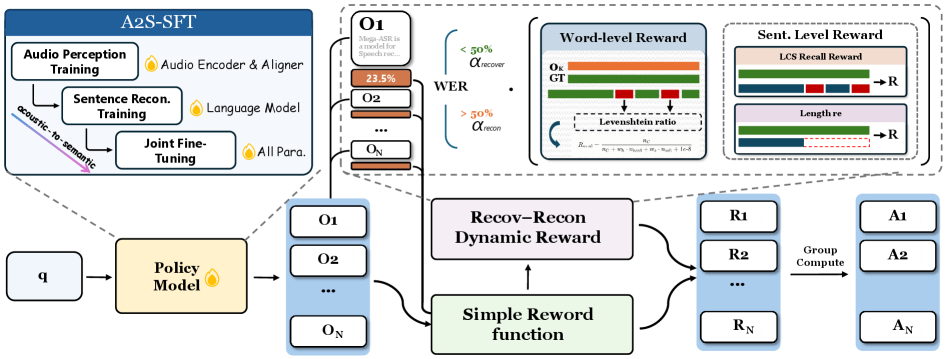
Audio Encoder/Aligner, LLM, LoRA 덧붙임 모듈의 구성 및 흐름을 제시하며, A2S-SFT 및 DG-WGPO의 적용 포인트를 연결해 보여준다.
Mega-ASR 아키텍처 다이어그램
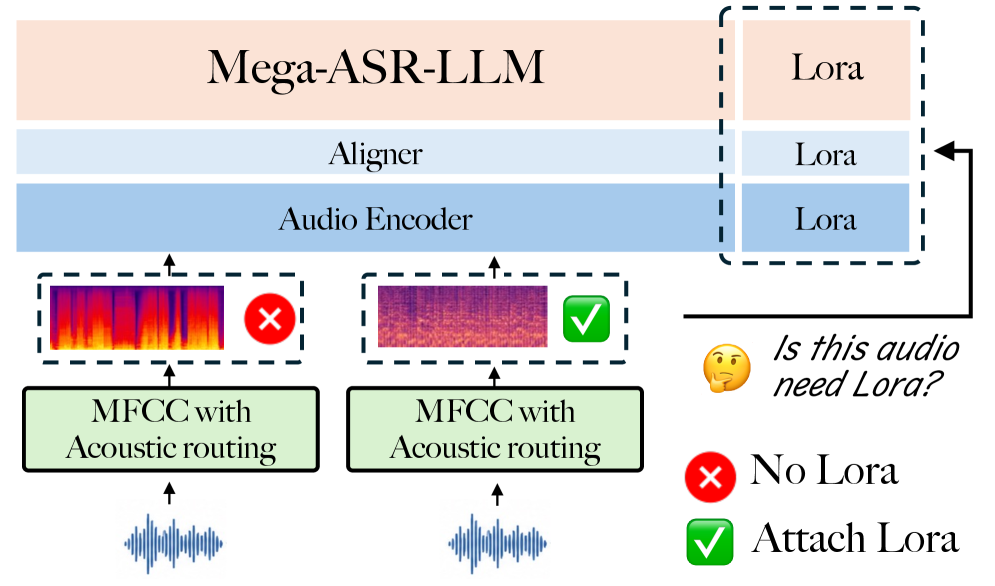
MFCC 기반의 경량 라우터를 통해 입력 음질에 따라 백본을 선택하는 흐름을 보여준다.
환경-인식 라우팅 아키텍처
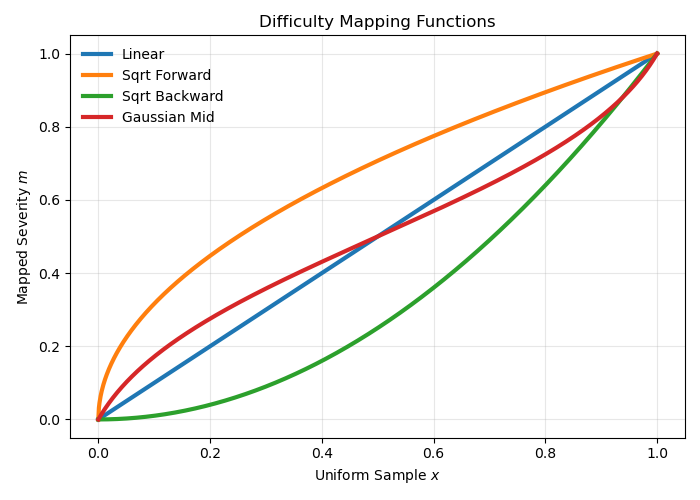
네 가지 매핑 함수(Linear, Sqrt Forward, Sqrt Backward, Gaussian Mid)의 난이도 분포 차이를 시각화한다.
Difficulty Mapping Functions 그래프
주요 결과
주요 벤치마크에서의 성능: VOiCES R4-B-F 및 NOIZEUS Sta-0에서의 WER 감소가 두드러지며, 평균 WER 6.70으로 SOTA를 능가한다. Voices-in-the-Wild-Bench에서 혼합 degradations, far-field, recording artifact에서 Mega-ASR이 일관되게 최상위 성능을 보여준다. Abalation 결과: A2S-SFT 및 DG-WGPO의 각 구성 요소를 제거하면 WER이 상승하는 경향을 보이며, Rstruc가 특히 문장-수준 재구성에 중요하다. 라우터 도입으로 인퍼런스 오버헤드는 미미하며, 라우팅 도입 후 clean-domain 성능의 저하 없이 robust 성능을 유지한다.
관련 Figure
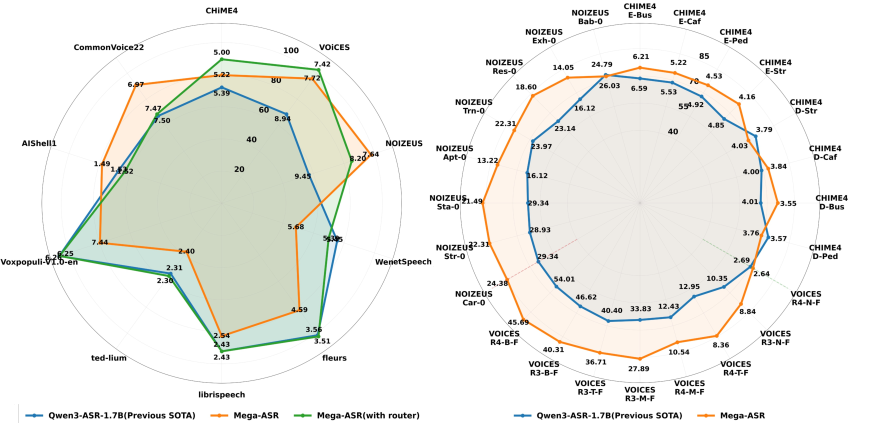
개념적 성능 차이를 한눈에 보여주며, clean/robustness 하위집합에서 Mega-ASR의 상대적 강점을 시각화한다.
논문 Figure의 Radar 비교—Qwen3-ASR-1.7B(이전 SOTA)와 Mega-ASR의 성능 비교
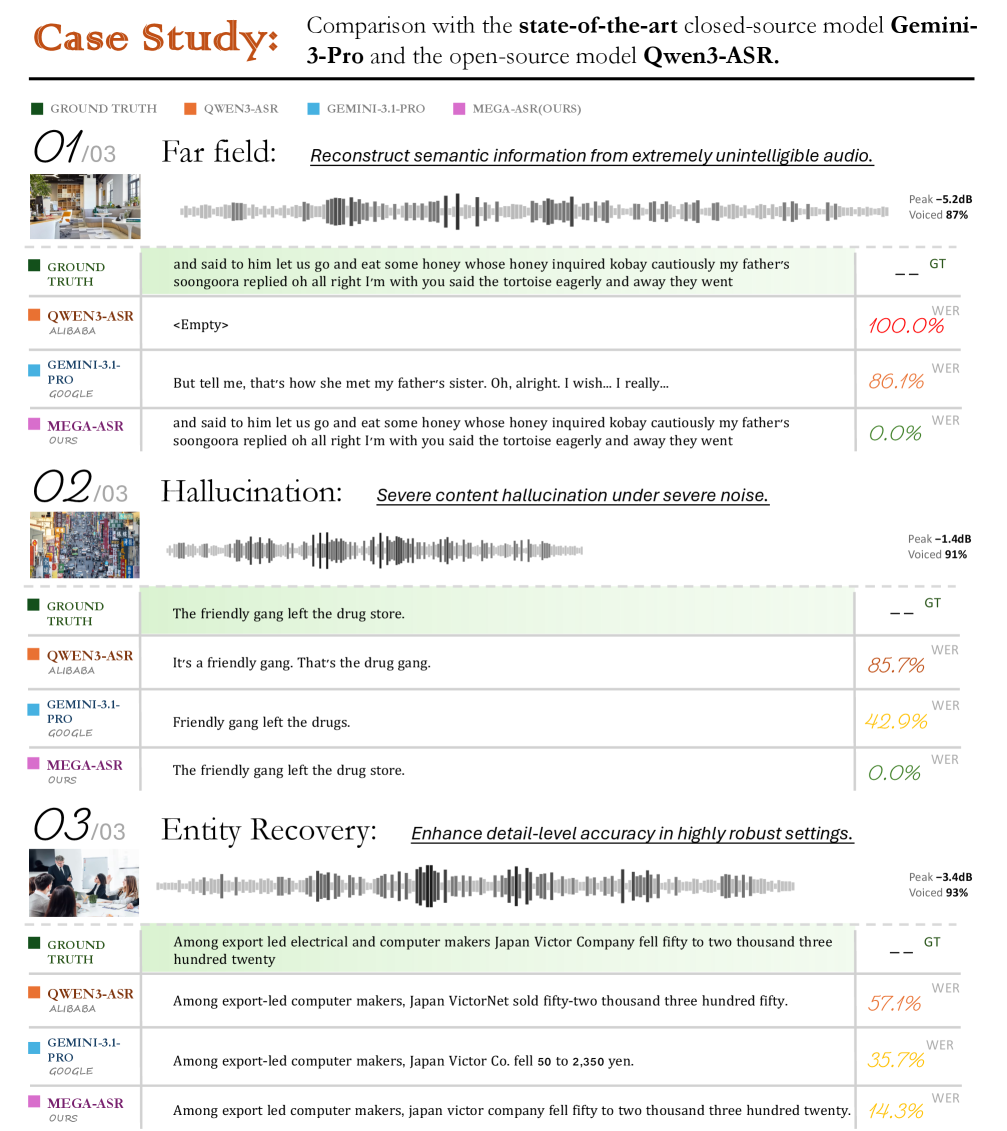
Far field, Hallucination, Entity Recovery 케이스에서 Mega-ASR의 현저한 개선 사례를 제시한다.
Case Study: GEMINI-3-PRO, QWEN3-ASR 대비 Mega-ASR의 사례 비교
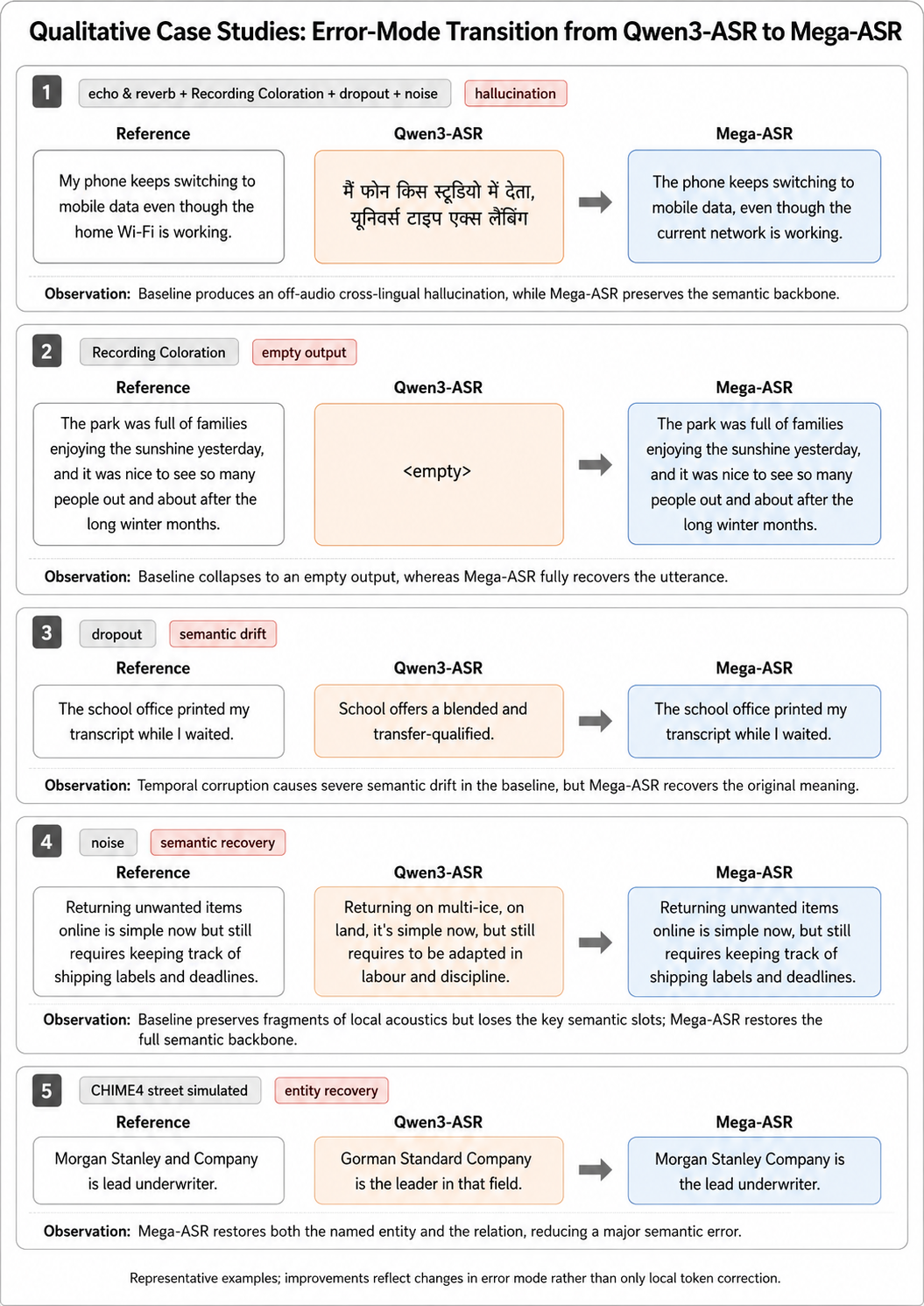
Qwen3-ASR에서 Mega-ASR로의 에러 모드 전이 사례를 시각화해, 구체적 개선 포인트를 보여준다.
Qualitative Case Studies: Error-Mode Transitions
기술 상세
아키텍처는 Encoder+Aligner+LLM으로 구성되며, A2S-SFT는 Phase I(Encoder+Aligner), Phase II(LLM) 및 Phase III(공동 조정)로 구성된다. DG-WGPO의 Rwer, Rfine, Rstruc 구성은 수식으로 정의되며, τ=0.3, αs=0.4, αdyn=0.6으로 설정된다. Token-level refinement는 h,r의 유사도 sim(h,r)=1−edit(h,r)/max(|h|,|r|)로 hard/soft를 구분하고, Rfine는 정답 토큰의 정확도와 잘못된 토큰의 비율에 기반해 계산된다. Sentence-level reconstruction은 LCS(H,R)와 길이 비율의 조합으로 Backbone의 일관성을 평가한다. 전체 보상은 R=(1−αdyn)Rsimple+αdynRdynamic으로 합성된다.
실무 활용
실무에서 악조건 환경의 음성 인식을 개선하기 위한 모듈로 활용 가능하다. VOICES-IN-THE-WILD-2M 기반의 강건한 데이터 증강과 A2S-SFT, DG-WGPO를 결합한 MEGA-ASR은 실무데서도 의미 보존과 재구성 능력을 향상시킨다.
- 차량용 음성 비서에서 다중 소음 및 거리 효과에 강한 인식 제공
- 회의 및 콜센터에서 복합 환경 소음에도 안정적인 자막 생성
- 스마트홈 디바이스에서 원거리/에코 환경에서도 정확한 명령 인식
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.