TL;DR
긴 비디오 생성에서 프레임 간 일관성을 유지하는 것이 핵심 문제다. 제안하는 MIGA는 Two-Stage Training-Inference Alignment(TTA)와 Dual Consistency Enhancement(DCE)을 통해 training과 inference 간 노이즈 스팬 차이를 줄이고, 초기 고노이즈 프레임의 자기 반영과 후반 프레임의 장거리 가이던스로 장기 일관성을 강화한다. VBench와 NarrLV에서 state-of-the-art 성능을 확인했다.
왜 중요한가
긴 비디오 생성에서 프레임 간 일관성을 유지하는 것이 핵심 문제다. 제안하는 MIGA는 Two-Stage Training-Inference Alignment(TTA)와 Dual Consistency Enhancement(DCE)을 통해 training과 inference 간 노이즈 스팬 차이를 줄이고, 초기 고노이즈 프레임의 자기 반영과 후반 프레임의 장거리 가이던스로 장기 일관성을 강화한다. VBench와 NarrLV에서 state-of-the-art 성능을 확인했다.
핵심 기여
Two-Stage Training-Inference Alignment (TTA)
노이즈 스팬을 줄이기 위해 Stage 1에서 zigzag denoising으로 노이즈 레벨 변화 속도를 늦추고, Stage 2에서 모든 latents를 같은 노이즈 레벨로 통합하여 training- inference 간 차이를 최소화한다.
Dual Consistency Enhancement (DCE)
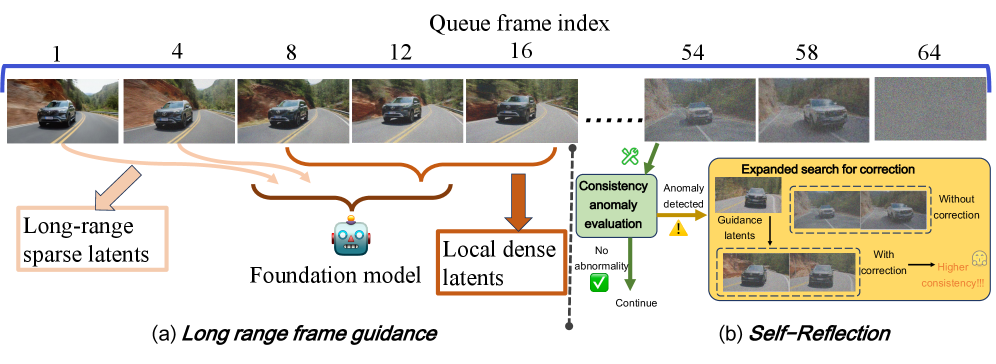
Self-Reflection으로 tail의 고노이즈 latents의 일관성 이상을 평가-교정하고, Long-Range Frame Guidance로 head의 저노이즈 latents를 사용해 멀리 떨어진 프레임 간 상호작용을 촉진한다.
Fixed-memory Infinite-Frame Generation
FIFO-Diffusion 기반 frame-level autoregressive 구조를 유지하면서 메모리 사용량을 고정하고 무한 프레임 생성을 가능하게 한다.
State-of-the-art on VBench and NarrLV
VideoCrafter2 기반 MIGA와 Wan2.1 기반 MIGA가 VBench에서 S.C./B.C./M.S./T.F./O.S. 항목에서 최상위 성능을 달성했고 NarrLV에서 서사 표현력이 향상된다.
Multi-prompt Conditional Generation
nprom 텍스트 조건을 프레임별로 다른 위치에 제공하여 여러 프로ンプ트를 순차적으로 제어하고 장면 전개를 다양화한다.
핵심 아이디어 이해하기
- 문제 정의: 프레임 단위 diffusion 기반의 프레임 수준 autoregressive 생성은 노이즈 스팬이 커지면 학습 시의 조건과 불일치가 생겨 콘텐츠 드리프트 및 아티팩트가 증가한다. 2) 해결 원리: 두 단계의 TTA로 노이즈 span을 줄이고, DCE로 장기 일관성을 강화한다. Stage 1은 zigzag denoising으로 입력 노이즈 스팬을 완화하고, Stage 2에서 동일 노이즈 레벨로 denoise를 수행해 학습 시 조건과 유사한 입력을 보장한다. 3) 달라진 점: Self-Reflection은 tail latent의 이상을 빠르게 탐지하고 교정하며, Long-Range Guidance는 head latent를 활용해 먼 프레임 간 상호작용을 촉진해 전체 비디오의 일관성을 높인다. 4) 결과적으로, 기존 FIFO-Diffusion 대비 긴 비디오에서Subject/Background Consistency, Motion-Smoothness, Temporal-Flicker 측정에서 개선이 확인된다.
관련 Figure

무한 프레임 생성의 핵심 아이디어를 직관적으로 전달하며, 프레임 스트립과 MIGA 로고가 포함된 구성으로 프레임 간 일관성을 강조한다.
Figure 1: MIGA의 무한 프레임 비디오 구성을 시각화한 다이어그램
방법론
- 프레임 수준 autoregressive 프레임워크를 사용하되, 노이즈 스팬이 큰 입력을 다루는 문제를 Two-Stage Training-Inference Alignment(TTA)로 해결한다. 2) Stage 1에서 zigzag 방식으로 Lzig 만큼의 latents를 앞뒤로 교차시키며 denoising하여 노이즈 레벨의 급격한 변화를 완화하고, Stage 2에서 남은 latents를 τe−1의 동일한 노이즈 레벨로 재 denoise 한다. 3) Dual Consistency Enhancement(DCE)로 tail의 고노이즈_latents를 Self-Reflection으로 평가-교정하고, head의 저노이즈_latents를 Long-Range Guidance로 입력에 반영하여 멀리 떨어진 프레임 간 상호작용을 촉진한다. 4) Multi-prompt Conditional Generation으로 nprom 프롬프트를 queue의 서로 다른 위치에 적용해 1개의 프레임당 서로 다른 텍스트 조건을 주입한다. 5) VideoCrafter2 및 Wan2.1 같은 최신 foundation 모델에 대해 구현되며, 64단계(VideoCrafter2) 또는 54단계(Wan2.1)에서 동작하도록 구성한다. 6) 평가 지표는 VBench 및 NarrLV로 구성되며, S.C./B.C./M.S./T.F./O.S. 등의 벤치마크에서 성능이 확인된다.
관련 Figure
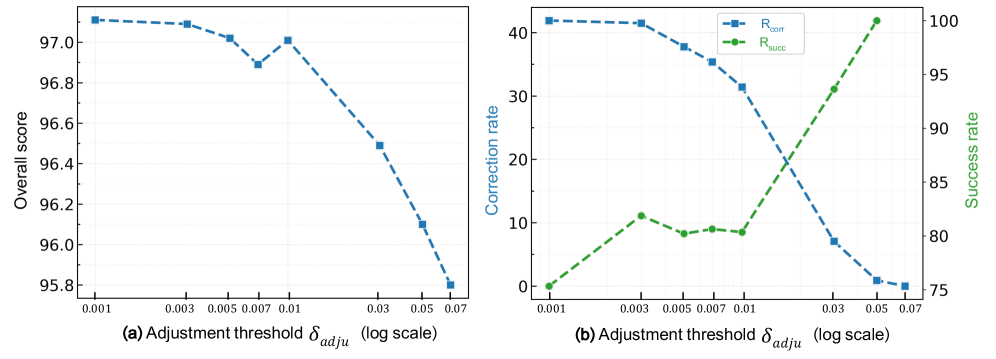
Stage 1/Stage 2의 차이를 시각화하며, TTA의 의도대로 노이즈 스팬을 줄이고 unified denoising으로 정합하는 흐름을 보여준다.
Figure 2: FIFO-Diffusion과 MIGA의 두-stage alignment 비교 다이어그램
주요 결과
- VBench에서 VideoCrafter2-Based MIGA는 Infinite 97.66, S.C. 97.66, B.C. 96.99, M.S. 98.60, T.F. 98.03, O.S. 97.82로 FIFO-Diffusion(92.92, 95.01, 97.19, 94.94, 95.02) 및 FreeLong/FreePCA 대비 우수하다. Wan2.1-Based MIGA의 경우 FIFO-Diffusion 대비 전반적으로 향상되며, O.S.는 97.24로 상위 수준이다. 2) NarrLV에서 TNA=2/3/4 설정 하에서의 satt/tatt/tact 지표가 각각 향상되며, MIGA가 Narrative 표현력에서도 우수하다. 3) Ablation 연구에서 Stage 1만 추가 시 S.C./B.C./M.S./T.F./O.S.가 각각 95.98/96.54/97.57/97.03/96.78에서 Stage 2 추가 시 96.74/96.75/97.57/97.12/97.05로 개선되고, 두 단계 모두 결합 시 최종적으로 97.66/96.99/98.60/98.03/97.82에 도달한다. 4) 효율성 측면에서 DCE를 도입하면 추론 시간이 증가하지만, O.S.는 여전히 향상되며 메모리 증가폭은 제한적이다. 5) Stage 2의 단계 수를 조정하면 O.S.와 각 지표가 안정화되며, Stage 1의 존재가 autoregressive 특성을 유지하고 다프듯한 품질 개선에 기여한다.
관련 Figure
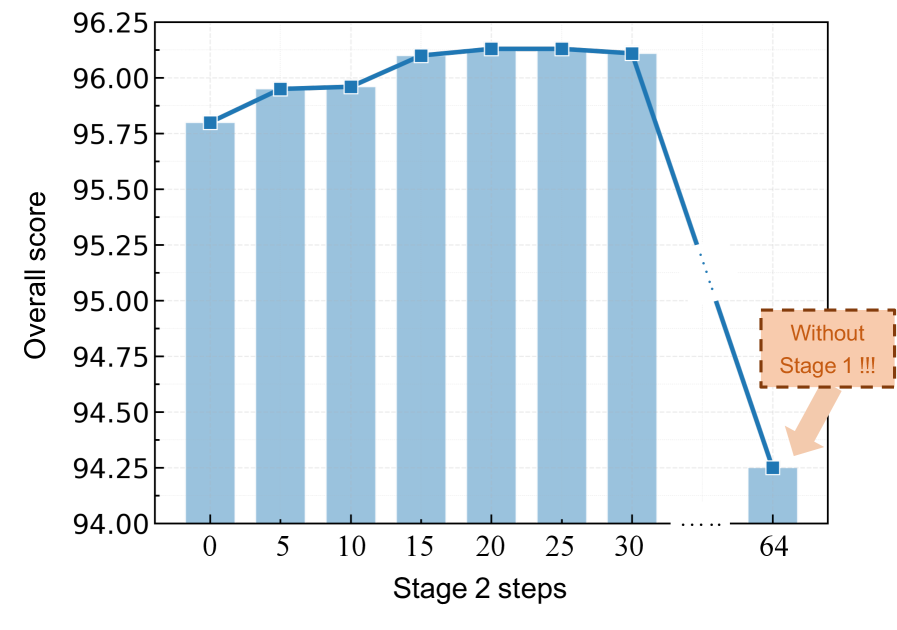
Stage 2 단계 수 증가에 따른 성능 변화와 안정화를 보여 주며, Stage 1의 존재가 Stage 2의 효과를 보강한다는 점을 시사한다.
Figure 6: Stage 2 단계 수에 따른 Overall Score 변화

긴 비디오 사례를 통해 텍스트 프롬프트에 따른 서사 표현과 일관성을 시각적으로 확인할 수 있다.
Figure A7: VideoCrafter2 기반 MIGA의 롱 비디오 사례
기술 상세
아키텍처: 프레임 레벨 autoregressive diffusion 기반으로, 지수적 증가 노이즈를 가지는 큐 Q를 유지하고, 각 denoising 스텝에서 f0 프레임의 라인업을 처리한다. Two-Stage Training-Inference Alignment(TTA)에서 Stage 1은 Lzig(지그재그 폭) 단위로 노이즈 레벨 변화를 느리게 하여 입력 노이즈 span을 축소하고, Stage 2에서는 niter 이후 모든 latents를 τe−1의 동일 노이즈 수준으로 정규화하여 학습 조건과 inference 조건의 차이를 최소화한다. Dual Consistency Enhancement(DCE)에서 Self-Reflection은 tail의 고노이즈 latents를 평가하고, δadju 임계 하에서 확장 탐색(nsamp 샘플)을 수행해 일관성 개선을 추구하며, Long-Range Guidance는 큐의 head에서 mguid 프레임을 샘플링하여 현재 프레임의 denoising에 도움을 준다. 멀티 프롬프트 제어는 nprom 텍스트 조건을 큐의 서로 다른 위치에 주입하여 Nprom 프레임 간에 서로 다른 프롬프트를 적용한다. 구현은 VideoCrafter2 및 Wan2.1 기반으로, 16/21 latents 각각에 대해 64단계(T) 또는 54단계(T) 구성에 맞추어 동작하도록 구성된다. 알고리즘으로는 Alg.4~Alg.7의 초기화, Zigzag, Stage 2 denoising, 한 단계의 큐 엔진(Φ)을 포함한다. 메모리 복잡도는 FIFO 구조로 고정되어 무한 프레임을 지원하며, Stage 2는 순차적으로 메모리에 intermediate 변수를 저장하되 windowed denoising으로 관리한다.
한계점
제안된 방법은 train-free 프레임 수준 autoregressive 프레임워크에 의존하며, 특정 거대 모델의 아키텍처에 따라 migratability가 다를 수 있다. 또한 장시간생성에서 가짜 현상(예: Figure A5의 카의 머리와 꼬리 위치 변화)이 발생할 수 있으며, 이는 물리적 제약과 일치하지 않는 경우가 있다.
관련 Figure
장시간 생성의 한계를 나타내는 예로, 모델의 Hallucination 가능성을 시각적으로 보여준다.
Figure A5: MIGA의 한계 사례(잘못된 머리-꼬리 위치 변화)
실무 활용
본 연구의 MIGA 프레임워크는 학습 없이도 foundation 모델의 긴 비디오 생성을 가능하게 하며, 두 단계의 TTA와 DCE를 통해 장시간 비디오에서도 일관성과 품질을 크게 향상시킨다.
- 영화/드라마 제작에서 긴 시퀀스의 콘티에 따른 프롬프트를 구성해 컨티넌시 유지가 필요한 장시간 비디오 생성
- 게임 내 시네마틱 영상 생성에서 텍스트 프롬프트를 다양한 시퀀스로 주입해 서사적 효과를 강화
- 월드 시뮬레이션 또는 가상 환경에서의 긴 시퀀스 생성을 위한 무한 프레임 비디오 생성
코드 공개 여부: 미확인
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.