TL;DR
시계열 foundation model이 스케일링에 따라 예측 품질이 향상될 수 있음을 실증한다. Toto 2.0은 내부 observability 데이터와 합성 데이터를 혼합해 학습하고, CPM, quantile head, NorMuon, u-µP를 도입해 대규모에서도 안정적이고 빠른 추론을 보여주며 BOOM, GIFT-Eval, TIME에서 SOTA를 달성한다. 또한 u-µP를 통한 하이퍼파라미터 전이로 다중 규모 모델에서도 동일 구성을 재사용 가능하게 한다.
왜 중요한가
시계열 foundation model이 스케일링에 따라 예측 품질이 향상될 수 있음을 실증한다. Toto 2.0은 내부 observability 데이터와 합성 데이터를 혼합해 학습하고, CPM, quantile head, NorMuon, u-µP를 도입해 대규모에서도 안정적이고 빠른 추론을 보여주며 BOOM, GIFT-Eval, TIME에서 SOTA를 달성한다. 또한 u-µP를 통한 하이퍼파라미터 전이로 다중 규모 모델에서도 동일 구성을 재사용 가능하게 한다.
핵심 기여
CPM 기반 단일 패스 예측
연속 패치 마스킹으로 학습 시 변 구성 길이의 마스크된 구간을 사용하고, 추론 시 전체 horizon을 한 번에 디코딩하는 단일 패스 구조를 구현해 긴 horizon에서도 일관된 예측을 보장한다.
Quantile Output Head 도입
SMM 대신 9개의 분위수를 출력하는 헤드를 도입하고 pinball loss를 사용해 불확실성 추정의 안정성과 보정성을 개선한다.
NorMuon으로 대규모 학습 최적화
Per-neuron 균형을 위한 행별 정규화와 Newton–Schulz 강화 업데이트를 조합해 기울기 분포에 따른 학습률 민감도를 줄이고 대규모 모델에서도 안정성을 확보한다.
u-µP를 통한 width-독립 학습률 전이
Proxy 모델에서 얻은 최적 구성을 다섯 개 Target 사이즈에 직접transfer해 폭(width)에 따른 학습률 변화를 제거하고 대규모 확장을 용이하게 한다.
공개 데이터 배제 및 합성 데이터 확대
Pretraining에서 공개 데이터 배제를 기본으로 하고, Finetuning에서 45% 공개 데이터 포함. 내부 observability와 합성 데이터의 비중을 증가시켜 일반화 성능을 강화한다.
핵심 아이디어 이해하기
단계1: 기본 개념으로 시작하면, Transformer의 자기-주의 기능은 시계열 데이터의 다변적 관계를 포착할 수 있지만 시퀀스 길이가 길어질수록 연산과 메모리 비용이 급증하고, 기존 자동회귀(decoding) 방식은 예측 단계에서 누적 오차를 유발한다. 단계2: Toto 2.0은 CPM으로 다수의 미래 패치를 한 번에 예측하도록 학습해 단일 패스 디코딩의 전체 파라미터 관여를 가능하게 한다. 또한 분위수(head)로 확률분포를 직접 추정하고, NorMuon으로 가중치를 뉴런 단위로 균형 있게 업데이트한다. 단계3: 데이터 구성과 하이퍼파라미터 전이를 하나의 레시피로 확장해 다섯 규모의 모델에서 일관된 성능 향상을 달성하고, BOOM/GIFT-Eval/TIME에서 SOTA를 기록한다. 단일 레시피의 확장성은 더 큰 데이터, 더 큰 모델에서의 일반화와 추론 속도 개선으로 연결된다.
방법론
- 전체 접근 방식: 디코더-온리 트랜스포머를 기반으로 CPM, quantile 헤드, NorMuon, Patch Embedding 등을 적용한다. 2) CPM의 수학적 기초: 입력을 N 패치로 구성하고, M 구간을 마스크로 표시한 상태에서 fθ를 한 번 호출해 pˆi를 얻고 손실을 평균한다. 3) Quantile Head의 학습: y와 qˆτ에 대해 pinball 손실 ρτ를 이용해 9개 분위수를 예측하고, 예측 분위수 간 교차를 방지한다. 4) NorMuon의 업데이트: vt를 각 행별로 추정하고 Wt’를 Wt−1 − η Ot / sqrt(vt+ε)로 갱신하며, β2 기반의 변화적 가중치를 행 단위로 조절한다. 5) 데이터 구성 및 학습 전략: 4m/22m 모델은 3.4T 포인트, 313m/1B/2.5B는 5.04T 포인트의 데이터를 학습하며, 10m 프록시에서 u-µP를 통해 각 타깃 사이즈에 동일 구성을 전이한다. 6) 평가 및 파인튜닝: BOOM/GIFT-Eval/TIME 벤치마크에서 CRPS, MASE를 사용해 성능을 비교하고, FnF 엔스블링으로 추가 성능을 확인한다.
관련 Figure
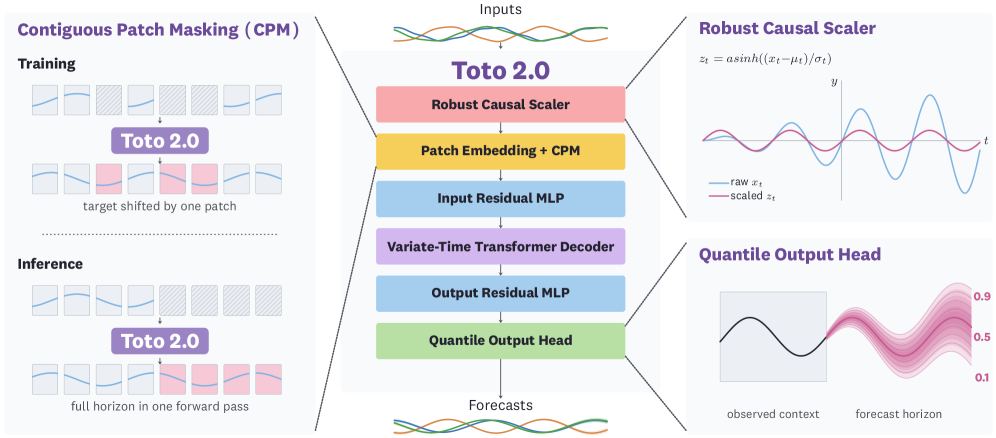
CPM, quantile head, NorMuon 등 핵심 구성요소의 흐름과 위치를 시각적으로 보여준다. 아키텍처의 주요 구성요소가 한 눈에 파악된다.
Toto 2.0 아키텍처 다이어그램(CPM, quantile head 등)

하이퍼파라미터 전이의 핵심 아이디어를 시각적으로 설명한다. 프록시 모델에서 얻은 설정을 목표 사이즈에 직접 적용하는 과정을 보여준다.
Proxy Model과 u-µP 흐름도
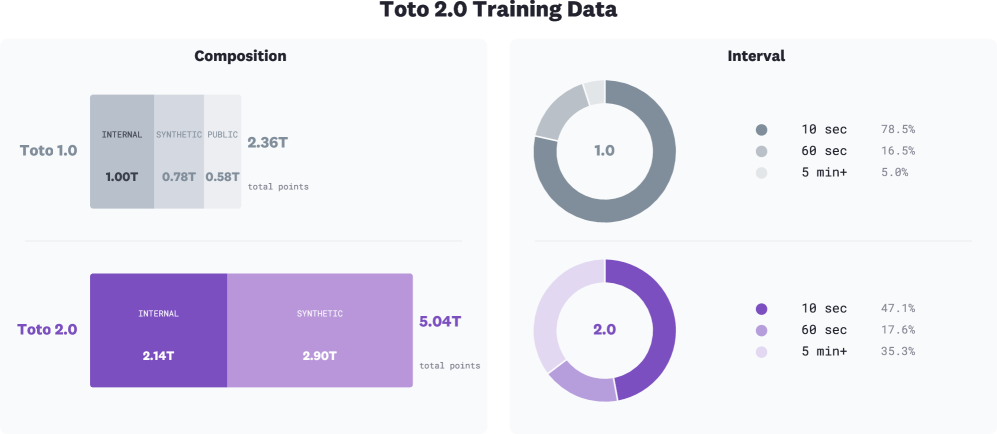
훈련 데이터 구성을 Internal Observability, Synthetic, Public 데이터의 비중과 interval 구성을 도식화한다. 데이터 믹스의 변화가 학습에 미치는 영향을 시각적으로 전달한다.
Toto 2.0 Training Data 구성 도식
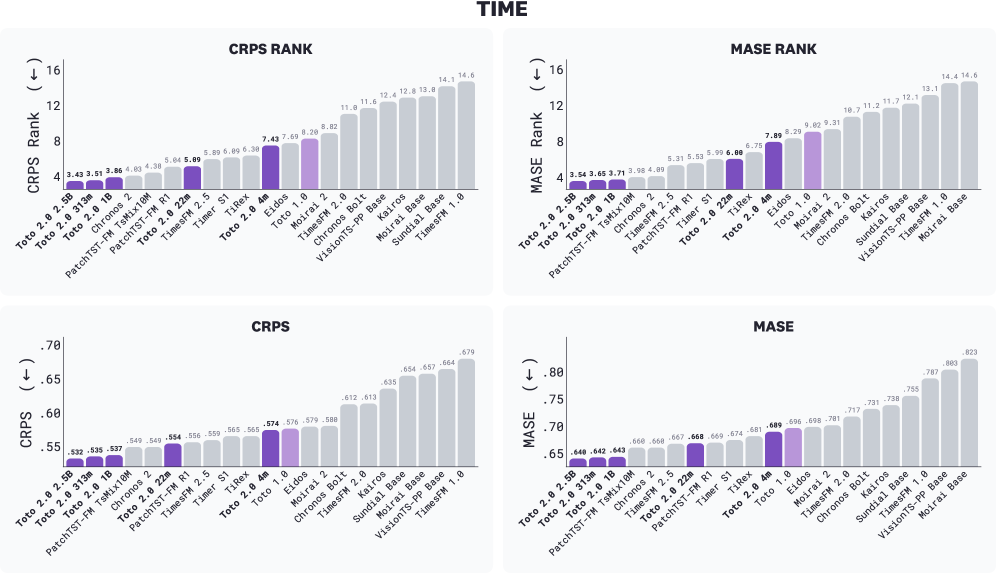
주요 결과
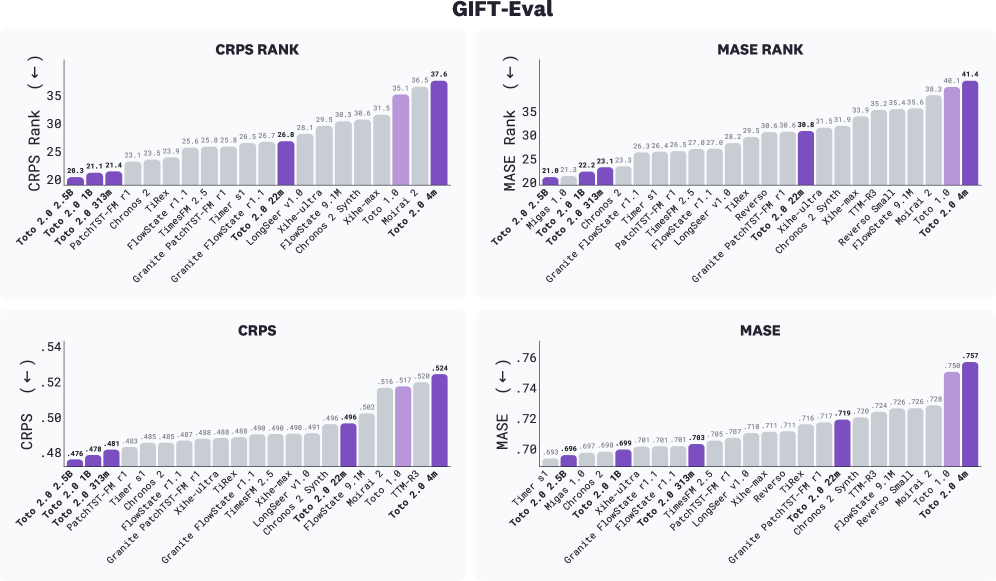
- 벤치마크 상의 주요 결과: Toto 2.0 사이즈는 모든 벤치마크에서 최상위를 차지했다. BOOM에서 2.5B의 CRPS 순위는 3.88, 1B는 3.96, 313m은 4.26으로 나타났고, 22m은 5.53, 4m은 7.17이다. GIFT-Eval에서 2.5B가 CRPS 20.3, 1B가 21.1, 313m이 21.4로 상위권을 차지했고, 2.5B-FT는 파인튜닝에서 두 번째, Toto 2.0 FnF는 모든 메트릭에서 1위를 차지했다. TIME 벤치에서 Toto 2.0 사이즈는 모든 메트릭에서 상위 3위를 차지했고, 2.5B가 CRPS 3.43, MASE 3.54로 선두를 차지했다. 2) 추론 속도 및 안정성: CPM 도입으로 단일 패스 디코딩이 가능해 대형 모델의 추론 속도가 크게 개선되었고, 4,096스텝 horizon에서 Chronos-2와 비교해도 대등하거나 빠른 편이다. 3) 장기 예측의 구조 유지: 2.5B는 8,192 스텝 horizon에서도 다중 스케일 구조를 비교적 유지하며, 4m은 제한된 예측 길이에서 구조가 소실되었다. 4) 데이터/전이의 영향: 공개 데이터의 배제는 프리트레이닝 단계에서 오히려 일반화에 도움이 되었고, 파이프라인의 데이터 구성은 Finetuning에서 공개 데이터 비중을 일정하게 조절하는 방향으로 확장되었다.
관련 Figure
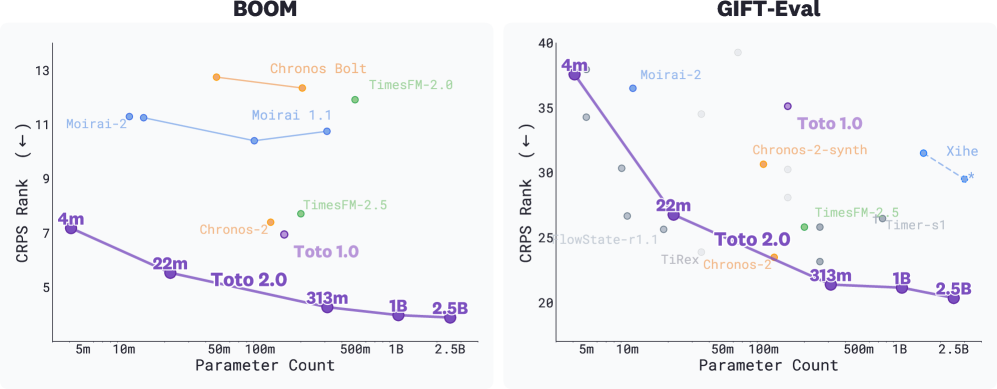
논문의 주요 주장인 파라미터 수 증가에 따른 성능 개선이 시각적으로 확인된다. Toto 2.0 가족은 Pareto 프런티어 상에 위치하며, 큰 모델일수록 두 벤치에서 기대치에 근접한다.
BOOM과 GIFT-Eval의 CRPS 순위 대비 파라미터 수 비교 via 산점도.
GIFT-Eval에서 Toto 2.0 계열이 상위권을 유지함을 시각적으로 보여준다. 2.5B-FT/FnF가 추가적으로 강력한 성능을 낸다.
GIFT-Eval에서 CRPS 순위 비교 그래프
FnF 엔세블링 및 Toto 2.0의 상대적 기여도를 시각화한다. Toto 2.0 폼의 다중 모델 조합이 최상위 성능을 내는 것을 보여준다.
GIFT-Eval 리더보드 - 타 모델 종합 비교
한계점
장기 예측에서의 구조 유지 한계 및 훈련 데이터 구성의 의존성 문제, 실제 운영 환경에서의 데이터 분포 변화에 대한 일반화 한계가 존재한다. 또한 대규모 모델의 학습 비용과 배포 비용은 여전히 높은 편이며, 공개 데이터에 대한 의존도 감소가 실제 현업 응용에서의 성능 편차를 발생시킬 수 있다.
실무 활용
Toto 2.0은 시계열 데이터에서 대규모 모델의 확장성을 실증하고, 단일 학습 레시피로 다양한 규모에서 고성능 예측을 가능하게 한다. 공용 데이터 의존을 감소시키고 내부 데이터+합성 데이터의 효율적 혼합으로 일반화 성능을 높인다.
- 실시간 인프라 모니터링 예측 및 알림 시스템 개선
- 다양한 도메인으로의 일반화 테스트를 통한 벤치마크 구축
- 합성 데이터 기반의 시계열 pretraining 설계
- 대규모 모델의 비용-효과 분석 및 엔드포인트 배포
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.