TL;DR
에이전트형 LLM의 입력 컨텍스트가 길어지면서 프리필링이 주된 병목이 된다. 기존의 전체 파이프라인에 저비트 양자화를 적용하면 디코딩 품질이 악화될 수 있는데, Mix-Quant은 프리필링에만 NVFP4 양자화를 적용하고 디코딩은 BF16으로 유지해 계산 효율과 생성 품질의 균형을 달성한다. 이로써 긴 맥락과 다회 상호작용이 요구되는 에이전트형 인퍼런스의 효율을 크게 개선한다.
왜 중요한가
에이전트형 LLM의 입력 컨텍스트가 길어지면서 프리필링이 주된 병목이 된다. 기존의 전체 파이프라인에 저비트 양자화를 적용하면 디코딩 품질이 악화될 수 있는데, Mix-Quant은 프리필링에만 NVFP4 양자화를 적용하고 디코딩은 BF16으로 유지해 계산 효율과 생성 품질의 균형을 달성한다. 이로써 긴 맥락과 다회 상호작용이 요구되는 에이전트형 인퍼런스의 효율을 크게 개선한다.
핵심 기여
Phase-aware quantization 설계
프리필링은 NVFP4 W4A4 양자화를 적용하고, 디코딩은 BF16으로 유지하는 이원 경로를 도입해 긴 컨텍스트에서의 계산을 크게 줄이고 생성 안정성을 확보한다.
NVFP4 양자화의 수학적 기초 및 구현
4-bit microscaling FP4 형식(NVFP4)을 사용하고, 블록 크기 g=16의 로컬 스케일링과 텐서 레벨 스케일링의 이중 스케일링으로 RTN 양자화를 적용한다. qi = ΠFP4(xi / (αx σb(i))); x̂i = αx σb(i) qi; σb = ΠE4M3(maxi∈b |xi| / (αx qmax)).
Prefill-Decode Disaggregation 아키텍처
_prefill 경로에서 NVFP4로 KV 캐시를 생성한 후 decode 경로로 전달하고, 신규 KV 엔트리는 BF16.decode 경로에서 작성하여 KV 캐시의 정합성 문제를 피하고 성능을 유지한다.
실험적으로 확인된 성능/품질 트레이드오프
2–3×의 프리필링 속도향상을 달성하고, 에이전트적 벤치마크에서 대부분의 성능 저하를 회복한다. 예를 들어 Qwen3-8B에서 Mix-Quant Avg는 41.45로 BF16의 42.85에 근접하며, Gemma-4-31B-it은 BF16 대비 77.63 대비 77.14로 근접하다. 또한 긴 컨텍스트 및 사고 기반 벤치마크에서도 NVFP4의 단독 적용보다 우수한 결과를 보인다.
핵심 아이디어 이해하기
출발점: 긴 컨텍스트와 다중 턴 환경에서 프리필링이 compute-집약적이며 디코딩은 토큰별로 민감하다. 따라서 전체 파이프라인에 동일한 양자화를 적용하면 성능 저하가 크지만, 프리필링의 고병목 영역을 FP4로 가속하고 디코딩은 고정밀 BF16을 유지하면 누적 오차를 줄이고 전체 성능 손실을 최소화할 수 있다. 방법: NVFP4의 4-bit 양자화를 프리필링에 적용하고, 디코딩은 BF16 경로를 유지하는 이원화된 실행 흐름을 구성하며, 프리필링 단계만 disaggregation으로 KV 캐시를 전달해 시스템 차원의 효율을 높인다. 결과적으로 프리필링에서 최대 약 3×의 속도향상과 전체 성능의 대다수 회복을 달성한다.
관련 Figure
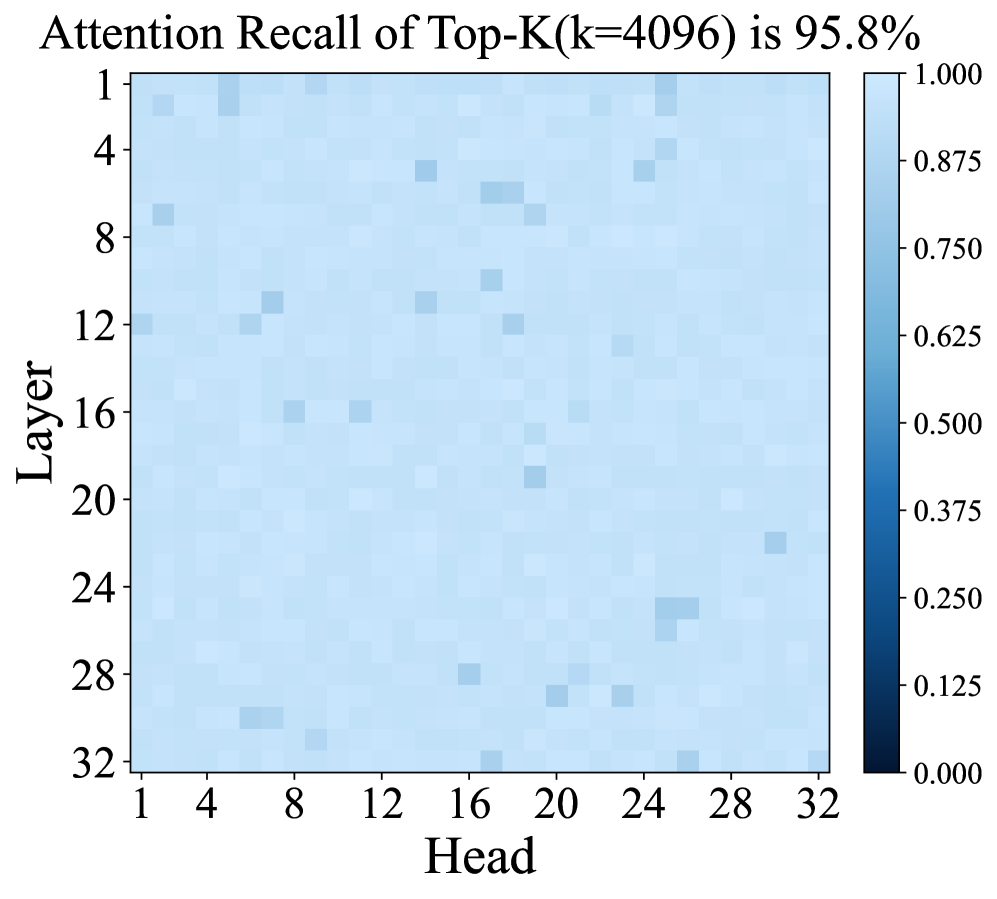
해당 히트맵은 프리필링 단계의 컨텍스트가 토큰 간 주의 집중에서 큰 비중을 차지하지 않는다고 주장하는 근거인 Attention mass 집중 현상을 시각적으로 확인시켜 주며, 프리필링 양자화의 영향이 주요 입력 토큰에 제한될 수 있음을 뒷받침한다.
Attention Recall Top-K(4096) 히트 매스 heatmap으로, 128K 컨텍스트에서 상위 토큰 4096개가 전체 주의 집중의 약 95.8%를 차지한다는 것을 나타낸다.
방법론
- 문제 정의: agentic LLM에서 프리필링이 긴 컨텍스트 때문에 병목이 된다. 2) 핵심 설계: FP4 양자화를 프리필링에 적용하고 디코딩은 BF16으로 유지하는 phase-aware 이원 경로를 구성한다. 3) 구현 세부: NVFP4는 4-bit 표준 형식으로, block size g=16의 로컬 스케일 σb와 텐서 레벨 스케일 αx를 사용하며 RTN 양자화를 적용한다. 4) 시스템 레벨: 프리필링 경로와 디코딩 경로 간 KV 캐시 전송은 NIXL 기반으로 수행되며, 분해(disaggregation) 설계가 오버헤드를 줄인다. 5) 실험 설계: LongBench-V2, AA-LCR 등 장-context 벤치마크와 agentic 벤치마크(BFCL v4, LongMemEval, τ2-bench)에서 BF16, NVFP4, Mix-Quant 간 비교를 수행한다.
관련 Figure
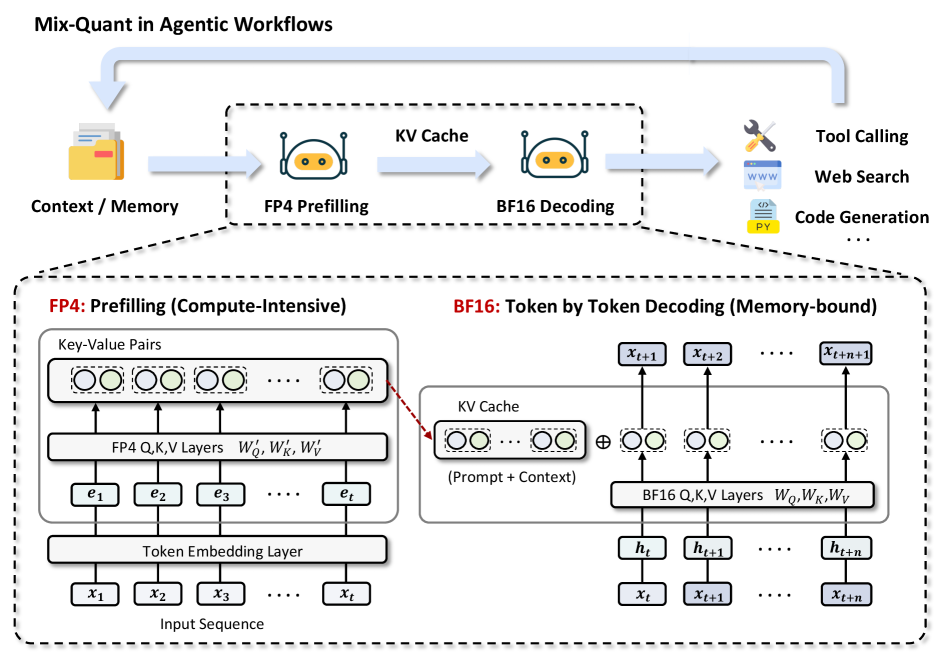
이 그림은 프리필링과 디코딩의 분리된 흐름과 디바이스 간 KV 캐시 전송의 시스템 구성을 직관적으로 보여주므로, 논문의 핵심 아이디어인 phase-aware 양자화와 disaggregation의 동작 원리를 보강한다.
Mix-Quant의 실행 흐름을 보여주는 다이어그램으로 Context/Memory에서 FP4 Prefilling을 거쳐 KV Cache를 만들고 BF16 Decoding으로 토큰생성을 하는 흐름을 시각화한다.
주요 결과
주요 벤치마크에서 Mix-Quant은 NVFP4 단독 적용으로 인한 품질 저하를 크게 완화한다. 예: Qwen3-8B Avg: BF16 42.85, NVFP4 38.64, Mix-Quant 41.45. Qwen3.5-9B Avg: BF16 77.31, NVFP4 70.37, Mix-Quant 74.68. Gemma-4-26B-A4B-it Avg: BF16 66.07, NVFP4 55.95, Mix-Quant 61.67. Gemma-4-31B-it Avg: BF16 77.63, NVFP4 78.26, Mix-Quant 81.39. 또한 Reasoning/Long-Context 벤치마크에서도 NVFP4의 손실을 Mix-Quant가 상당 부분 회복한다(예: LongBench-V2 Avg 62.11에서 Mix-Quant 61.00). Prefill Stage Speedup은 시퀀스 길이/배치 크기에 따라 BF16 대비 평균 약 3×를 달성한다.
관련 Figure
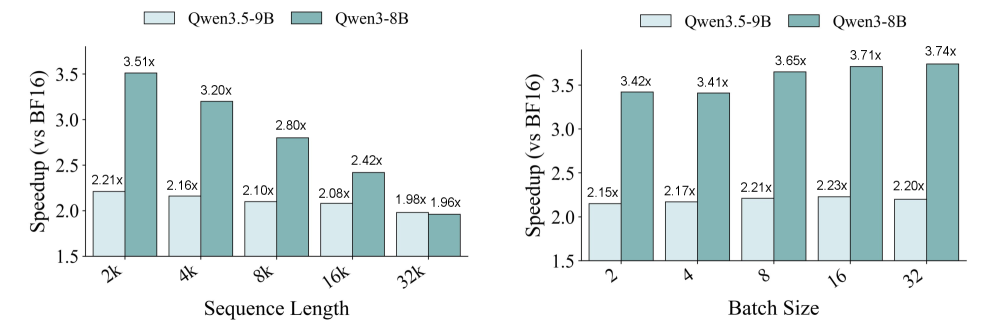
prefill 스테이지의 성능 향상을 직접적으로 보여주는 그림으로, 2k~32k 시퀀스 길이와 다양한 배치 크기에서 Mix-Quant가 BF16 대비 평균적으로 약 3×의 속도향상을 달성함을 근거한다.
End-to-end prefill latency speedup 그래프: 시퀀스 길이와 배치 크기 변화에 따른 BF16 대비 Mix-Quant의 속도향상을 보여준다.
기술 상세
아키텍처: Mix-Quant은 프리필링(Prefilling) 경로를 NVFP4 W4A4 양자화로 처리하고, 디코딩 경로는 BF16으로 유지하는 이원 경로(disaggregation) 아키텍처를 채택한다. 프리필링은 Context/Memory → FP4 Prefilling → KV Cache의 흐름으로 진행되며, 디코딩은 BF16 Token-by-Token Decoding으로 진행되고 KV 엔트리는 실시간으로 업데이트된다. 구현: NVFP4는 16-element 블록의 로컬 스케일 σb와 텐서 레벨 스케일 αx를 사용하며, qi = ΠFP4(xi / (αx σb(i))) 및 x̂i = αx σb(i) qi로 양자화/복원한다. σb는 max(|xi|)에 따라 E4M3 블록 스케일링으로 결정되고, qmax는 FP4의 최대 절댓값을 FP8 그리드로 라운드한다. лат결: RTN 양자화를 사용하고, 블록 크기 16에 맞춘 GEMM 차원에 맞춰 배열을 구성한다. 비밀도/컴퓨트 흐름: 프리필링에서 대규모 행렬곱이 주로 차지하므로 양자화가 큰 효과를 낸다. 디코딩에서 작은 수의 토큰이 누적적으로 생성되므로 정밀도 저하가 누적될 수 있어 BF16 경로를 유지한다. 구현상의 시스템 이점: 프리필링-디코딩 분리(disaggregation)로 KV 캐시의 불일치를 최소화하고, NIXL 기반 KV 캐시 전송으로 커널 전환 및 형식 변환 오버헤드를 줄인다.
실무 활용
Mix-Quant은 에이전트형 LLM 인퍼런스의 입력-Heavy 워크로드를 대상으로 프리필링에 FP4 양자화를 적용하고 디코딩은 BF16으로 유지하는 phase-aware 양자화 프레임워크이다. 이를 통해 프리필링의 계산 비용을 크게 줄이고 생성 품질을 안정적으로 유지한다.
- 긴 컨텍스트를 다루는 에이전트형 시스템에서 프리필링 시간을 단축해 응답 지연을 감소시키는 경우
- 도구 호출/메모리 관리가 잦은 다단계 상호작용 시퀀스의 KV 캐시 구축 시간 절감
- 하드웨어가 NVFP4를 지원하는 환경에서 대규모 모델의 서비스 처리량 향상
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.