TL;DR
전문적 미디어 편집은 인터페이스 밀집성과 장기간 실행 흐름으로 인해 일반 GUI 에이전트의 한계를 넘어선다. CutVerse는 186개의 작업, 7개 애플리케이션, Windows VM 기반 실행환경, 멀티모달 로그를 구조화된 GUI Trajectory로 변환하고 Milestone 기반 자동 평가를 통해 실제 포스트프로덕션 워크플로우에서의 에이전트 성능을 체계적으로 비교한다.
왜 중요한가
전문적 미디어 편집은 인터페이스 밀집성과 장기간 실행 흐름으로 인해 일반 GUI 에이전트의 한계를 넘어선다. CutVerse는 186개의 작업, 7개 애플리케이션, Windows VM 기반 실행환경, 멀티모달 로그를 구조화된 GUI Trajectory로 변환하고 Milestone 기반 자동 평가를 통해 실제 포스트프로덕션 워크플로우에서의 에이전트 성능을 체계적으로 비교한다.
핵심 기여
186개 작업의 포괄적 데이터셋
프리미어 프로, 애프터 이펙트, 포토샵 등 7개 전문 애플리케이션에서 긴 호라이즌 편집 워크플로를 186개로 설계하고 3,484개의 atomic GUI 상호작용을 기록한다. 데이터는 2.43시간의 고충실도 recording과 인간 검증 태스크를 포함한다.
멀티모달 파서 및 VM 기반 평가 인프라
원시 멀티모달 로그와 화면 캡처를 Grounding된 GUI trajectory로 변환하는 경량 파서를 구축하고, 고충실도 Windows VM에서 실행 환경의 재현성과 확장성을 확보했다.
Milestone QA 기반 자동 평가 프로토콜
Milestone 단위의 시각-시간 상태 전이를 검증하는 멀티모달 QA 체계를 도입하고, GPT-5.4와 Claude-4.6-Opus를 교차 평가자로 활용해 평가 신뢰성을 확보했다.
실제 벤치마크에서의 한계 분석
SOTA 비전-언어 모델의 엔드투엔드 태스크 성공률은 36.0% 수준으로 낮으며, 코어 편집 태스크에서의 성능 저하와 오류 누적 현상을 드러낸다.
다양한 도구 및 교차 도메인 도전
AIGC 도구와 전통 소프트웨어를 연계한 생성-합성 파이프라인의 확장성과 일반화 가능성을 실험하고, 크로스-애플리케이션 편집의 복잡성을 분석한다.
핵심 아이디어 이해하기
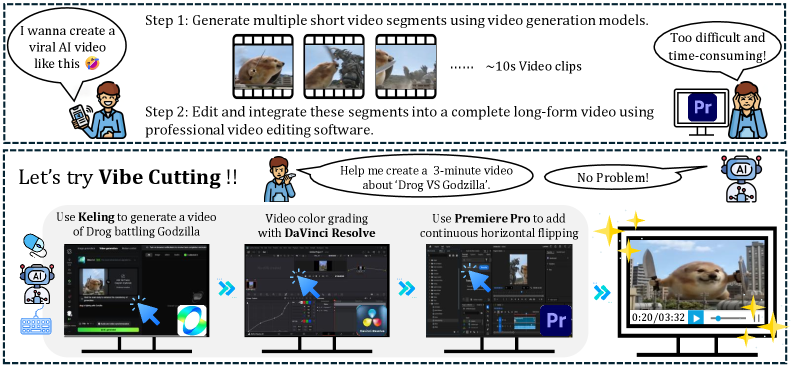
출발점: 전문 미디어 편집은 인터페이스 밀집성과 긴 실행 흐름을 갖고 있어, 기존 GUI 에이전트의 간단한 클릭 중심 접근은 불충분하다. 해결 원리: 시각-피드백만으로 작동하는 저수준 GUI 조작으로 구성하고, 로그를 Milestone 단위의 구조적 Trajectory로 분해해 긴 호라이즌에서도 맥락을 유지한다. 차이점: Milestone별 검증을 통해 실행의 진짜 진행 여부를 확인하고, 다중 소프트웨어 간의 크로스-피드백 루프에서의 오류 누적을 드러낸다. 지속적 맥락 유지, 픽셀-정밀 그라운딩, 다툼 없는 멀티툴 협업이 핵심 장애물이다.
방법론
Pipeline 구성: Recording → Parsing → Evaluation의 순으로 진행되며, 186개 태스크를 7개 애플리케이션에서 수행한다. 파서는 고프레임 레이트 화면 영상과 로우 레벨 I/O 로그를 매핑해 구조화된 Milestone Trajectory로 변환하고, MILestone QA를 통해 각 상태 전이를 검증한다. 실행 엔진은 Windows VM 기반으로, 저수준 마우스/키보드 이벤트만 사용하도록 제약해 재현성과 안정성을 보장한다. 실험 설정은 4× RTX 5090 하드웨어, OSWorld 계열 프롬프트를 사용하는 Claude Opus 4.6, Qwen3-VL-32B-T, UITars-1.5-7B, EvoCUA-32B, Gemini 3 Flash 등 5개 모델을 대상으로 온라인 실행으로 수행한다. 평가 지표는 Task/ Milestone 성공률, Milestone QA의 근거 및 Consistency Gap 등을 포함한다.
관련 Figure
벤치마크의 핵심 구성요소인 Recording-Parsing-Evaluation 흐름과 Milestone 기반 평가를 시각화한다.
CutVerse 데이터 파이프라인 및 벤치마크 구조를 요약하는 도해

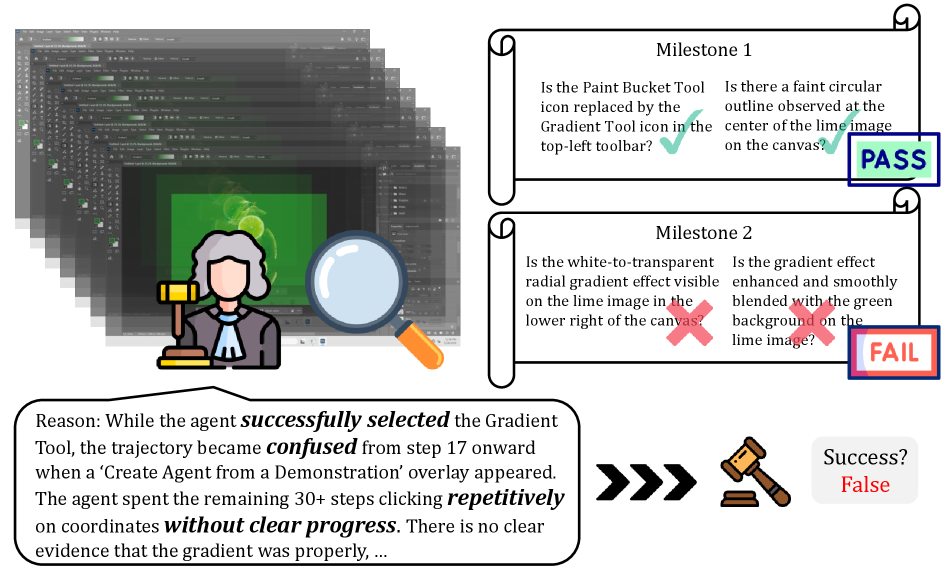
Milestone 중심의 질의응답 기반 자동 평가 구조를 보여준다.
Milestone QA 기반 자동 평가 파이프라인 도식
대화형 QA로 중간 상태를 검증하는 방식의 예를 제공한다.
Milestone-QA 사례(통과/실패) 및 실패 원인 주석 예시
주요 결과
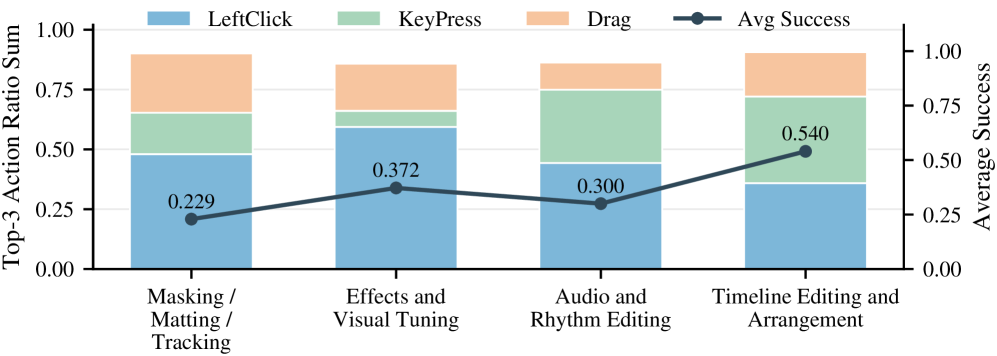
주요 벤치마크에서 SOTA 모델의 엔드투엔드 태스크 성공률은 36.0%에 불과하다. Milestone 수준의 성능은 일반적으로 태스크보다 높지만, 코어 미디어 편집(Effects, Visual Tuning, Audio 등)에서의 성공률은 낮다. Table 4의 실제 도구별 실행 정확도는 Keling, ComfyUI, JianYing 등의 도구에서 양호한 편이나 After Effects 등 프로페셔널 툴에서 급격히 하락한다. Milestone QA는 98.3%(GPT-5.4) 및 99%(Claude-4.6-Opus) 정도의 인간 합의율을 보이며 자동화 평가의 신뢰성을 입증한다.
관련 Figure
태스크 분포와 도구-도메인별 비율이 제시되어 벤치마크의 실용적 난이도와 포커스를 보여준다.
태스크-당 도메인별 분포 차트(After Effects, DaVinci 등)
실무 활용
CutVerse를 활용해 GUI 에이전트의 실제 업무 적합성을 체계적으로 평가하고 개선할 수 있다.
- 프로페셔널 편집 워크플로의 자동화 비교 및 개발
- AIGC 도구와 전통 소프트웨어 간의 교차 파이프라인 연구
- Long-horizon 멀티모달 작업의 디버깅 및 평가 도구
- 벤치마크를 통한 파이프라인 구성요소의 최적화
- 데이터 수집 및 주석 자동화의 기반으로 활용
코드 공개 여부: 공개
코드 저장소 보기키워드
추가 이미지 분석
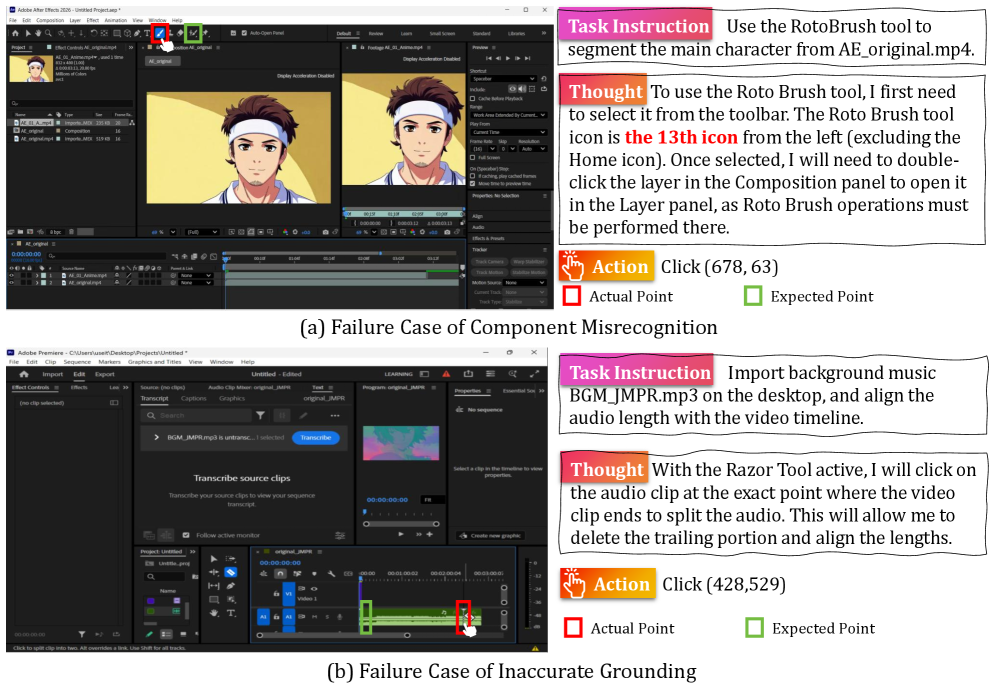
컴포넌트 인식 실패, 정밀한 그라운딩 부재, 글로벌 맥락 부족 등 실패 원인을 시각적으로 제시한다.
프로페셔널 툴의 실패 사례 스크린샷 예시
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.