TL;DR
대형언어모델의 논리추론은 주어진 전제에서 결론이 반드시 도출되어야 하는 규칙적 추론이다. 기존 벤치마크는 템플릿 의존성이나 불충분한 형식 주석으로 인해 실제 추론 능력을 왜곡할 수 있다. LLMEval-Logic은 현실적 시나리오를 기반으로 forward authoring과 Z3 검증, 전문가 루브릭을 결합하고, 5단계의 adversarial hardening 워크플로우를 통해 frontier 모델의 한계를 보다 명확하게 구분한다.
왜 중요한가
대형언어모델의 논리추론은 주어진 전제에서 결론이 반드시 도출되어야 하는 규칙적 추론이다. 기존 벤치마크는 템플릿 의존성이나 불충분한 형식 주석으로 인해 실제 추론 능력을 왜곡할 수 있다. LLMEval-Logic은 현실적 시나리오를 기반으로 forward authoring과 Z3 검증, 전문가 루브릭을 결합하고, 5단계의 adversarial hardening 워크플로우를 통해 frontier 모델의 한계를 보다 명확하게 구분한다.
핵심 기여
Forward-authored, Z3-audited Chinese logic benchmark
실제 상황을 담은 NL 문제를 새로 작성하고 이를 Z3로 검증 가능한 정형 표현과 연결한다. Base(단일 질문)와 Hard(다중 질문) 두 하위 세트를 제공한다.
Closed-loop adversarial hardening workflow
Decider → Proposal → Review → Answering → Verification의 5단계로 구성되며 6가지 하드닝 전략을 적용해 아이템의 후보 공간을 재구성한다.
Rubric-based NL→FL faithfulness 평가
논리 관계, 명시적 제약, 쿼리 정합성을 분해한 RubricAtoms를 사용해 모델이 생성한 형식화의 의미를 정밀하게 평가한다.
3Run, 14 frontier LLMs 평가
세 차례 반복 평가와 14개 최전선 모델군의 NL 추론과 형식화 모두를 측정하여 성능 차이와 한계를 드러낸다.
Normalization + Z3 verification pipeline
Lexical/Syntactic/Semantic/Type-Parameter의 4단계 정규화와 Z3 기반의 형식 검증으로 형식화의 일관성과 정합성을 확보한다.
공개 릴리즈와 재현성 강화
벤치마크, 워크플로우, 감사 기록을 공개하여 재현성과 신뢰성을 높인다.
핵심 아이디어 이해하기
단계적 접근으로 NL 문제의 의미를 최대한 인간 친화적으로 구성하되, 이를 자동 검증 가능한 형식으로 변환하는 것이 핵심이다. 첫째, forward authoring으로 현실적 시나리오를 직접 작성하고, 둘째, LLM의 NL→FL 변환을 Z3 검증으로 교차 확인한다. 셋째, Rubric를 통해 형식화의 세부 요소를 개별적으로 검사하고, 넷째, Hardening 워크플로우로 아이템의 해결 공간을 의도적으로 확장/변형해 frontier 모델의 한계를 노출한다. 마지막으로 Base와 Hard 두 세트를 통해 단일질문 대비 다중질문 환경에서의 일반화 성능과 변형에 따른 민감도를 비교한다.
방법론
- Forward Authoring, Expert Review, Normalization, Z3 Formal Verification, Rubric Construction의 5단계 파이프라인을 통해 Base 아이템을 산출한다. 2) Hardening 파이프라인에서 Decider/Proposal/Review/Answering/Verification 다섯 역할이 교대로 작동하며 6가지 전략(add_branching, add_distractor_premise, change_question_to_set_output, add_uncertainty_or_multi_answer, add_counterfactual_variant, alias_and_coreference_variation)을 적용해 Hard 아이템을 만든다. 3) 평가 프로토콜에서 LLM-as-Judge가 NL-형식화의 정합성과 아이템의 정답 여부를 판단하고, Z3 실행 결과와 Rubric 합을 함께 고려한다. 4) Base/ Hard의 항목별 평가로 각 모델의 NL 추론 능력과 NL→FL 번역의 충실도를 구분한다.
관련 Figure
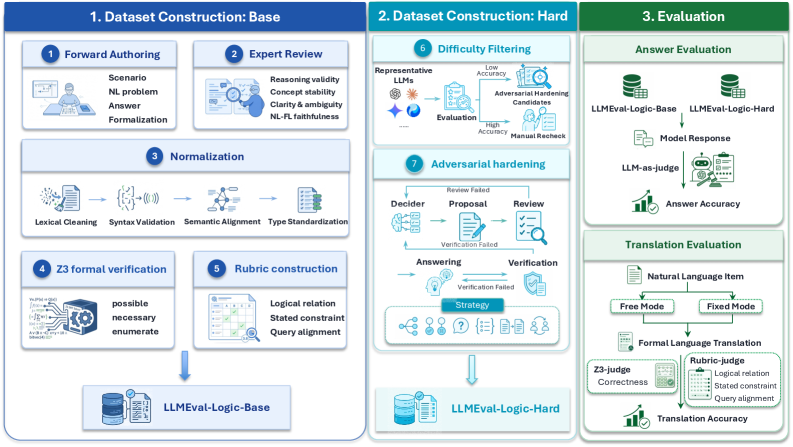
Figure 2의 파이프라인은 아이템의 forward authoring부터 Rubric 기반 평가, Hardening까지의 과정을 시각화해 LLMEval-Logic의 핵심 디자인을 요약한다.
LLMEval-Logic의 Base 구성 및 NL→FL 흐름을 요약하는 도식그래프. 아이템 구성, Normalization, Z3 검증, Rubric 평가, Adversarial Hardening의 흐름을 보여준다.
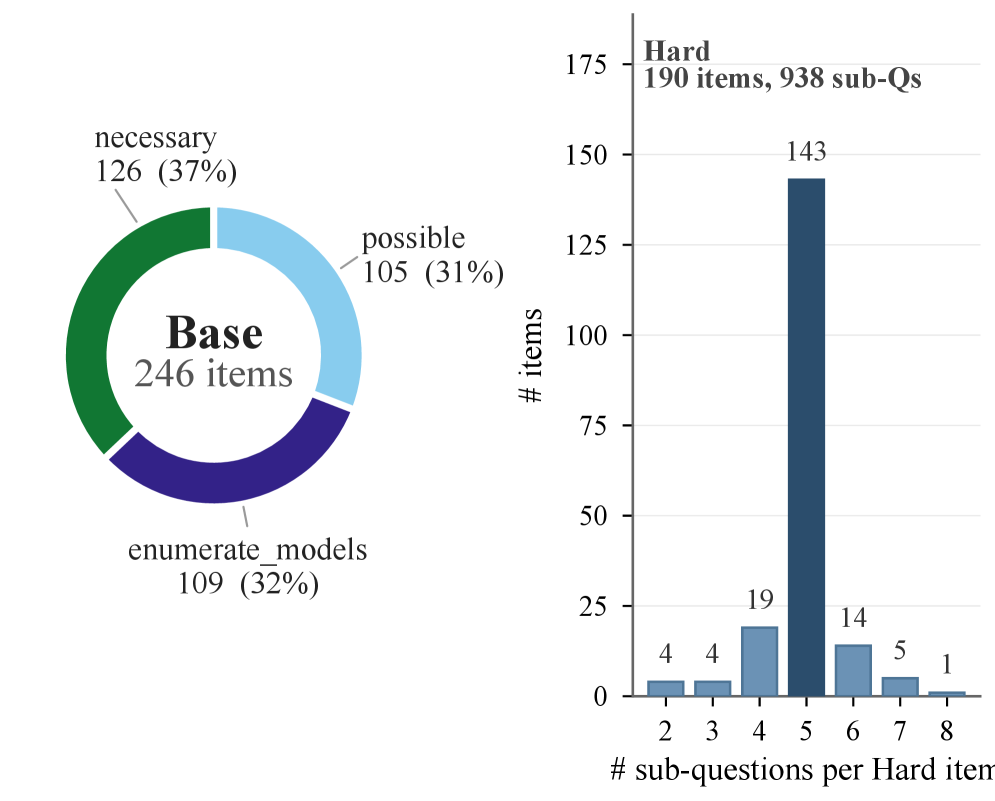
Figure 3은 Base와 Hard의 구성을 직관적으로 보여주며, Hard가 다중 서브질문을 포함한다는 점을 강조한다.
Base/Hard 구성의 예시와 아이템 배치를 나타내는 다이어그램. Base 246개, Hard 190개 항목 구성의 분포를 포함한다.
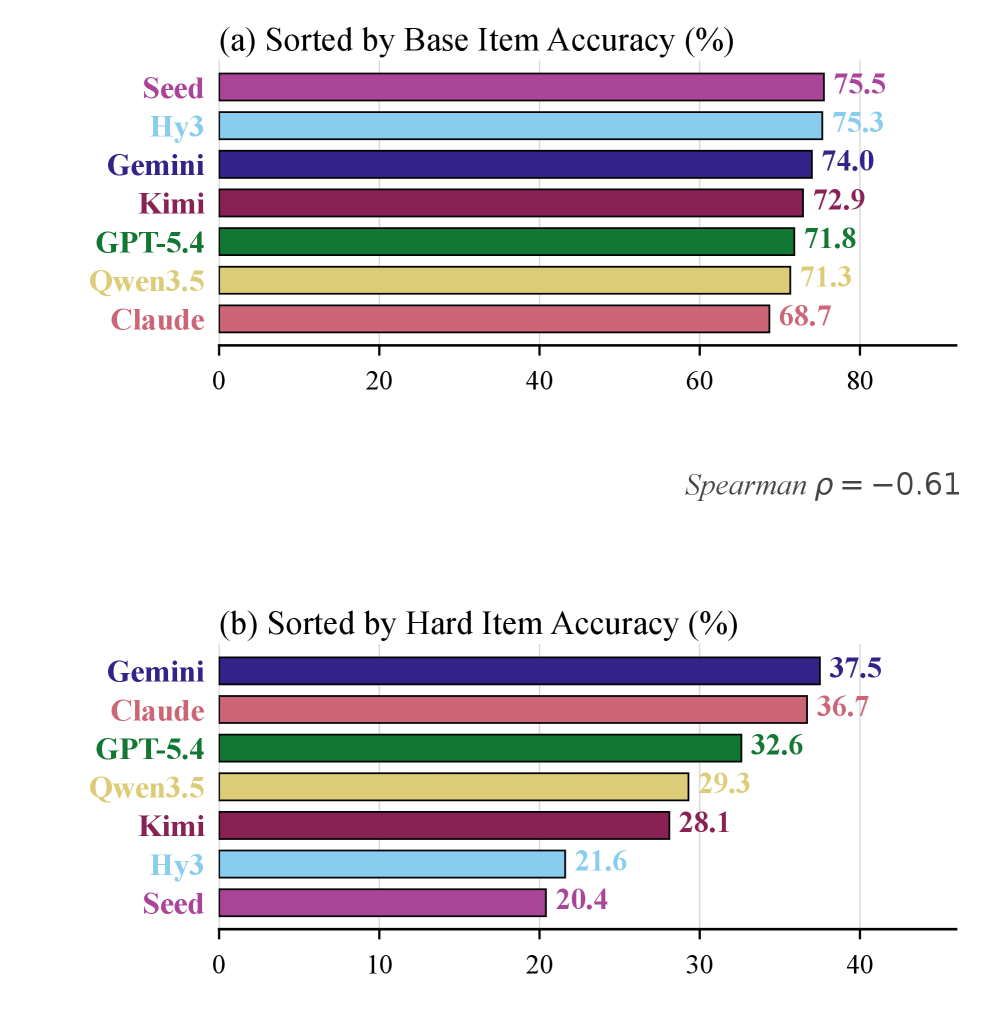
Figure 3-4 계열 도식은 Hardening의 구조적 요인을 통해 Hard 문제의 난이도가 커지는 원인을 직관적으로 보여준다.
Hard subset의 난이도 기작을 설명하는 도식. Counterfactual recomputation, 6가지 hardening 전략의 효과를 시각화한다.
주요 결과
Bases에서의 Item Acc.은 평균 65.1%; Hard에서의 Item Acc.는 22.9%로 하락하며, Best Hard는 37.5%에 그친다. Z3+Rubric의 합산 성능은 Fix Symbol에서 60.16%에 도달하는 모델이 최댓치였다(Gold 100%). 14개 프런티어 모델군은 Hard 아이템에서 대규모 성능 저하를 보였고, 오류 분석을 통해 Counterfactual 재계산, 후보 공간 유지, 증거 원천 관리 등의 실패 패턴이 확인되었다. 평가 프로토콜은 3회 반복Run과 두 추가 Frontier Judge로 IAA를 확인하였으며, Inter-judge Cohen’s κ는 0.87–0.92 범위의 거의 완벽한 수준으로 재현성과 신뢰성을 확보했다.
관련 Figure
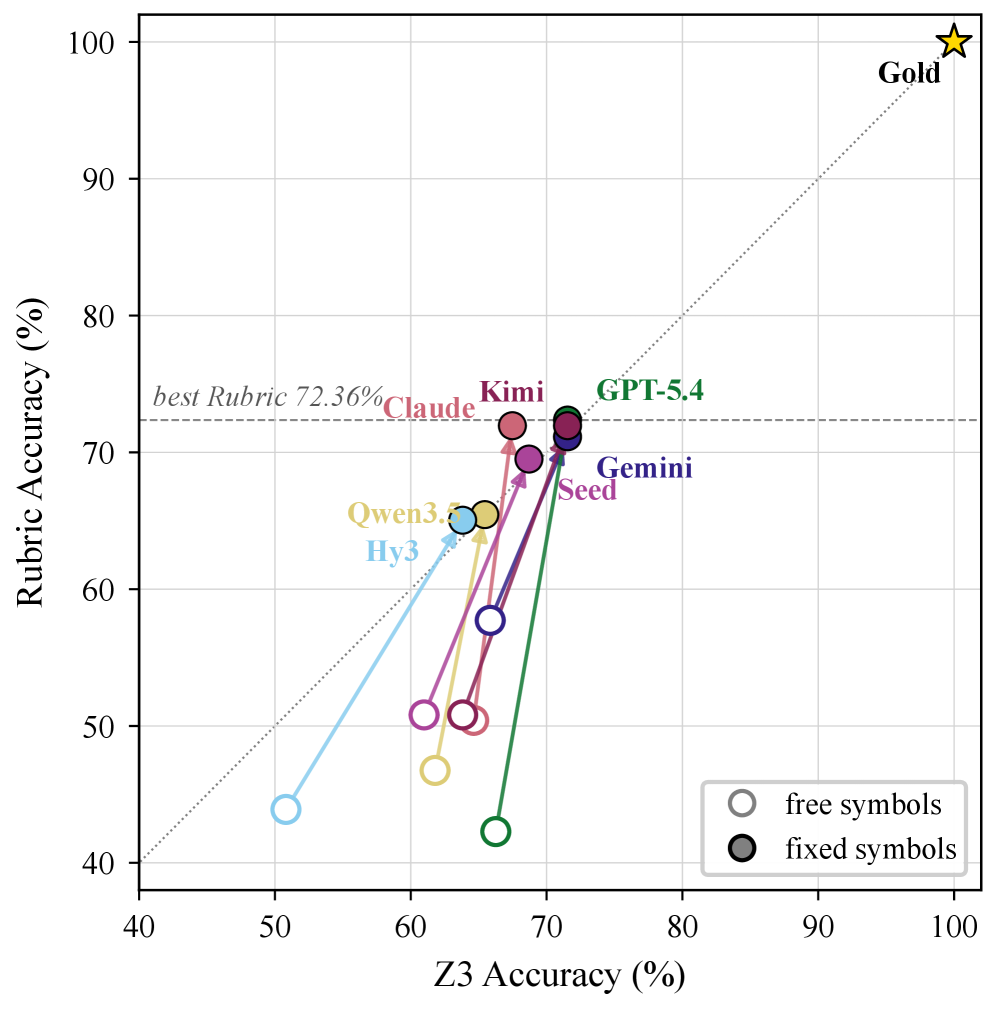
Figure 7은 NL→FL 평가에서 Z3와 Rubric의 상호 보완 관계를 시각화하여 두 신호의 한계를 설명한다.
Z3와 Rubric 기반 형식화 평가의 비교 도표. Base/Hard에서 Z3, Rubric, Both의 비율을 제시한다.
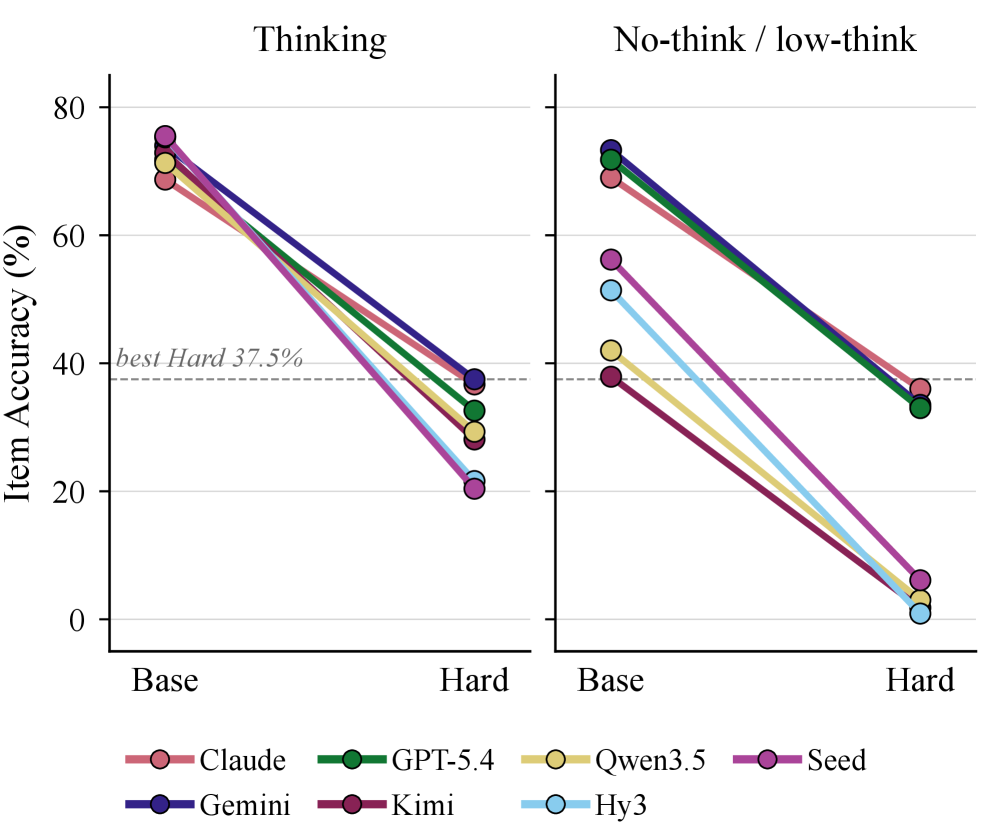
Figure 5–6에서 세대 간 성능 차이와 하드 문제에서의 특성 차이를 보여주며, 가족 간 민감도 차이를 강조한다.
Base→Hard Item Accuracy의 가족 간 차이를 보여주는 시각화.
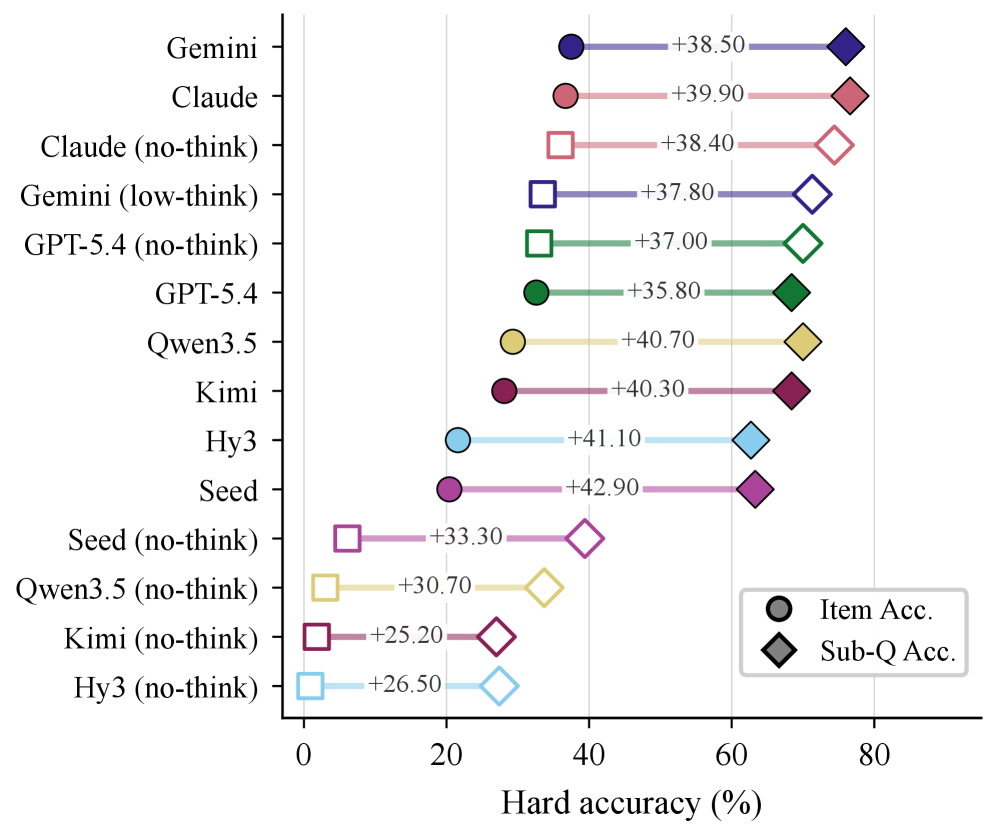
Sub-Q 단위의 정확도와 Item 단위의 정확도 간의 차이가 Hard Problem에서 크게 벌어진다는 점을 강조한다.
Hard 아이템의 Sub-Q vs Item Accuracy의 차이를 시각화한 그래프.
기술 상세
2-6단락 구성의 연구 방법론; 4-layer Normalization(L1-L4)과 Z3 기반 형식 검증, Expert Rubrics 설계, 5단계 Hardening 워크플로우, 6가지 Hardening 전략의 구체적 조합 및 작동 원리, 평가 프로토콜의 LLM-as-Judge 운영 원칙, Z3/ Rubric의 보완적 신뢰성 분석을 포함한다.
한계점
논문은 중국어 아이템 중심으로 설계되었으며 확장 시나리오, 고차원 논리(고차/모달/확률 논리)로의 일반화가 필요하다. Z3 검증은 형식화의 타당성에 대한 보증을 제공하지만 NL 항목과 formalization의 완전한 동등성은 여전히 전문가 루브릭의 역할에 의존한다.
실무 활용
고급 LLM의 NL 추론 및 NL→FL 번역의 신뢰성 평가에 실용적 도구를 제공한다. 현실적 시나리오에서의 추론 과제와 형식화의 정합성 평가를 통해 벤치마크의 난이도 유지와 비교 가능성을 보장한다.
- frontier LLM 성능 비교와 연구 개발 방향 설정
- NL→FL 변환의 신뢰도 진단 및 교정
- 규칙 기반 추론의 검증 및 자동화 평가 파이프라인 구성
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.