TL;DR
에이전트의 스킬은 description, body, metadata 등 다중 필드로 구성되며, 각 필드의 플랫폼 제약이 존재한다. 단일 목표로 최적화를 시도하는 기존 방법은 이러한 다중 제약 하에서 발생하는 trade-off를 놓치기 쉽다. MOCHA는 Chebyshev 스칼라화와 하이퍼볼륨 기반의 탐색, 그리고 탐색-활용 전환을 통해 비선형(non-convex) 영역까지 포괄하는 Pareto front를 발견하고, 6개 스킬에서 일관된 성능 향상을 달성한다.
왜 중요한가
에이전트의 스킬은 description, body, metadata 등 다중 필드로 구성되며, 각 필드의 플랫폼 제약이 존재한다. 단일 목표로 최적화를 시도하는 기존 방법은 이러한 다중 제약 하에서 발생하는 trade-off를 놓치기 쉽다. MOCHA는 Chebyshev 스칼라화와 하이퍼볼륨 기반의 탐색, 그리고 탐색-활용 전환을 통해 비선형(non-convex) 영역까지 포괄하는 Pareto front를 발견하고, 6개 스킬에서 일관된 성능 향상을 달성한다.
핵심 기여
다목적 제약하의 스킬 최적화 문제 formalization
SKILL.md의 description, body 및 메타데이터 등 다중 필드를 대상으로 한 구조적 다목적 최적화를 공식화하고, 정확성( correctness )과 규정 준수( compliance ) 간의 트레이드오프를 다룬다.
Chebyshev 스칼라라이제이션과 무작위 가중치 샘플링
Stage 1에서 w ∼ Dirichlet(1)를 샘플링해 p를 선택하고 sw(p) 최소화로 Pareto front의 모든 영역에 접근한다.
Hypervolume Contribution 기반 탐색(HVC) + Threshold Annealing
Stage 2에서 HVC를 활용한 방향 불문 탐색과, 예산이 소진될수록 Chebyshev 탐색으로 전환하는 온도 조절(annealing)으로 front를 확장하고 수렴시킨다.
두 단계 평가 및 예산 관리
Minibatch 평가로 후보를 먼저 평가하고, 일정 기준을 넘으면 전체 검증으로 commit하는 2단계 평가 구조를 사용한다.
6개 스킬에 대한 종합 평가
1000 롤아웃의 같은 예산에서 MOCHA가 4개 태스크에서 seed_skill을 개선하지 못하는 baselines를 극복하고 평균 Correctness에서 최대 14.9%의 개선을 기록하며 Pareto-optimal 후보를 두배로 발견한다.
핵심 아이디어 이해하기
단계 1: 스킬은 다중 필드로 구성되며 각 필드의 제약이 존재한다. 단일 목표 최적화는 스킬의 trade-off를 놓친다. 단계 2: Chebyshev 스칼라라이제이션은 특정 가중치 벡터에 의존하지 않고 Pareto front의 모든 지점에 접근하게 해 주며, 비볼록 영역에서도 최적해를 찾을 수 있다. 단계 3: HVC 기반 탐색은 방향을 가리지 않고 front를 확장하고, annealing으로 초기의 다양성과 후반의 정확성을 균형 있게 추구한다.
방법론
전체 접근 방식은 Stage 1: 임의의 w ∼ Dirichlet(1)에서 p_parent를 선택하고 sw(p) 최소화를 통해 후보를 선택한다. Stage 2: p'를 mutation으로 생성하고, 2n 롤아웃으로 평가한 후, τ(b)에 따라 탐색(HVC 상승 여부) 또는 exploitation(sw 개선 여부) 중 하나를 적용한다. τ(b)는 b/B를 따라 지수적으로 감소하는 임계치이며, budget의 중간에 탐색에서 exploiting으로 전환한다. Hy pv 계산과 HVC의 차이점은 front 확장의 본질적 신호를 주며, Chebyshev는 특정 방향의 weakest region을 강화한다. 멀티-목적 평가를 위한 모든 목표는 0~1 구간으로 정규화되며, 기준점은 원점(0,0,0)이다.
관련 Figure
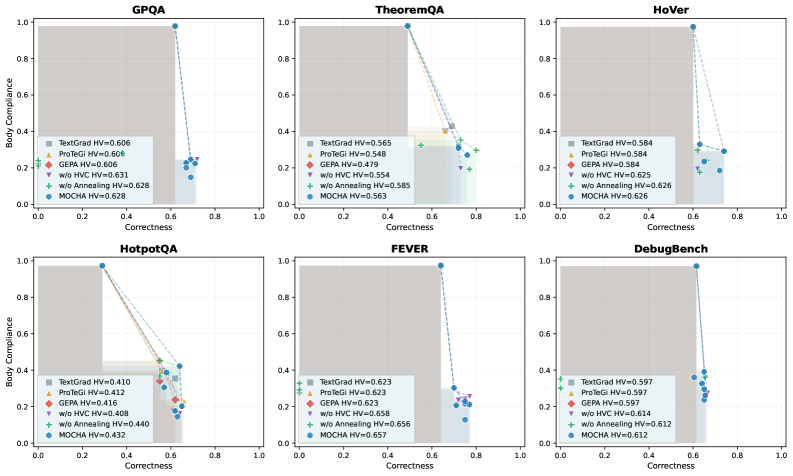
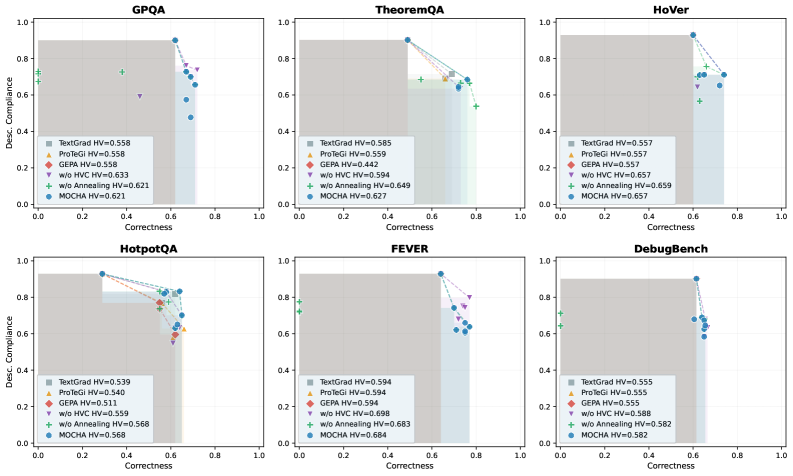
Figure 1b의 두 모드(탐색/활용) 전개를 보여주며 front 확장과 수렴의 원리를 시각적으로 뒷받침한다.
MOCHA의 탐색-활용 두 단계의 Pareto front 시각화
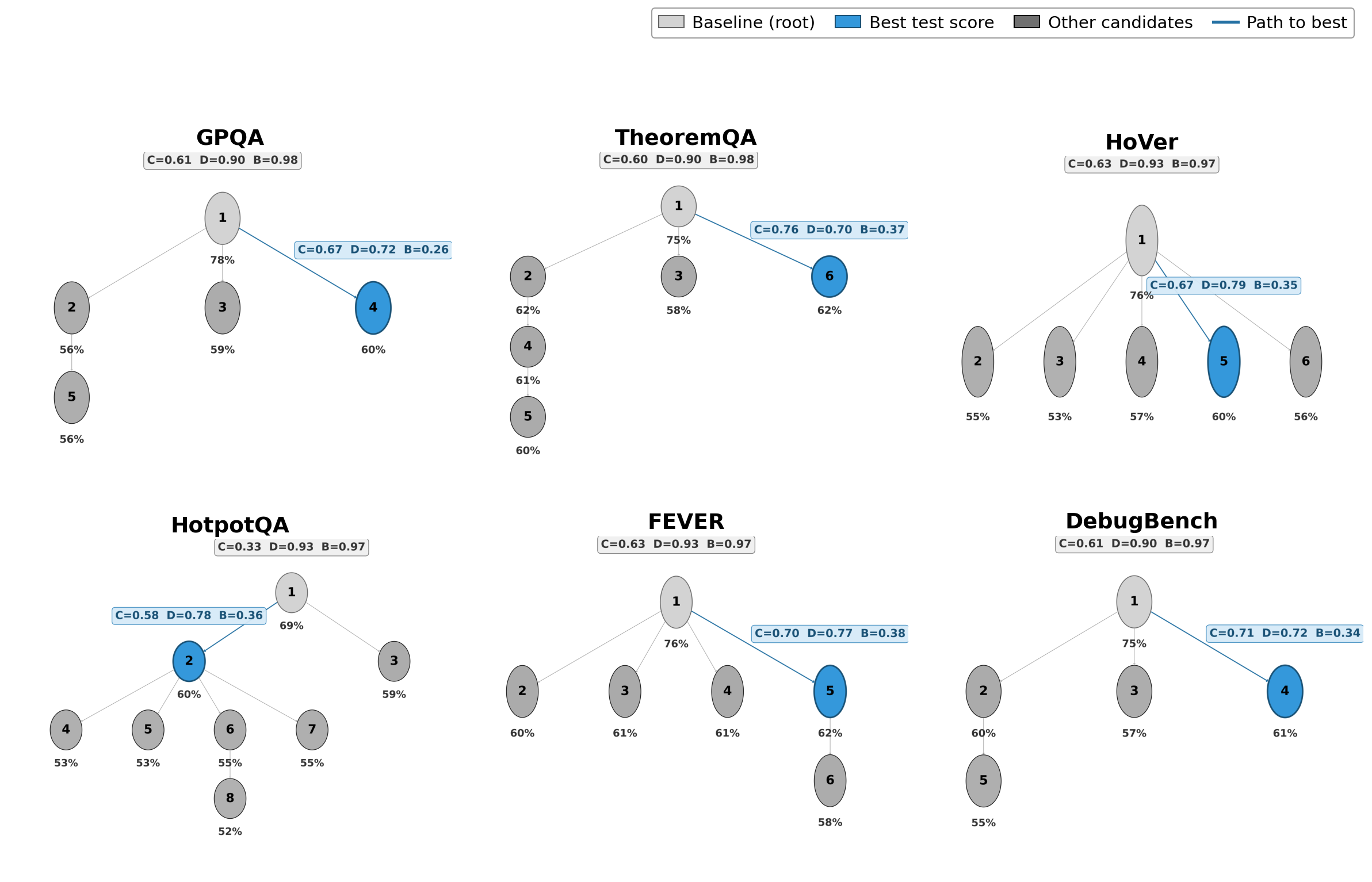
프롬프트 진화 트리로 커밋된 스킬 버전 간의 관계를 시각화하며, 최상위 점이 항상 루트에서 직선적으로 내려가지 않음을 보여준다.
MOCHA의 Prompt Evolution Trees
주요 결과
주요 벤치마크에서 MOCHA는 6개 스킬 모두에서 개선을 달성했다. 평균 Correctness는 strongest baseline(ProTeGi) 대비 7.5% 상대 증가를 기록하고, FEVER에서 14.9%, TheoremQA에서 10.4%의 개선을 보였다. Baseline이 seed_skill을 그대로 유지한 4개 태스크(GPQA, HoVer, FEVER, DebugBench)에서도 MOCHA는 Pareto 프런트를 다양하게 확장해 3.6개의 Pareto 점을 발견했고, Baseline은 1.6에 머물렀다. HV는 3D Front에서 MOCHA가 더 넓은 front를 형성하고 다수의 비지배 해를 찾았음을 나타낸다.
관련 Figure
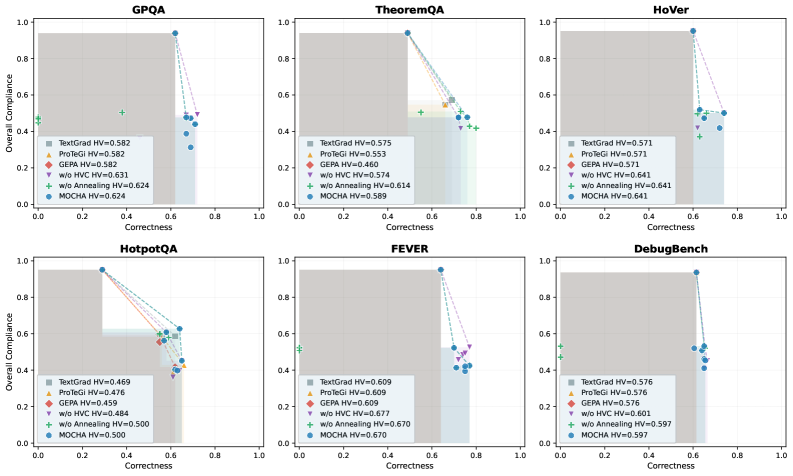
MOCHA의 HV와 Pareto front 확장 효과를 요약적으로 보여주며, 탐색-활용 전략의 이점을 수치적으로 뒷받침한다.
HV와 Pareto front에 대한 3D 탐색 지표 표/그래프
스킬별로 MOCHA variant들이 다양한 비지배 포인트를 형성함을 보여주며, baselines는 단일 operating point에 묶여 있는 경향을 나타낸다.
6개 스킬의 2D Pareto fronts
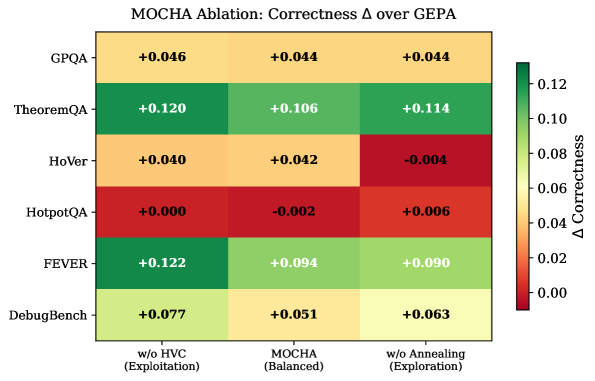
HVC 게이팅 제거, annealing 제거 등의 구성요소가 정답성에 미치는 영향을 색상으로 나타내어 탐색-활용 구성의 중요성을 시사한다.
Ablation heatmap: MOCHA 변형의 정답성 변화
기술 상세
MOCHA는 (i) 문제 정의: 스킬 정의를 다중 목적 지표로 평가하는 구조화된 MOO 문제로 정의, (ii) 알고리즘: Stage 1에서 Chebyshev 스칼라라이제이션 sw(p)을 이용해 부모 선택; Stage 2에서 mutation후 평가; (iii) 탐색-활용 전환: HVC 기반 탐색(HVC > τ(b))에서 Chebyshev 기반 탐색으로 전환; (iv) 예산 관리: 미니배치 평가 + 검증 평가를 통해 커밋 여부를 결정; (v) 정규화: 3개의 목표를 [0,1] 범위로 매핑; (vi) Mutations는 SKILL.md 제약을 준수하도록 설계되며, 편향 없이 동일 mutation 프로포저를 사용하여 모든 방법을 비교 가능하게 한다.
한계점
저비용-비충돌 작업에서 MOCHA의 이점이 작을 수 있음. annealing 스케줄은 고정 파라미터이며, 상황에 따라 적응적 스케줄이 더 robust 할 수 있음. SKILL.md 제약에 의한 컴플라이언스 지표는 특정 플랫폼의 스펙에 의존하며, 다른 제약 시스템에서는 변화가 생길 수 있음.
실무 활용
스킬 정의의 다목적 제약을 고려한 자동화된 프롬프트 진화 도구로 활용 가능하며, 여러 스킬 후보 간의 trade-off를 탐색해 deployment 선정을 돕는다.
- 스킬 라이브러리에서 description과 body의 토큰 한계를 넘지 않으면서 정확도와 규정 준수의 균형을 찾는 자동화
- 에이전트 파이프라인의 스킬 도큐먼트를 다목적 제약에 따라 최적화하고, Pareto 포인트를 기록해 downstream 선택에 활용
- 제한된 예산에서 최적의 front를 확보하기 위한 탐색/수렴 전략의 일반화
코드 공개 여부: 미확인
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.