TL;DR
RLVR는 LLM의 추론 능력을 향상시키기 위한 핵심 기법이지만, 일부 hard 예제는 정답을 포함한 positive rollouts를 관찰하더라도 학습되지 않는다. 본 연구는 이러한 unlearnability 현상의 존재를 체계적으로 입증하고, 데이터 증강이나 커리큘럼 학습이 이를 완화하지 못함을 보여준다. 이로써 RLVR 학습의 근본적 한계와 모델 표현의 품질이 중요하다는 시사점을 제시한다.
왜 중요한가
RLVR는 LLM의 추론 능력을 향상시키기 위한 핵심 기법이지만, 일부 hard 예제는 정답을 포함한 positive rollouts를 관찰하더라도 학습되지 않는다. 본 연구는 이러한 unlearnability 현상의 존재를 체계적으로 입증하고, 데이터 증강이나 커리큘럼 학습이 이를 완화하지 못함을 보여준다. 이로써 RLVR 학습의 근본적 한계와 모델 표현의 품질이 중요하다는 시사점을 제시한다.
관련 Figure
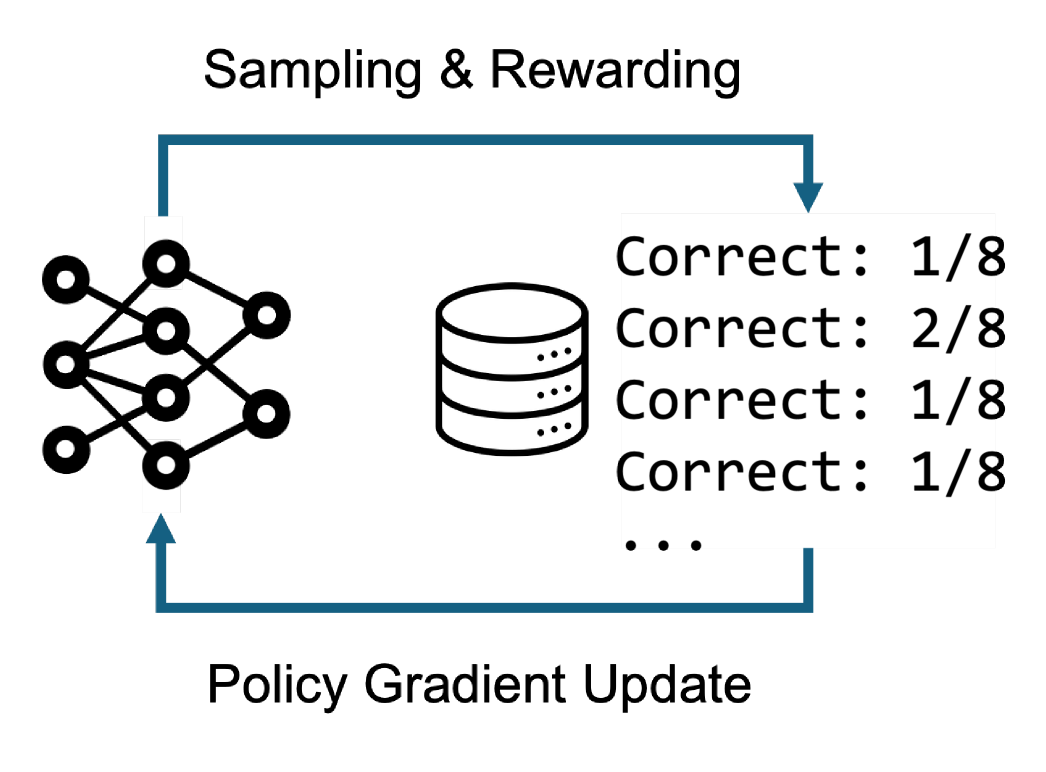
해당 도해는 unlearnable 예제가 존재하고 learning dynamics가 달라짐을 직관적으로 보여주며, 후속 실험의 gradient 분석과 연결된다.
RLVR 개념도 및 학습 흐름(샘플링/보상/업데이트)과 세 가지 예제군(Unlearnable/Learnable/Easy)을 시각화한 도해
핵심 기여
Unlearnability 현상의 실증적 발견
다양한 모델(Qwen2.5-0.5B, Llama-3.2-3B-Instruct, Qwen2.5-3B)에서 초기 난이도 상의 hard 예제 중 절반가량이 학습되지 않는 현상을 관찰했다. 이 현상은 positive reward가 존재하더라도 지속된다.
gradient similarity를 통한 표현 문제 진단
각 예제별 gradient를 계산해 예제 간 코사인 유사도를 측정한 결과, unlearnable 예제는 전체 데이터와의 gradient similarity가 현저히 낮아, 다른 그룹의 학습 신호가 이 예제에 전달되지 않음을 보인다.
데이터 증강의 한계와 mid-training의 효과
데이터 증강은 gradient similarity를 개선하거나 reasoning quality를 향상시키지 못했고, mid-training은 difficult 예제의 gradient similarity를 크게 개선하는 것으로 나타났다.
RLVR의 학습 역학에 대한 체계적 분석
초기 정책에서의 correct/incorrect rollout 간의 gradient 간섭 여부를 분석하여, unlearnable 예제에서 gradient 간섭이 핵심이 아님을 확인했다.
핵심 아이디어 이해하기
출발점: RLVR은 final answer의 정답 여부로 reward를 부여하는 구조로, 올바른 해답을 가리키는 intermediate reasoning의 품질은 보장되지 않는다. 가설1(positive rollout 희소성)과 가설2(clip/KL 제약에 의한 신호 소멸), 가설3(그라디언트 간섭) 모두를 실험적으로 점검했으나, unlearnability의 주된 원인은 분명한 표현 문제로 드러났다. 핵심 아이디어는 gradient similarity를 통해 각 예제의 학습 신호가 전체 데이터와 얼마나 잘 공유되는지 측정하고, unlearnable 예제가 학습 신호를 충분히 흡수하지 못하는 이유를 representation 차원에서 찾는 것이다.
관련 Figure

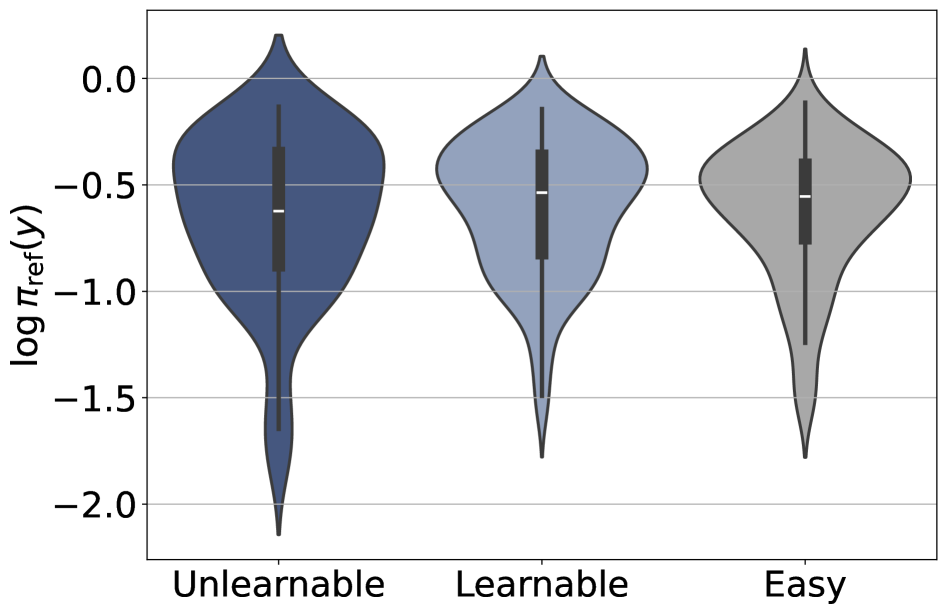
초기에는 Easy가 가장 높은 reasoning quality를 보이며 Unlearnable은 낮은 품질의 추론 패턴을 보인다. RLVR 학습이 진행되도 Unlearnable의 추론 품질 개선은 제한적이다.
Reasoning quality vs 초기 난이도(세 그룹 간 비교)
Unlearnable 예제는 다른 예제들과의 gradient similarity가 낮아, transfer가 어려움을 보인다. Learnable 예제는 gradient가 Broader training distribution과 더 잘 정렬된다.
Gradient similarity의 cross- 예제 비교: Unlearnable vs Learnable
방법론
단계별 구성
관련 Figure
Mid-training이 difficult 예제의 gradient similarity를 높여 학습 가능한 예제로의 전이를 촉진한다는 근거를 제공한다.
Gradient similarity 분포의 mid-training 변화
데이터 증강이 문제를 해결하지 못하고, 오히려 gradient 유사도 측면에서 차이가 큼을 보여준다. 따라서 semantically 비슷한 문제라도 최적화 공간에서는 다르게 작동한다.
증강 데이터(Dsim, Dsub)과 원본 Unlearnable 간의 gradient similarity 비교
주요 결과
주요 실험은 아래와 같다.
관련 Figure
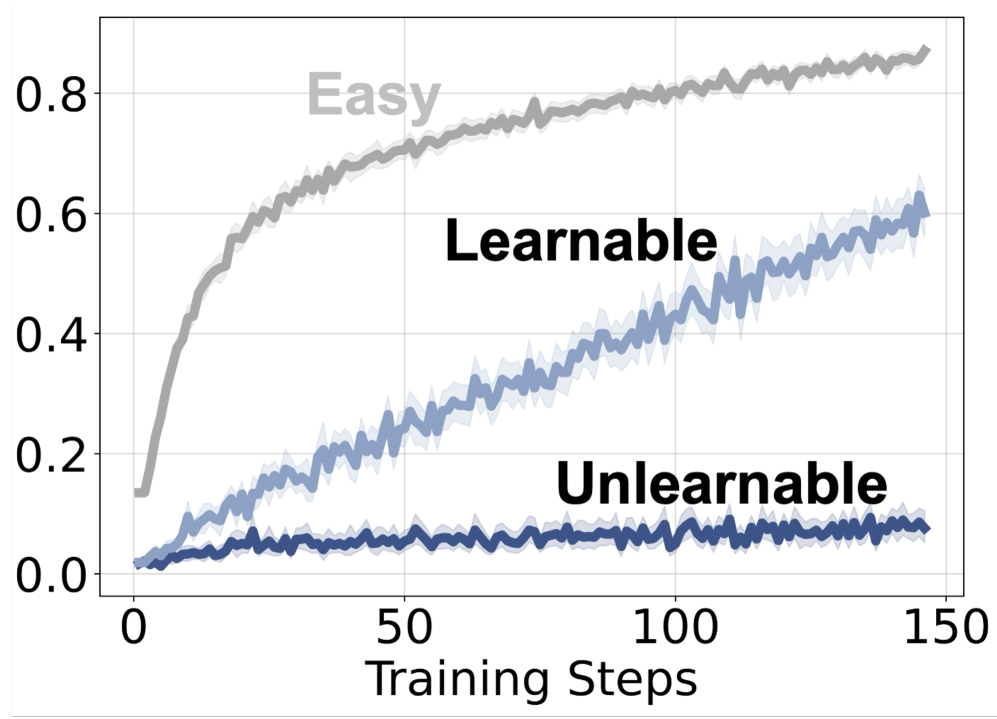
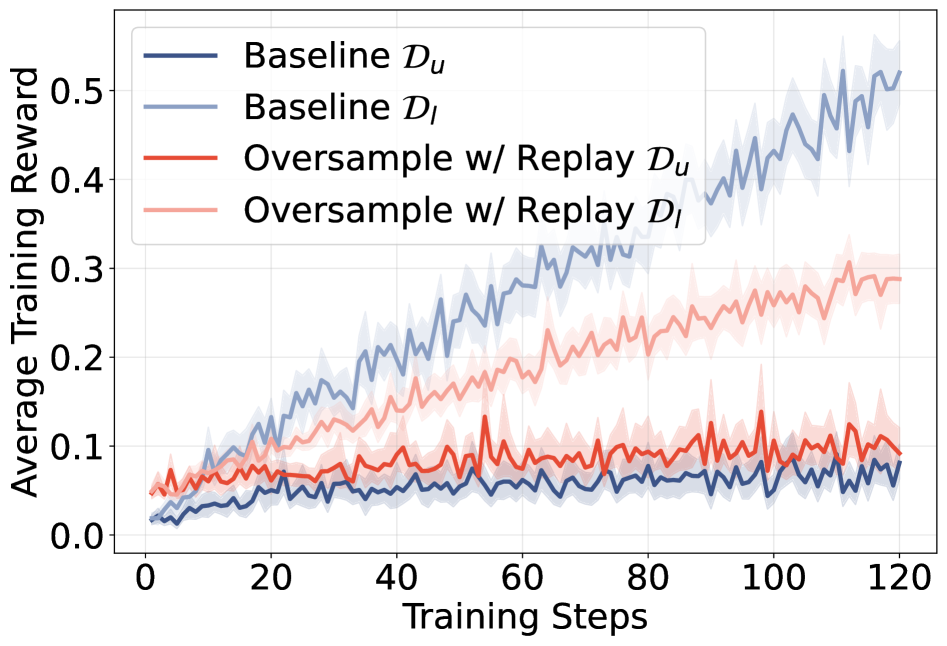
보상 곡선을 통해 unlearnable 예제가 학습되더라도 보상이 stagnate할 수 있음을 확인해, 학습 불가능성의 존재를 시각적으로 뒷받침한다.
training reward dynamics: Learnable vs Unlearnable vs Easy 간의 보상 변화
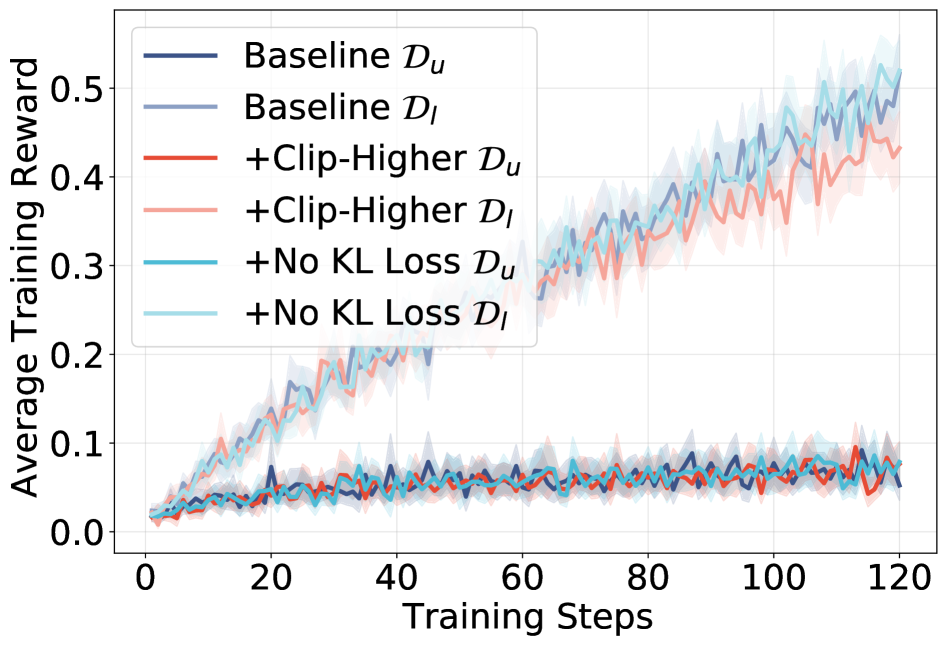
OctoThinker 계열의 mid-training은 gradient similarity를 개선하였고 학습 초기 정책의 품질 개선에 기여할 수 있음을 시사한다.
Mid-training 효과를 비교하는 추가 그래프
기술 상세
섹션별 개요
관련 Figure
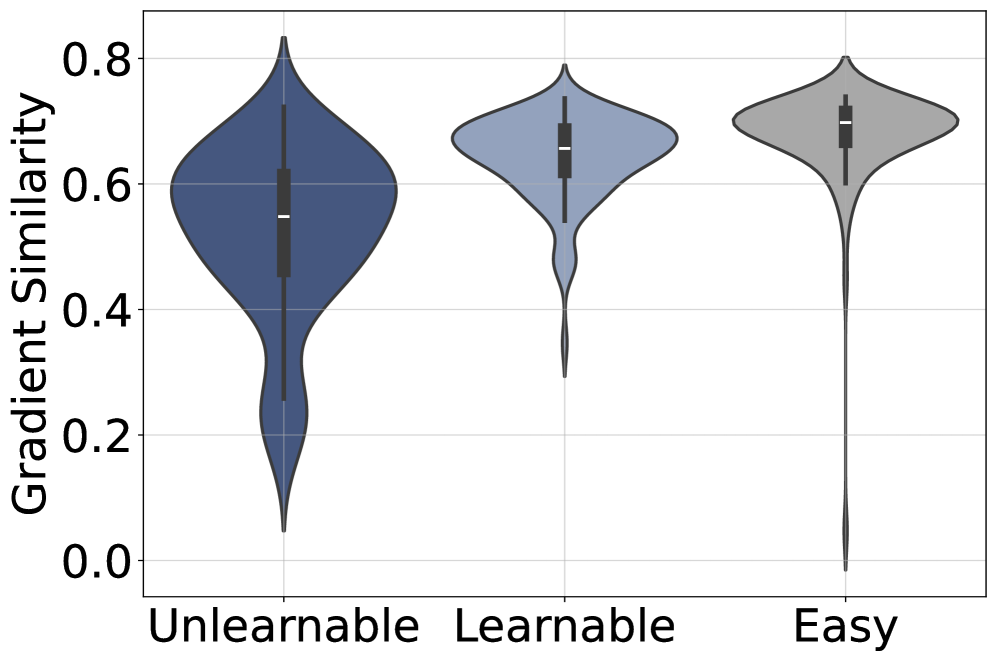
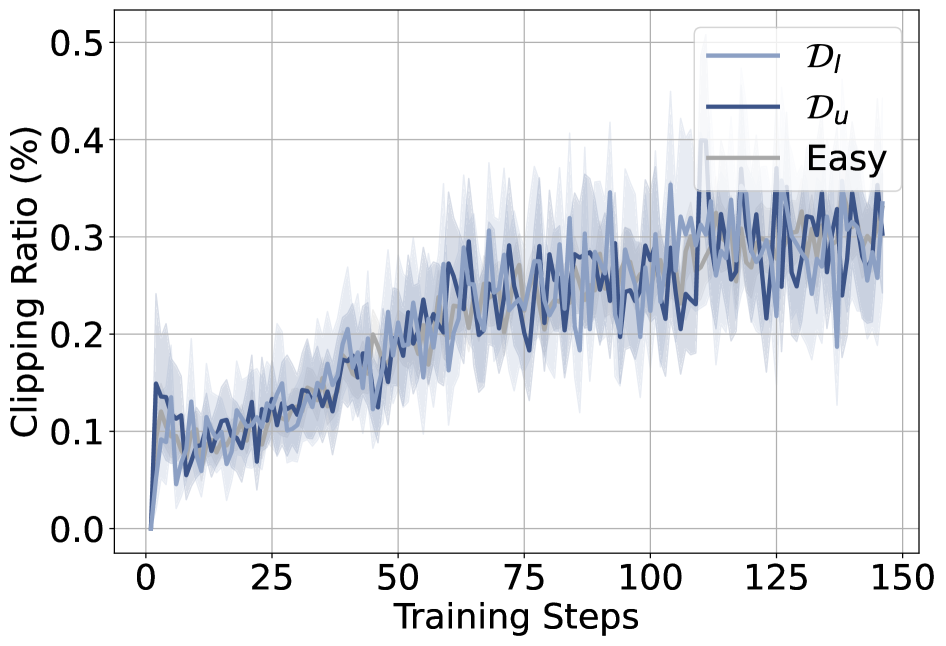
Unlearnable 예제의 gradient가 전체 데이터와 유사성이 낮고 outlier로 나타나 학습 신호가 공유되지 않음을 시사한다.
정확한 rollouts의 gradient similarity 분포(세 그룹 간 비교)
실무 활용
unlearnable 예제의 존재와 gradient 불일치 현상을 이해함으로써, RLVR 학습 파이프라인의 설계와 mid-training의 중요성을 재조명한다. 데이터 선택과 표현 학습의 조합이 RLVR에서 효과적으로 작동하는지에 대한 가이드를 제공한다.
- 학습 데이터에서 gradient similarity 기반으로 unlearnable 예제 식별 및 제거 또는 재표현
- mid-training 단계에서 표현 정렬과 gradient alignment를 강화하는 데이터 구성
- 데이터 증강의 한계를 보완하는 새로운 RLVR 커리큘럼 설계
- RLVR 전처리 단계에서 correct rollouts의 질과 분포를 더 정교하게 제어
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.