TL;DR
실세계 에이전트는 정보가 시간이 지남에 따라 지속적으로 업데이트되며 간섭이 발생한다. 기존 벤치마크는 독립적 기억과 단기적 재현에 집중해 장기 맥락의 상호작용과 기억 구성의 한계를 포착하지 못한다. MINTEVAL은 four domains에서의 지속적 업데이트와 간섭으로 인해 메모리 관리가 어려운 환경에서 기억의 검색, 구성, 집계 추론의 강건성을 평가한다.
왜 중요한가
실세계 에이전트는 정보가 시간이 지남에 따라 지속적으로 업데이트되며 간섭이 발생한다. 기존 벤치마크는 독립적 기억과 단기적 재현에 집중해 장기 맥락의 상호작용과 기억 구성의 한계를 포착하지 못한다. MINTEVAL은 four domains에서의 지속적 업데이트와 간섭으로 인해 메모리 관리가 어려운 환경에서 기억의 검색, 구성, 집계 추론의 강건성을 평가한다.
관련 Figure
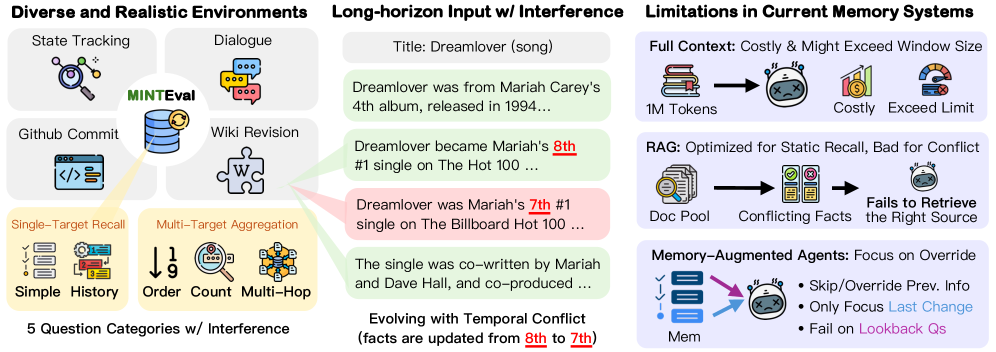
도메인 다양성 및 간섭 상황을 한 장으로 제시하여 연구의 구성과 목표를 시각적으로 전달한다. anchor_key: why_it_matters
MINTEVAL의 네 도메인과 다섯 질의 유형을 아이콘과 텍스트로 한눈에 보여주는 인포그래픽
MINTEVAL의 문제 정의와 간섭의 원인을 도식화하여, 연구의 필요성과 설계 의도를 직관적으로 보강한다. anchor_key: why_it_matters
Diverse Environments 및 Long-horizon Input w/ Interference 및 Limitations를 나타내는 다패널 도식
핵심 기여
Four-domain 인터랙션 환경
STATE TRACKING(bAbI), DIALOGUE(HorizonBench), Wiki Revisions, Git Commits의 네 도메인에서 지속적으로 업데이트되는 맥락과 간섭을 반영하는 분석 벤치마크를 제시한다.
단일-대상 재호출 및 다중 대상 집계 태스크
SINGLE-TARGET RECALL과 MULTI-TARGET AGGREGATION의 두 축으로 구성되며 Simple/History, Ordering/Counting/Multihop 등 5가지 질의 유형으로 기억의 저장 및 집계 능력을 평가한다.
7개 시스템에 대한 포괄적 평가
Full Context, Base RAG, HippoRAG, MemAgent, AtomMem, Mem-α, SimpleMem 등 7개 시스템을 Across 도메인으로 비교해 평균 27.9%의 정확도와 MemAgent의 33.4%를 보고한다.
오류 원인 및 설계 제약 분석
대다수 오류가 retrieval/memory construction에서 기인하며 lookback 및 aggregation 질의에서 취약함을 확인한다. 메모리 업데이트가 삽입에 편향되어 수정/삭제가 약한 경향이 나타난다.
간섭 완화를 위한 기법적 인사이트
Temporal cues(날짜/타임스탬프) 추가가 lookback 손실을 완화하고, chunk size 조정이 memory 업데이트의 필요성을 줄이는 등 간섭 완화 가능성을 시사한다.
도메인 간 일반화의 한계
도메인 간 성능 편차가 크며 cross-domain 일반화가 제한적임을 관찰한다(예: bAbI Simple에서 높은 성능, HorizonBench에서 저조).
핵심 아이디어 이해하기
출발점: 인터페이스가 서로 다른 업데이트로 얽힌 장기 맥락에서 Memory는 인코딩-저장-검색-추론의 연쇄적 과정을 거친다. 기존 시스템은 주로 최신 정보에 집중하거나 최근 업데이트를 우선하는 경향이 있어, 간섭이 잗히는 맥락에서 과거 정보의 provenance를 보존하고 다중 대상 정보를 정확히 집계하는 데 취약하다. 이 문제를 해결하기 위해 MINTEVAL은 4개 도메인과 2가지 태스크를 구성하고, 다양한 메모리 관리 전략의 질적-양적 한계를 분석한다. 연구 결과, 재현 가능한 벤치마크에서도 retrieval 및 memory construction이 주된 병목이며, lookback 및 aggregation 질의에서 더욱 큰 도전이 드러난다. explicit temporal markers의 도입과 메모리 업데이트의 세분화가 간섭으로 인한 성능 저하를 완화하는 데 도움을 준다. 도메인 간 일반화의 한계는 여전히 존재한다.
방법론
단계1: 입력은 네 도메인의 장기 맥락으로 구성되고, 각 업데이트는 인접 업데이트와의 관계를 형성한다. 단계2: 메모리 관리 모듈은 입력을 compact memory로 구성하고, 7개 모델의 retrieval/저장 전략을 통해 context를 구성한다. 단계3: answering agent는 전체 context, retrieved context, 혹은 memory를 입력으로 받아 최종 답을 생성한다. 단계4: 평가 지표로 Exact Match를 사용하며, lookback 및 aggregation 태스크의 성능 저하 원인을 분석한다. 수치 예시: EM 계산은 정답 문자열과 예측 문자열의 일치 여부를 1/0으로 반영하여 평균을 도출한다. 예: y = 정답 문자열, p = 모델 예측 문자열, EM = 1 if y == p else 0; 전체 샘플 평균이 정확도를 구성한다. 단계5: 메모리 시스템의 작동 원리와 차별점은 삽입(Insertion), 수정(Modify/Update), 삭제(Delete) 세 가지 CRUD 연산으로 기술되며, 각 시스템의 연산 분포를 통해 업데이트의 성격을 분석한다.
관련 Figure
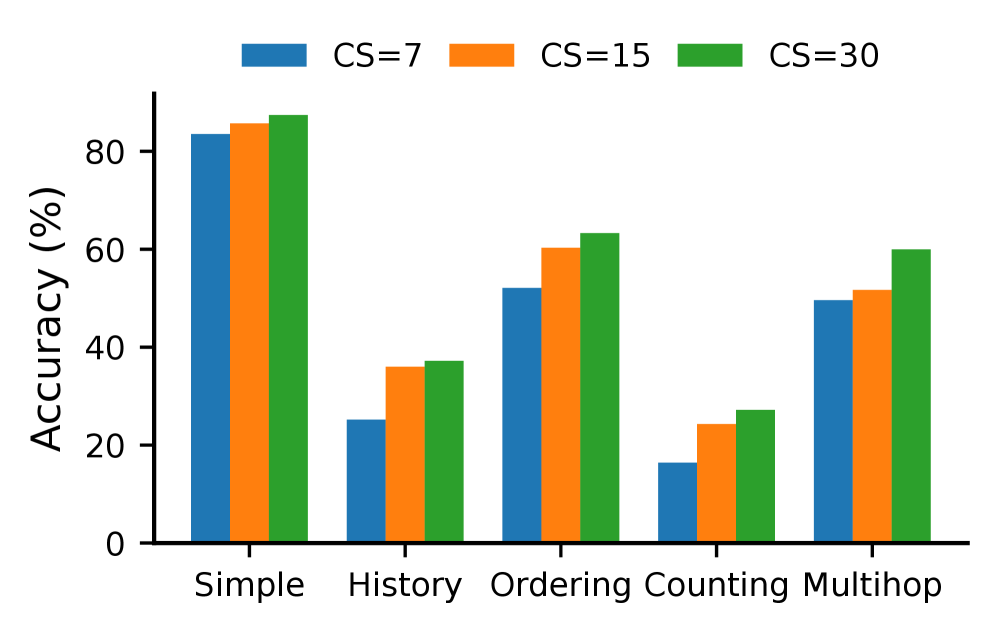
메모리 수정 횟수 감소(Chunk Size 증가)와 성능 간의 상관관계를 보여주며, 단일-타깃 질의에서의 민감도 차이를 확인한다. anchor_key: methodology
Figure 5: Chunk Size(CS)에 따른 MemAgent의 성능 변화
주요 결과
주요 결과는 다음과 같다. MINTEVAL의 평균 정확도는 27.9%이며, 최상위 MemAgent의 평균 정확도는 33.4%이다. Simple 질의의 평균 정확도는 47.5%로 가장 높고 History는 21.0%, Multi-target Aggregation은 26.5%로 하위 수준이다. 도메인별로 MemAgent는 bAbI Simple에서 85.7%를 보였지만 HorizonBench Simple에선 7.5%로 급감하는 등 cross-domain 일반화의 한계를 드러낸다. 또한, RAG와 Memory 기반 방법은 Lookback이 커질수록 성능이 급감하며 Temporal cues를 추가하면 Full Context 및 RAG의 감소폭을 완화한다. Chunk Size를 증가시키면 메모리 업데이트 횟수가 줄어들며 Simple Questions의 영향은 작아진다. Mem-α와 AtomMem은 삽입 편향이 큰 경향을 보였고, SimpleMem은 revision provenance를 보존하는 데 한계가 있어 MINTEVAL의 긴 맥락에서 성능 감소를 보인다.
관련 Figure
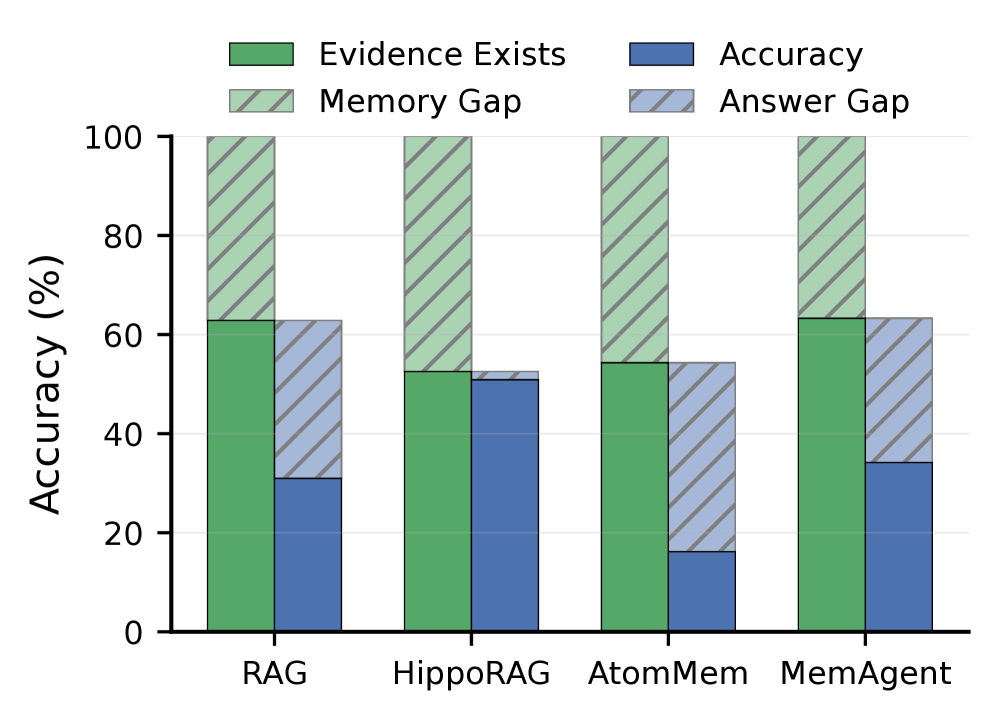
증거 존재 여부와 메모리 구성의 질이 정답에 미치는 영향을 시각화하여, Retrieval/Memory Construction의 병목을 명확히 한다. anchor_key: results
Figure 2: Evidence Exists, Memory Gap, Accuracy 간의 관계를 막대그래프로 보여주는 도식
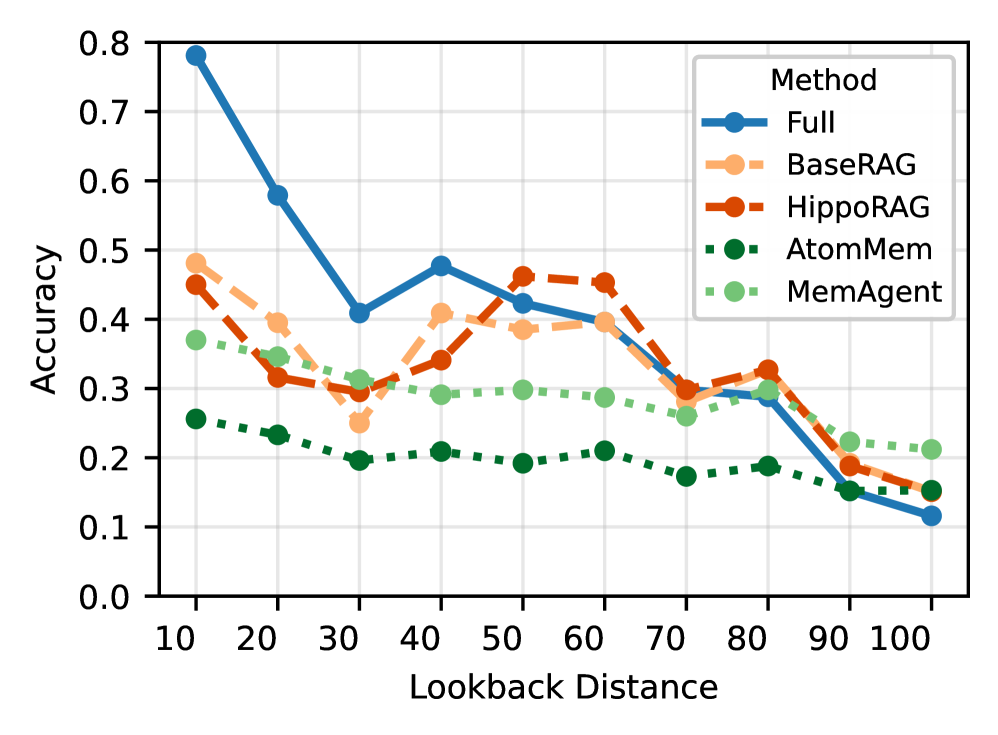
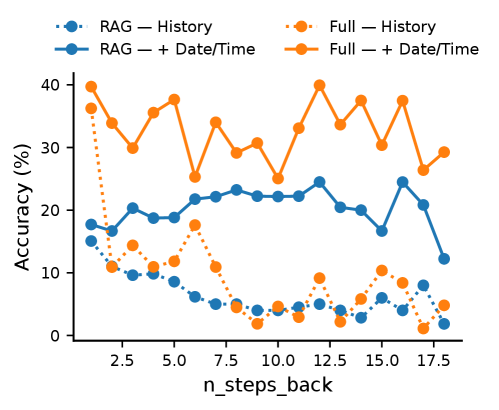
Lookback 거리 증가에 따른 도메인별 성능 저하를 비교하여, 메모리 기반 시스템의 상대적 강인성을 제시한다. anchor_key: results
Figure 3: Lookback Distance에 따른 정확도 변화(Full/RAG/MemAgent 등)
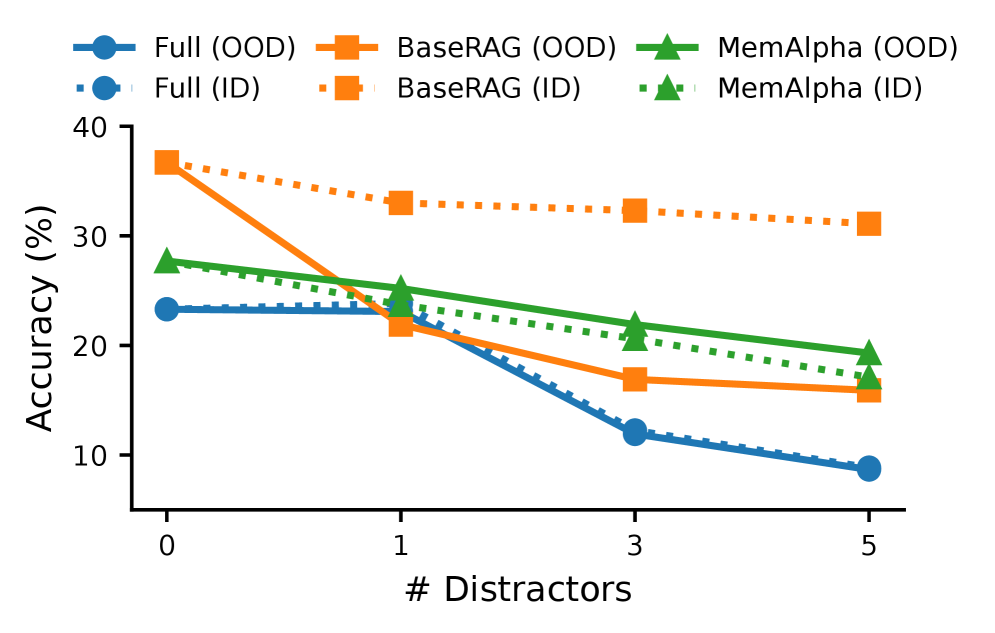
잡음(distractor) 증가에 따른 성능 저하 패턴을 RAG와 Memory 기반 모델 간 차이로 나타내어, 증거 품질의 중요성과 모델 차이를 강조한다. anchor_key: results
Figure 4: Distractor 수 증가에 따른 성능 저하를 도식화한 바 차트
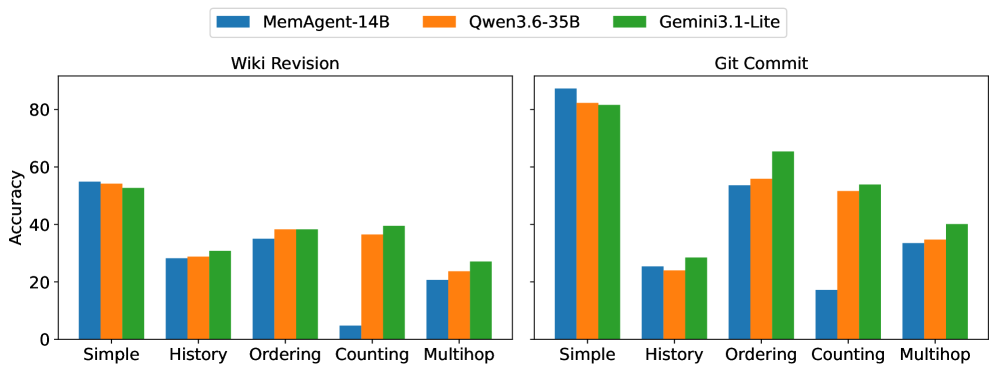
도메인별 시스템 간 성능 차이를 보여주며, specialized answering agents의 한계와 일반 모델의 차이를 시사한다. anchor_key: results
Figure 6: Wiki Revision과 Git Commit에서 MemAgent의 다양한 Answering Agent 조합 비교
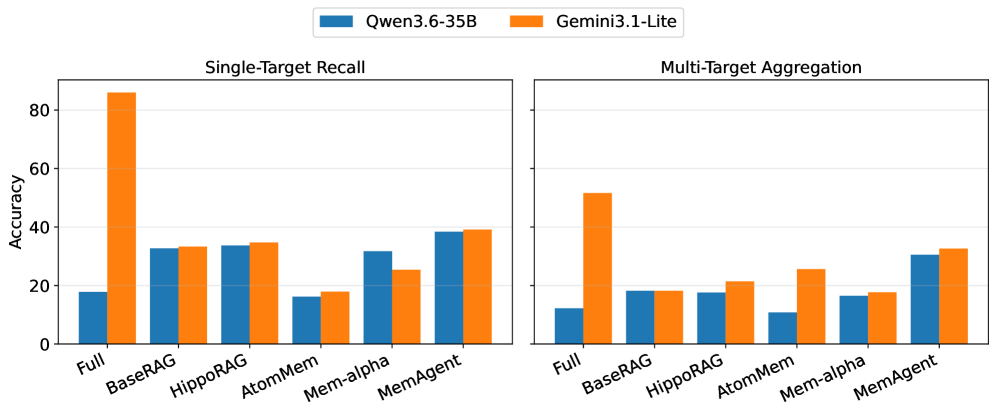
질의 유형별로 서로 다른 에이전트 구성의 효과를 비교해, Full Context에서의 성능 격차와 집계 질의의 어려움을 드러낸다. anchor_key: results
Figure 7: 다양한 answering agents(Qwen/Gemini) 간 Single-Target Recall 및 Multi-Target Aggregation 성능 비교
기술 상세
구성요소1: 아키텍처는 Memory Manager와 Answering Agent로 구성된다. Memory Manager는 긴 맥락을 compact memory로 압축하고, 업데이트를 관리한다. 구분: insertion, update, delete의 CRUD 중 insertion에 편향되는 경향이 관찰된다. 구성요소2: 핵심 수식/개념은 EM(Exact Match)과 LookBack Distance 등으로 측정된다. 구분: lookbackDistance가 증가할수록 Full Context/RAG의 성능 저하가 커진다. 구분: temporal cues를 도입하면 lookback 손실 폭을 줄일 수 있다. 구분: retrieval 선택과 embedding 모델의 차이가 RAG 성능에 영향을 준다. 구분: 학습/추론 파이프라인의 차이가 단일-타깃 대 집계 질의의 성능 차이를 만든다.
실무 활용
다중 업데이트와 간섭이 심한 장기 맥락에서 메모리 관리의 한계와 개선 방향을 실험적으로 진단하는 실무용 벤치마크로 활용된다.
- 메모리 관리 모듈의 평가 및 디버깅
- 장기 의존성 문제를 가진 대화/문서 기반 AI 시스템의 성능 분석
- 도메인 일반화 연구 및 다양한 업데이트 패턴에 대한 내성 평가
- Lookback 질의 및 다중 대상 집계에 대한 추론 로직 개선
코드 공개 여부: 미확인
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.