TL;DR
LLM 기반 코딩 에이전트의 역량은 단일 파일의 코드 생성이 아닌, 프런트/백엔드·데이터베이스·권한·배포 등 다중 컴포넌트의 협업을 필요로 한다. 기존 벤치마크는 실세계 엔터프라이즈 SaaS의 시스템-수준 복잡성이나 다중 기술 스택 간의 상호작용을 충분히 포착하지 못한다. SaaSBench는 30개 태스크, 6개 도메인, 5,370개 검증 노드로 이러한 시스템-수준 도전을 구체적으로 평가하고, 의존성-기반의 하이브리드 평가 파이프라인으로 재현성 있는 측정을 가능하게 한다.
왜 중요한가
LLM 기반 코딩 에이전트의 역량은 단일 파일의 코드 생성이 아닌, 프런트/백엔드·데이터베이스·권한·배포 등 다중 컴포넌트의 협업을 필요로 한다. 기존 벤치마크는 실세계 엔터프라이즈 SaaS의 시스템-수준 복잡성이나 다중 기술 스택 간의 상호작용을 충분히 포착하지 못한다. SaaSBench는 30개 태스크, 6개 도메인, 5,370개 검증 노드로 이러한 시스템-수준 도전을 구체적으로 평가하고, 의존성-기반의 하이브리드 평가 파이프라인으로 재현성 있는 측정을 가능하게 한다.
핵심 기여
SaaSBench 벤치마크 런칭
실세계 SaaS 시스템 개발에서 요구되는 롱호라이즌 계획/크로스-컴포넌트 구현/배포 및 실행을 포함하는 엔드투엔드 엔지니어링 루프를 scratch에서 수행하는 코딩 에이전트를 평가하기 위한 최초의 체계적 벤치마크를 제시한다.
의존성 인식 하이브리드 평가 파라다임
DAG 기반의 노드-단위 검증과 프리재퀴트 의존성 게이팅, 실패 전파 제어, 그리고 이진/가중치/LMM-심판의 3중 점수 체계를 도입해 다부문 시스템의 복잡한 제약을 정확히 반영한다.
실험으로 드러난 에이전트 한계
최강 모델의 최적 점수도 20.68%에 불과하며, 주된 병목은 깊은 비즈니스 로직이 아니라 foundational 시스템 구성 및 통합에 있다. 95%의 실패가 비즈니스 로직에 도달하기 전에 발생한다.
오픈 소스·다양한 스택 평가
8개 언어, 6개 데이터베이스, 13개 Frontend/Backend 프레임워크를 포함한 폭넓은 기술 스택에서 다양한 코딩 에이전트 프레임워크와 모델을 비교 평가한다.
핵심 아이디어 이해하기
출발점: 긴 호라이즌의 소프트웨어 개발은 다수의 파일·모듈·서비스가 얽힌 시스템 수준의 복잡성으로 구성된다. 전통적 코드 작성 벤치마크는 단일 컴포넌트나 간단한 워크플로에 초점을 두어 현실적 제약을 반영하지 못한다. 이로 인해 에이전트의 실질적 가치를 시스템 설계·배포·운영 단계에서 검증하기 어렵다. 초기 아이디어: PRD/KB로부터 요구사항을 확정하고, DAG 기반의 테스트 수립으로 의존성 및 배포 관점의 문제를 계층적으로 검증한다. 핵심 기법: 프론트/백엔드/데이터 모델/접근 제어/배포까지의 여섯 축으로 구성된 5,370개 검증 노드를 통해 각 노드를 primitive 체인으로 구성하고, 선행 의존성에 따라 상호 작용을 재현한다. 평가 루프는 binary/weighted/llm-as-judge의 3가지 채널로 노드를 점수화하고, 최종 점수는 노드별 정규화 합의 평균으로 산출한다. 결과적으로 시스템 구성의 견고성, 계약 일관성, 데이터 흐름, 보안 정책 등이 엔드투엔드 성능의 결정 요인으로 확인된다.
방법론
- 전체 접근 방식: 시장-grounded 도메인에서 seed 저장소를 선정하고 PRD/KB를 작성한 뒤 표준 런타임 환경을 구성한다. 2) 핵심 메커니즘: DAG 테스트 스위트를 노드 단위 프라이미브로 구성하고, 의존성 게이팅으로 실패를 하위 노드로 전이시키지 않도록 관리한다. 3) 학습·구현·가설 검증: LLM 기반 평가 및 루브릭 점수를 이용한 판단, 자동화된 테스트 환경에서 human-in-the-loop 없이 실행하여 재현성을 확보한다. 4) 평가 구성의 차별성: 6개 엔지니어링 축(Deploy/Data/API/Logic/AuthZ/Quality)을 통해 시스템 수준의 제약을 포착하고, 각 태스크의 maxScore를 노드 단위로 합산해 benchmark 수준의 점수를 보정한다.
관련 Figure
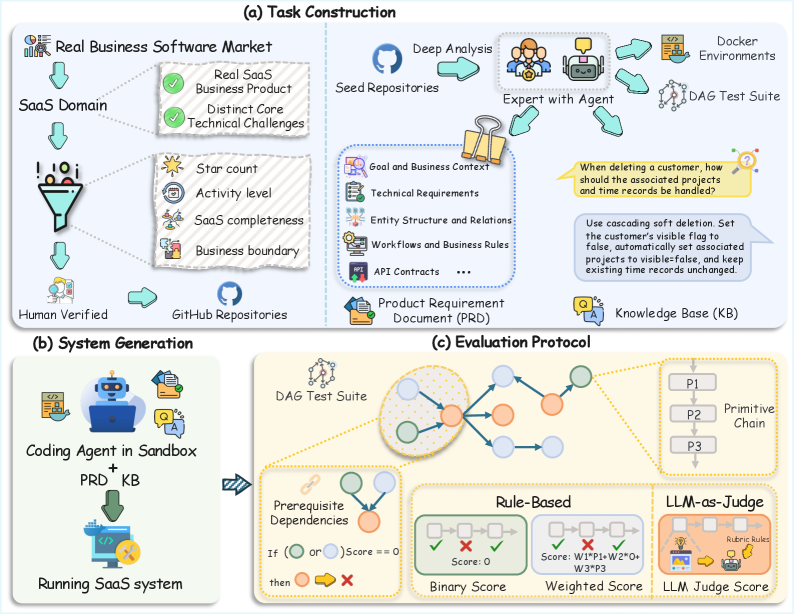
시스템 생성-평가 파이프라인, PRD/KB 입력, Seed Repository, Expert with Agent, DAG Test Suite 등의 구성 요소 간 흐름을 보여준다. 이 그림은 평가 방법론의 핵심인 system-level, dependency-aware 설계의 직관을 제공한다.
SaaSBench 시스템 구성 및 DAG 기반 평가 파이프라인의 개요를 나타낸 다이어그램이다.
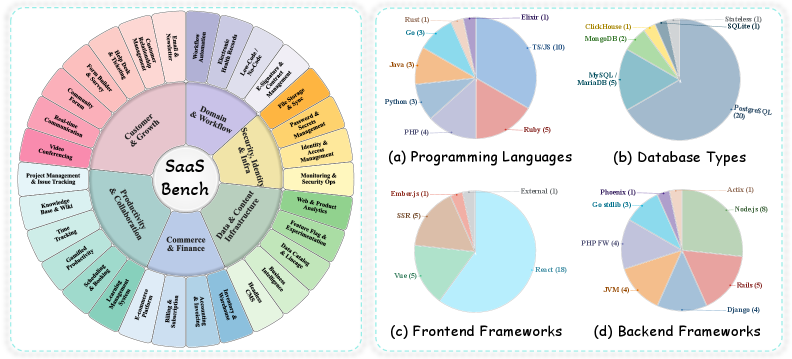
도메인별 분포와 프로그래밍 언어/데이터베이스/프런트-백엔드 프레임워크의 분포를 한눈에 보여주며, 벤치마크의 기술 스택 다양성과 시스템 복잡성의 현실성을 시사한다.
SaaSBench 도메인/프래임워크 분포를 시각화한 원형 차트 및 바 차트들이다.
주요 결과
주요 결과는 다음과 같다. 1) 최상 모델의 Pass@1은 20.68%에 그쳐 End-to-end SaaS 시스템을 scratch에서 완성하는 데 있어 현재 모델의 한계를 보여준다. 평균 성능은 약 11.64% 수준으로 낮다. 2) 도메인별로 SI(DCl/보안-인프라)와 DCI(데이터/콘텐츠 인프라)에서 비교적 높은 성과를 보이나 CF(Commerce & Finance)와 PC(Production & Collaboration)에서 크게 저조하다. 3) 엔지니어링 축별로 Deploy가 상위 점수이나 Quality가 가장 낮아, 아키텍처 품질과 프론트/백엔드의 전반적 완성도가 실제 시스템의 견고성에 큰 영향을 준다. 4) 실패 모드 분석: 63.5%의 유닛은 스택이 안정적으로 실행되지 못했고, 32.1%는 표면적으로는 접근 가능하나 구조적으로 불완전하며, 비즈니스 로직에 이르지 못하는 경우가 3.8%에 불과하다. 5) 프레임워크 간 차이는 동일 모델이라도 도구-인터페이스 관리, 컨텍스트, 피드백 처리 차이로 성능에 큰 차이가 있다.
관련 Figure
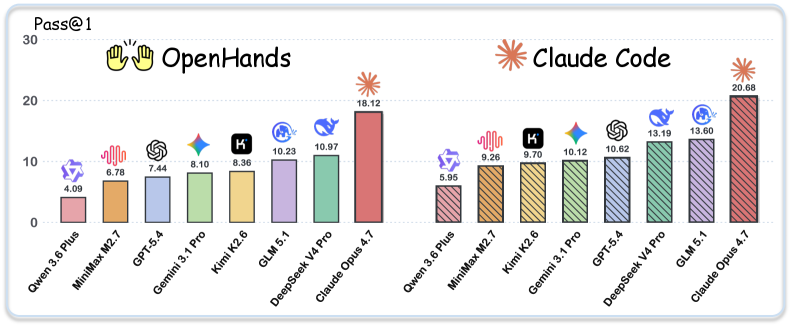
그려진 바 차트는 각 모델의 엔진(프레임워크) 간 성능 차이가 큼을 시각적으로 나타낸다. Claude Opus 4.7이 최상위를 차지했고, 전체 평균은 11-12%대에 머물러 엔드-투-엔드 SaaS 개발의 난이도를 강조한다.
SaaSBench의 Pass@1 리더보드 차트로 OpenHands 계열과 Claude Code 계열의 모델별 성능 비교를 보여준다.
기술 상세
아키텍처: PRD/KB를 통해 요구사항을 Long Context에 반영하고, 컨테이너ized 런타임에서 에이전트가 스스로 시스템을 구성하도록 한다. DAG Test Suite는 노드 v에 대해 P1..P29의 원시 프리미티브를 실행하고, 각 노드는 binary/weighted/llm-as-judge의 점수 체계를 적용한다. 프리퀴짓 의존성(gating)으로 선행 노드가 PASSED일 때만 후행 노드가 실행되며, SKIPPED_DEPENDENCY 상태가 발생하면 해당 노드는 점수 0으로 간주한다. 평가 백본은 Deploy/Data/API/Logic/AuthZ/Quality의 여섯 축으로 매핑되며, 백본별 합산은 최대 점수 비율에 따라 산정된다. 분석은 30개 태스크의 평균 St를 0-100 스케일로 정규화한 벤치마크 점수 S로 보고한다. 추가로 289개의 세부 카테고리를 여섯 백본으로 매핑하는 결정적 매핑 알고리즘이 제시되며, 백본별 노드 분포는 Deploy(5.4%), Data(15.9%), API(22.6%), Logic(22.0%), AuthZ(19.1%), Quality(15.1%)로 구성된다.
실무 활용
SaaSBench는 엔터프라이즈 SaaS 개발의 시스템 수준 코딩 에이전트를 평가하는 표준화된 벤치마크로서, 연구자와 실무자가 에이전트의 end-to-end 능력을 비교하고 개선 방향을 도출하는 데 활용 가능하다.
- 에이전트 프레임워크/모델 비교 및 선택
- 엔터프라이즈 SaaS 시스템의 취약점 진단
- 장기-호라이즌 코드 생성 파이프라인의 안정성 평가
- 시스템 설계-구현-배포의 자동화 워크플로우 연구
- 다양한 기술 스택에서의 협력형 에이전트 연구
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.