TL;DR
대형 Vision-Language 모델(LVLM)은 의료 분야에서 활용도가 높아졌지만 입력 영상의 시각적 증거에 대한 Grounding이 불충분하여 임상 신뢰에 위험이 있다. 기존 Attribution 방법은 내부 추론과 실제 근거가 일치하는지 확인하기 어렵고 Ground-Truth가 제한적이다. 이 연구는 Chest X-ray(CXR) 데이터에 대해 Ground-truth Attribution의 인과적 타당성을 검증하는 MedGround-Bench를 제시하고, 지역적 임상 개념에 기반한 MedFocus를 통해 시각적 근거를 공간-개념-토큰 차원에서 인과적으로 측정한다. 실험은 11개 Attribution 방법, 6개 LVLM, 3개 CXR 데이터셋, 2가지 출력 모드에서 수행되며, MedGround-Bench를 통해 기존 방법의 한계를 확인하고 MedFocus의 향상을 보여준다.
왜 중요한가
대형 Vision-Language 모델(LVLM)은 의료 분야에서 활용도가 높아졌지만 입력 영상의 시각적 증거에 대한 Grounding이 불충분하여 임상 신뢰에 위험이 있다. 기존 Attribution 방법은 내부 추론과 실제 근거가 일치하는지 확인하기 어렵고 Ground-Truth가 제한적이다. 이 연구는 Chest X-ray(CXR) 데이터에 대해 Ground-truth Attribution의 인과적 타당성을 검증하는 MedGround-Bench를 제시하고, 지역적 임상 개념에 기반한 MedFocus를 통해 시각적 근거를 공간-개념-토큰 차원에서 인과적으로 측정한다. 실험은 11개 Attribution 방법, 6개 LVLM, 3개 CXR 데이터셋, 2가지 출력 모드에서 수행되며, MedGround-Bench를 통해 기존 방법의 한계를 확인하고 MedFocus의 향상을 보여준다.
핵심 기여
MedGround-Bench 구축 및 인과적 필터링
세 가지 공개 CXR 데이터셋(ImaGenome, VinDR-CXR, PadChest-GR)의 전문 주석을 바탕으로 binary VQA를 구성하고, Ground-Truth 박스가 모델 예측에 인과적으로 기여하는지 3단계 필터링으로 확인한다. 최종 MedGround-Bench은 1,880개의 Direct 샘플과 2,060개의 Reasoning 샘플로 구성되며 총 3,940샘플을 포함한다.
MedFocus: 의학 개념 기반 인과적 귀속
11개의 임상 해부학적 개념(예: cardiac silhouette, left lung, right lung 등)을 Unbalanced Optimal Transport(UOT)으로 매핑하여 Reference Normal CXR에서 Target 이미지로 전달된 영역을 구하고 MedSAM으로 마스크를 정제한다. 이후 각 개념의 개입으로 출력의 변화를 측정해 가장 영향력 있는 개념 c*를 도출하고, 공간적/개념적/토큰 단위의 Attribution을 제공한다.
기존 Attribution 방법의 한계 확인
11개 방법(주의: Attention-기반, Gradient-기반, Prompting-기반, Perturbation-기반)의 예측이 Ground-Truth 근거를 faithfully 찾지 못함을 일관되게 보였다. MedFocus는 IoU/F1에서 전반적으로 우수한 성능을 보이며, 이유 모드에서도 강건하게 작동한다.
Ablation 및 효율성 분석
두 단계 분할(localization) 및 MedSAM 정제가 Attribution 품질을 향상시키며, Bounding box Interventions가 Segmentation Mask보다 우수한 인과 신호를 제공한다. MedFocus의 추론 시간은 약 1.65초로, 경사/어텐션 기반 방법보다 느리지만 RISE/Occlusion 같은 대규모 perturbation 대비 효율적이다.
의료 LVLM용 벤치마크 공개 및 실무 시사점
MedGround-Bench 및 MedFocus 코드는 공개되며, 임상 신뢰성과 환자 안전성을 높이는 데 기여한다. 임상적 해부학적 개념 기반의 귀속은 전문가에게 직접 해석 가능한 설명을 제공한다.
핵심 아이디어 이해하기
출발점: LVLM은 다중 모달 데이터를 다루지만, 예측에 사용된 시각적 근거를 사람처럼 명확히 식별하기 어렵다. 기존 시각적 귀속 기법은 픽셀 단위나 내부 표현에 의존하는 경우가 많고, Ground-Truth가 불완전해 신뢰도 평가가 불가능했다. 의학 영상에서 근거의 신뢰성은 임상 의사결정의 안전성과 직결된다.
방법론
2-단계 프레임워크를 제시한다. 첫째, Ground-truth 근거를 포함하는 VQA 샘플을 활용해 MedGround-Bench를 구축한다. 둘째, MedFocus를 통해 의학 해부학적 개념을 매핑하고, 각 개념에 대해 카오스(인과적) 개입을 수행해 모델 출력의 변화를 측정한다. 변화를 Δc로 정의하고, 가장 큰 Δc를 보인 개념 c*를spatial attribution, concept-level 설명, token-level attribution으로 제시한다.
관련 Figure
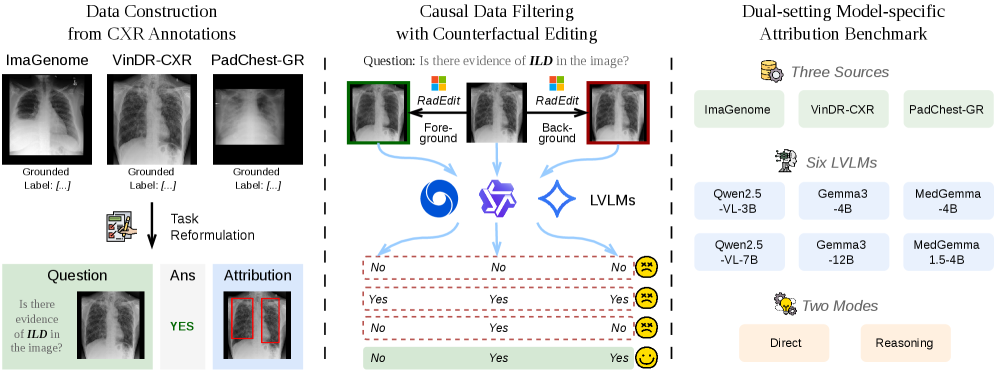
데이터 구성 과정과 Ground-truth 박스의 시각적 매핑이 MedGround-Bench의 기반을 형성한다.
MedGround-Bench 데이터 구성 및 Ground-truth 박스 시각화
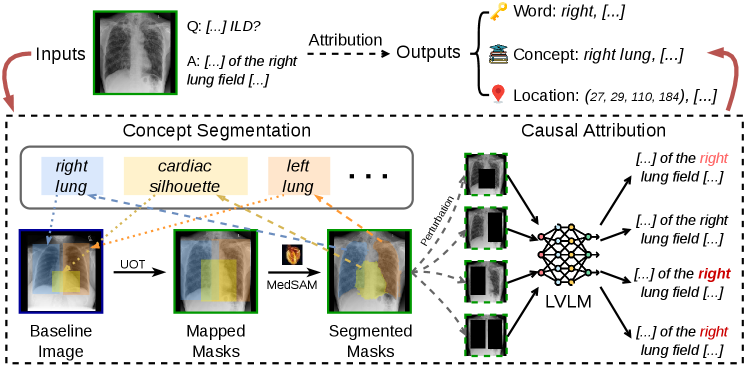
UOT 매핑과 MedSAM 정제가 개념 마스크를 형성하는 핵심 흐름을 보여준다.
Concept Segmentation 및 UOT 매핑 흐름
주요 결과
MedGround-Bench Direct 모드에서 MedFocus의 IoU/F1는 ImaGenome에서 54.24/67.54로 baselines를 능가한다(다른 데이터셋도 개선). PadChest-GR의 IoU는 32.77, VinDR-CXR은 14.81로 나타난다. Reasoning 모드에서도 MedFocus의 IoU는 ImaGenome에서 52.95로 강건하게 높은 편이다. Ablation에서 UOT+MedSAM 조합이 가장 우수한 위치를 차지하며, Bounding box 인터벤션이 세그멘테이션 마스크보다 우수한 인과 신호를 제공한다. MedFocus의 평균 추론 시간은 약 1.65초이다.
관련 Figure
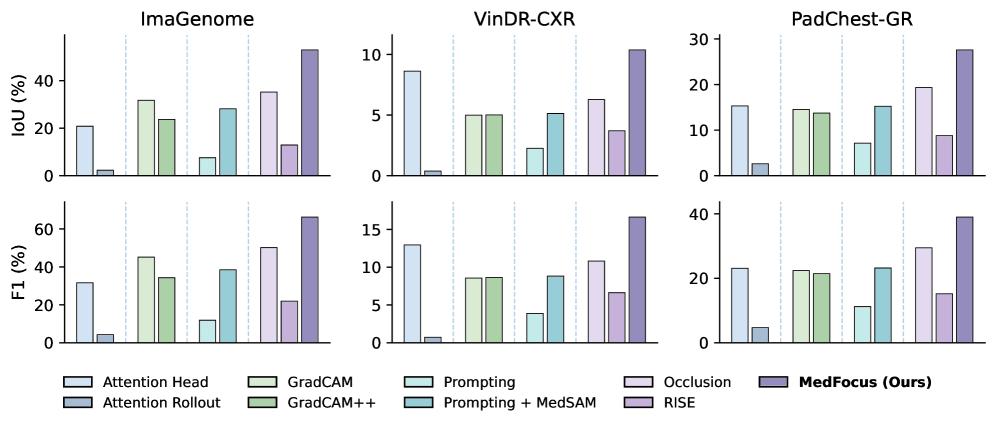
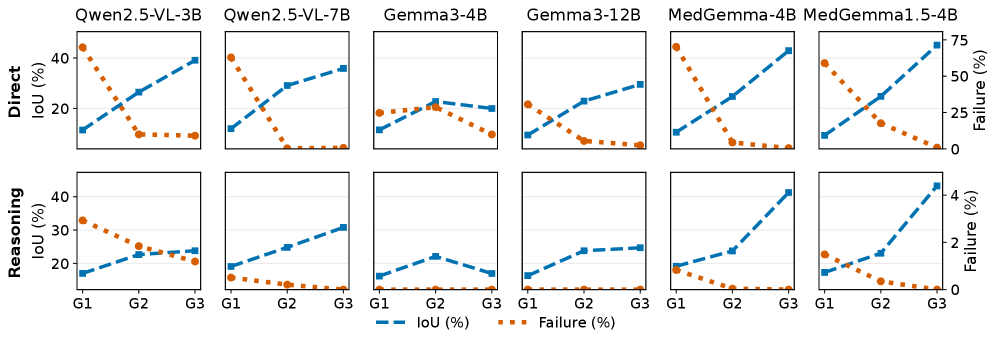
MedFocus의 상대적 성능 개선을 직관적으로 확인시켜 준다.
벤치마크 각 데이터셋의 IoU/F1 비교(Direct)
multi-step reasoning에서도 MedFocus의 인과 귀속이 유지됨을 시사한다.
Reasoning 모드에서의 Attribution 비교
토큰 수준에서 어떤 단어가 어떤 개념의 개입에 민감한지 시각화한다.
Token-level 개념 귀속 예시
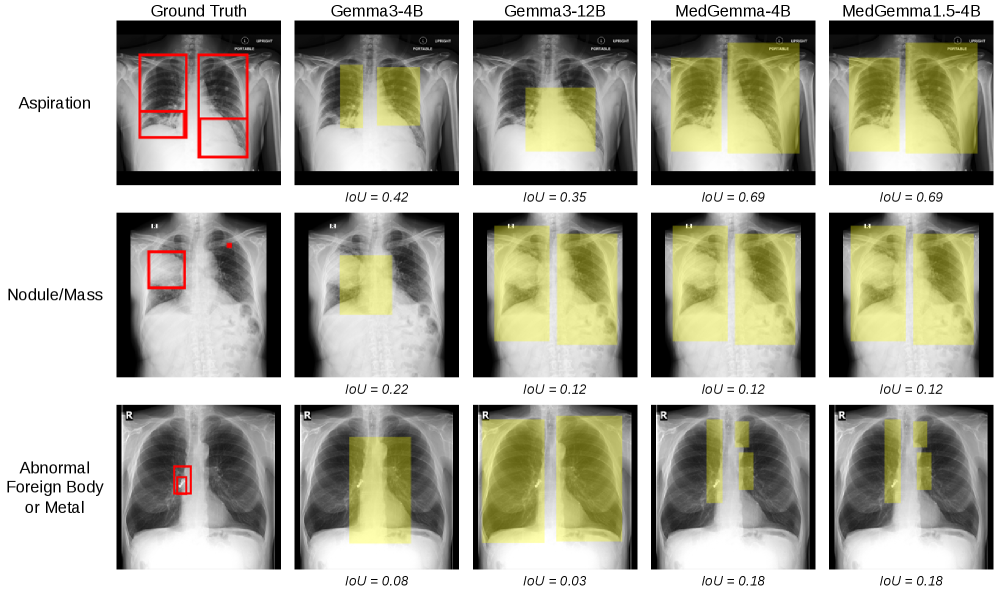
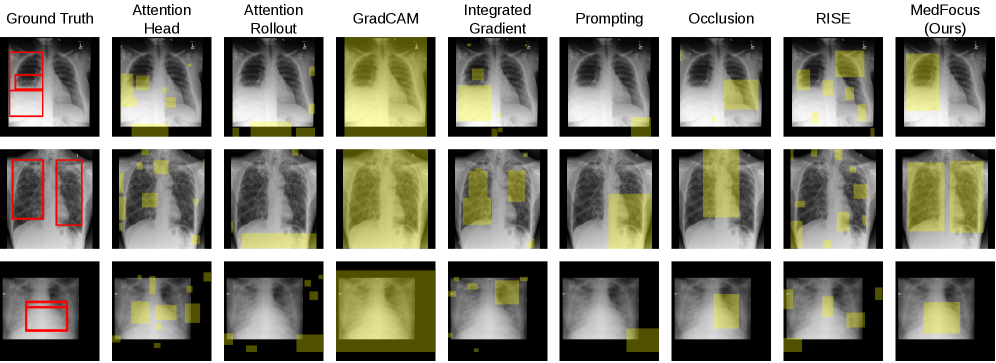
구체 사례에서 MedFocus의 공간 귀속이 ground-truth 근거와 얼마나 일치하는지 보여준다.
의료 케이스별 MedFocus 공간 귀속 예시(Aspiration, Nodule/Mass 등)
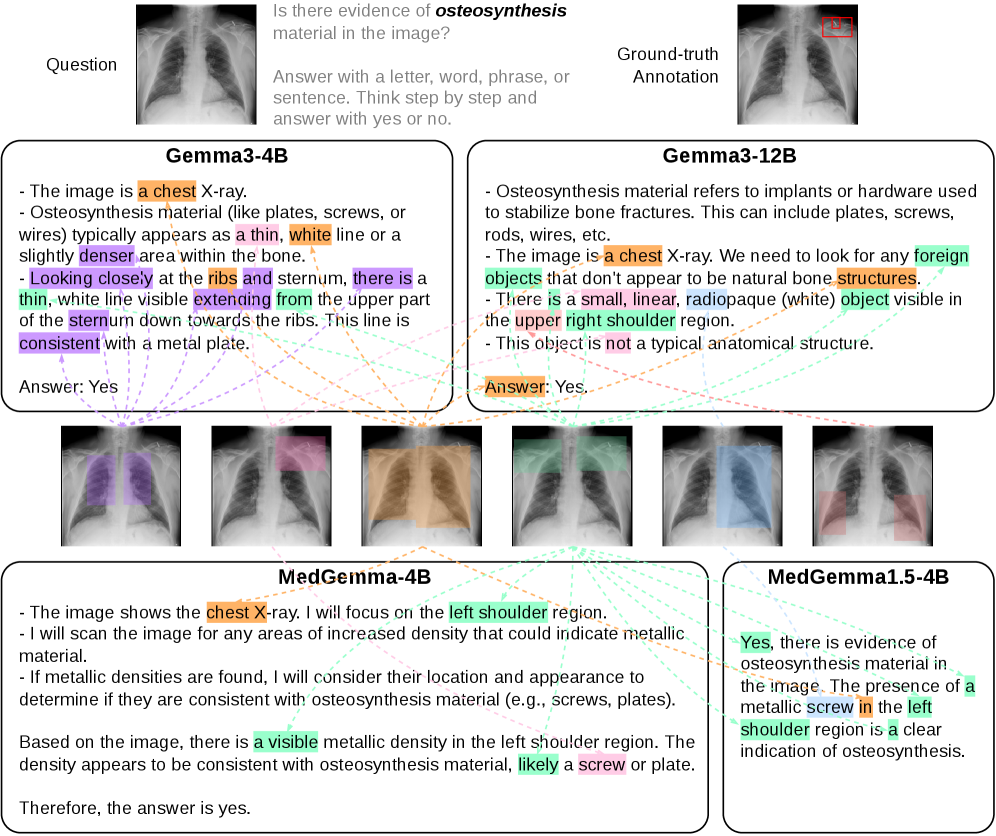
금속 재료 등 특이한 상황에서도 MedFocus가 근거를 근접하게 포착하는지 시연한다.
Osteosynthesis 재료 사례의 토큰-수준 귀속
기술 상세
아키텍처: MedGround-Bench는 ImaGenome/VinDR-CXR/PadChest-GR의 Ground-truth를 VQA로 재구성하고, Correctness Filtering, Foreground Counterfactual Editing, Background Counterfactual Editing의 3단계 카우설 필터링으로 Ground-truth Attribution의 인과성을 검증한다. MedFocus는 11개 해부학 개념의 벡터화를 위해 Unbalanced OT를 이용해 reference-normal 이미지를 target 이미지로 매핑하고, MedSAM으로 마스크를 정제한다. 개입은 개념 마스크의 경계 상자(Bounding box)를 0으로 마스킹하여 x˜c를 생성하고, 로그확률의 누적 감소 Δc를 계산해 출력을 변화시키며, 가장 큰 Δc를 보인 c*를 Attribution으로 선택한다. rc = exp(−Δc)로 개념의 기여를 판단해 어떤 개념도 기여하지 않는 경우 전체 이미지를 attribution으로 사용한다.
한계점
한계로는 CXR에 특화되어 있어 다른 영상 모달리티에의 확장은 별도 도메인 편집 모델과 데이터가 필요하다는 점이다. 또한 평가 데이터는 이진 VQA 구성이며, 일반적인 진단 보고서나 다단계 추론과 같은 확장에는 추가 검증이 필요하다.
실무 활용
의료 LVLM의 시각적 귀속 신뢰성을 평가하고 개선하는 실용적 프레임워크를 제공한다.
- 의료 이미지 진단 보조의 근거 해석 검증
- 의료 LVLM의 학술 연구에서 Attribution 프레임워크 표준화
- 임상 현장에서 LVLM 출력에 대한 시각적 근거의 신뢰성 평가
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.