TL;DR
리소스 제약 환경에서 MoE-dLLM의 대용량 파라미터를 효율적으로 운용하려면 GPU-CPU 간의 I/O 비용과 CPU 계산 병목을 줄여야 한다. TIDE는 expert activations의 시간적 안정성을 이용해 interval-based refresh를 도입하고, 모델 정확도에 영향을 주지 않으면서 추론 속도를 높인다. LLaDA2.0-mini와 LLaDA2.0-flash에서 최대 1.4×, 1.5×의 처리량 개선이 보고된다.
왜 중요한가
리소스 제약 환경에서 MoE-dLLM의 대용량 파라미터를 효율적으로 운용하려면 GPU-CPU 간의 I/O 비용과 CPU 계산 병목을 줄여야 한다. TIDE는 expert activations의 시간적 안정성을 이용해 interval-based refresh를 도입하고, 모델 정확도에 영향을 주지 않으면서 추론 속도를 높인다. LLaDA2.0-mini와 LLaDA2.0-flash에서 최대 1.4×, 1.5×의 처리량 개선이 보고된다.
핵심 기여
학습 없이 MoE-dLLM 추론 가속
MoE-dLLM에 대한 학습 없이도 I/O 비용과 CPU 계산을 절감하는 손실 없는 추론 가속을 제시한다. 이는 모델 가중치를 바꾸지 않고 expert 배치를 재구성하는 방식으로 수행된다.
Interval-based expert refresh 도입
단계 간 expert activation의 시간적 국소성(근접 단계에서의 유사성)을 활용해 interval τ 간격으로 GPU-메모리의 expert를 재정의한다. 재배치를 줄여 GPU-CPU 간 I/O 오버헤드를 감소시킨다.
최적의 refresh 간격 τ를 위한 MP 기반 최적화
LatI/O(τ)와 LatCPU(τ)를 분석 모델링하고 상호 작용을 고려한 제약식 최적화 문제로 λ(τ)를 해결하여 최적의 τ를 offline에서 찾는다.
비동기 토큰 운영 및 재활용 정책
토큰 라우팅과 연산을 비동기로 수행하고, hit 카운터 기반으로 상위-expert를 재배치해 skipped steps에서도 GPU 활용도를 유지한다.
실험적 검증 및 실용성
LLaDA2.0-mini와 LLaDA2.0-flash에서 Fiddler 및 Mixtral-Offload 대비 일관된 속도 증가를 보이며, 메모리 제약 하에서도 탁월한 성능을 보인다.
핵심 아이디어 이해하기
단계별 디노이징으로 구성된 MoE-dLLM의 각 denoising step은 활성화되는 전문가 집합이 시간에 따라 큰 폭으로 달라지지 않는다. 즉, 인접한 denoising step 간 전문가 할당은 높은 유사성을 가지며, 5단계 수준에서도 cosine 유사도가 대체로 0.95 이상이다. 이 시간적 안정성을 활용해 interval τ 간격으로 GPU-메모리에 상주하는 전문가 세트를 재생성하고, skipped steps에서는 현 배치를 재사용한다. 이로써 GPU-메모리의 활용도와 토큰 처리율을 유지하면서 지속적인 전문가 교체에 따른 I/O 오버헤드를 줄일 수 있다. 최적의 τ는 LatI/O(τ)와 LatCPU(τ)의 합을 최소화하도록 MP를 통해 오프라인으로 결정한다. 비동기 토큰 라우팅과 hit 기반 재배치를 도입해 CPU와 GPU 간 병렬화를 극대화한다.
관련 Figure
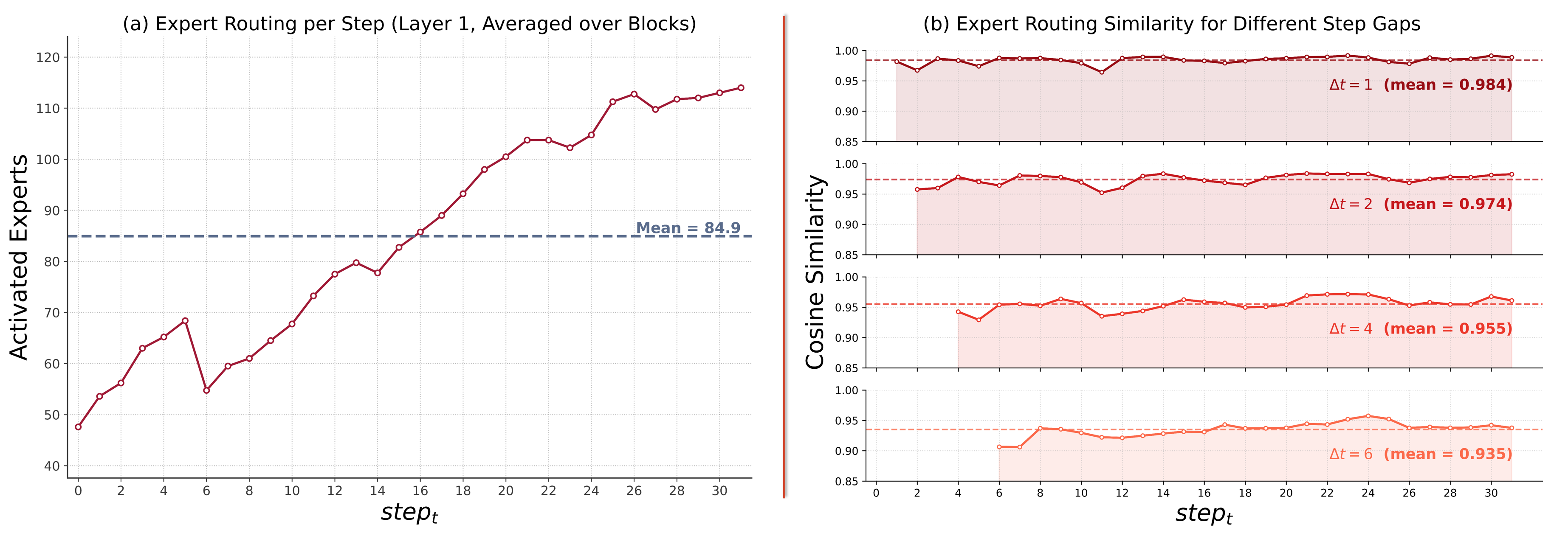
단계별 활성화 패턴은 시간에 따라 비슷하게 유지되며, 이로 인해 interval 기반 재배치의 효과가 뚜렷해진다. 각 단계의 cosine similarity와 활성화된 전문가 수의 변화가 함께 제시된다.
Figure 2: Block 크기 32에서의 Expert Activation 패턴과 단계 간 유사성
방법론
- 문제 정의: MoE 모델은 L개의 sparse FFN 계층과 총 E개의 전문가를 갖고, 한 토큰당 활성화되는 k명의 전문가가 존재한다. GPU 메모리에는 B명의 GPU experts가 상주하고, 나머지는 host 메모리에 있다. LatFFN은 LatGPU(KGPU)와 LatCPU(KCPU)의 최대값 혹은 합으로 표현된다. K와 B의 관계에 따라 LatFFN이 달라진다.
- 관찰: MoE-dLLM에서 단계 간 expert activation은 시간적으로 안정적이며, 인접 단계 간의 유사도가 높다(dt ≈ 상수). 이로 인해 특정 Window 내에서 expert 배치를 재사용할 수 있다.
- TIDE 설계: decoding을 τ 구간으로 나누어 refresh steps에서 GPU-resident expert를 top-B로 재배치하고, skipped steps에서는 현재 배치를 유지한다. 최적의 τ를 MP로 결정하고 offline으로 해결한다. Algorithm 1은 GPU/CPU expert 간 비동기 마이그레이션과 토큰 라우팅 흐름을 정의한다.
- 최적화 문제: LatI/O(τ) ≈ CI/O · B · T/τ · [1 − (1 − d)τ], LatCPU(τ) ≈ CCU · T · B · f(τ) 이고, 총 Lat(τ) = LatI/O(τ) + LatCPU(τ)이다. 이를 최소화하는 τ를 구한다(식 7).
- 구현: CPU 속도·I/O 대역폭 프로파일링으로 상수 CI/O, CCU를 추정하고 Greedy 탐색으로 최적 τ를 구한다. 모든 내용은 inference 과정에서 오버헤드 없이 offline으로 수행된다.
- 실행 정책: 토큰이 미스일 경우 비동기로 CPU에서 처리하도록 하고, 결과를 동기화한다. Lossless하게 동작하며 출력은 기존 GPU-only 실행과 동일하다.
관련 Figure

스케줄링 전략의 핵심 아이디어를 시각화한다. (a)에서 인접 단계 사이의 라우팅 유사성은 높고, (b)에서 refresh와 skip 단계의 동작 흐름이 제시되며, (c)에서 제안된 방법의 처리량 이점을 비교한다.
Figure 1의 (a) Expert Routing Similarity Heatmap, (b) Method Overview, (c) LLaDA2.0 모델의 처리량 비교
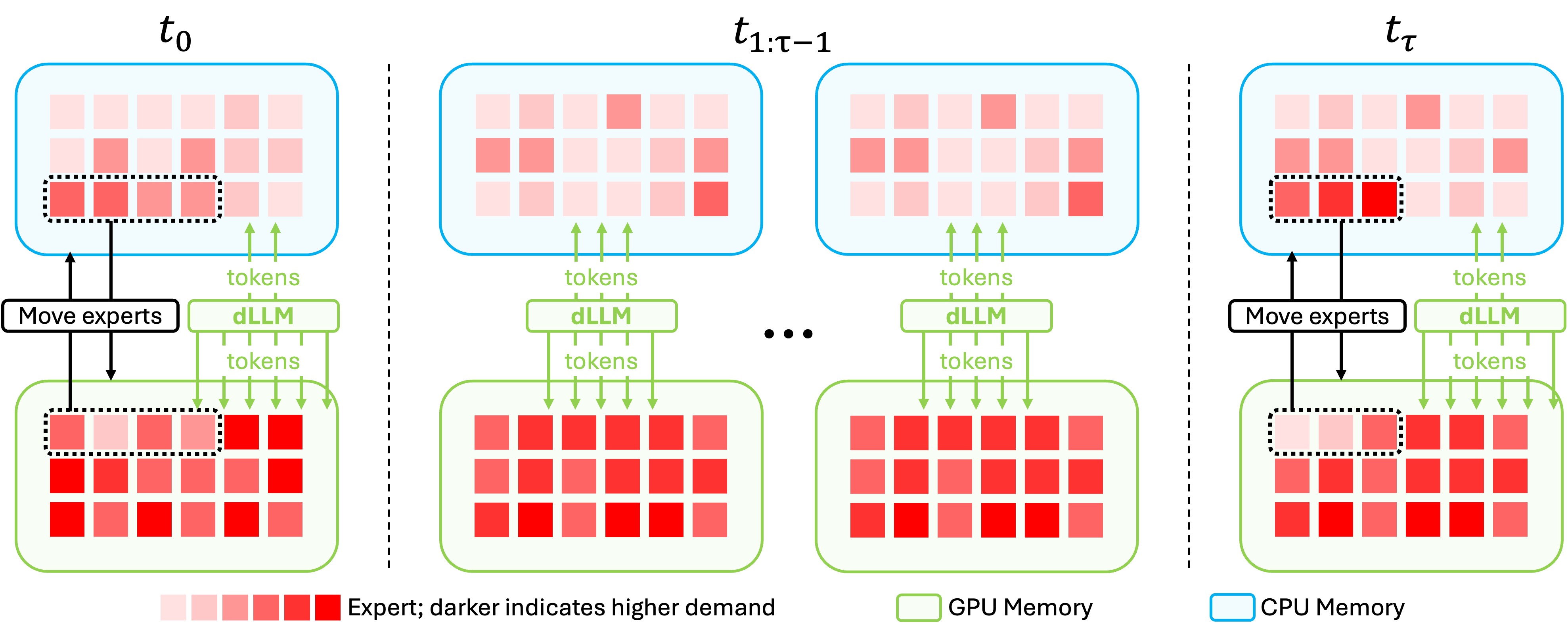
디자인의 핵심 구성요소를 보여준다. refresh 단계에서 GPU-resident expert를 재배치하고, skipped 단계에서 재배치를 하지 않는 하이브리드 흐름으로 고성능 GPU-주도 계산을 유지한다.
Figure 3: TIDE 설계 개요(Refresh vs Skipped 단계, 토큰 라우팅 흐름)
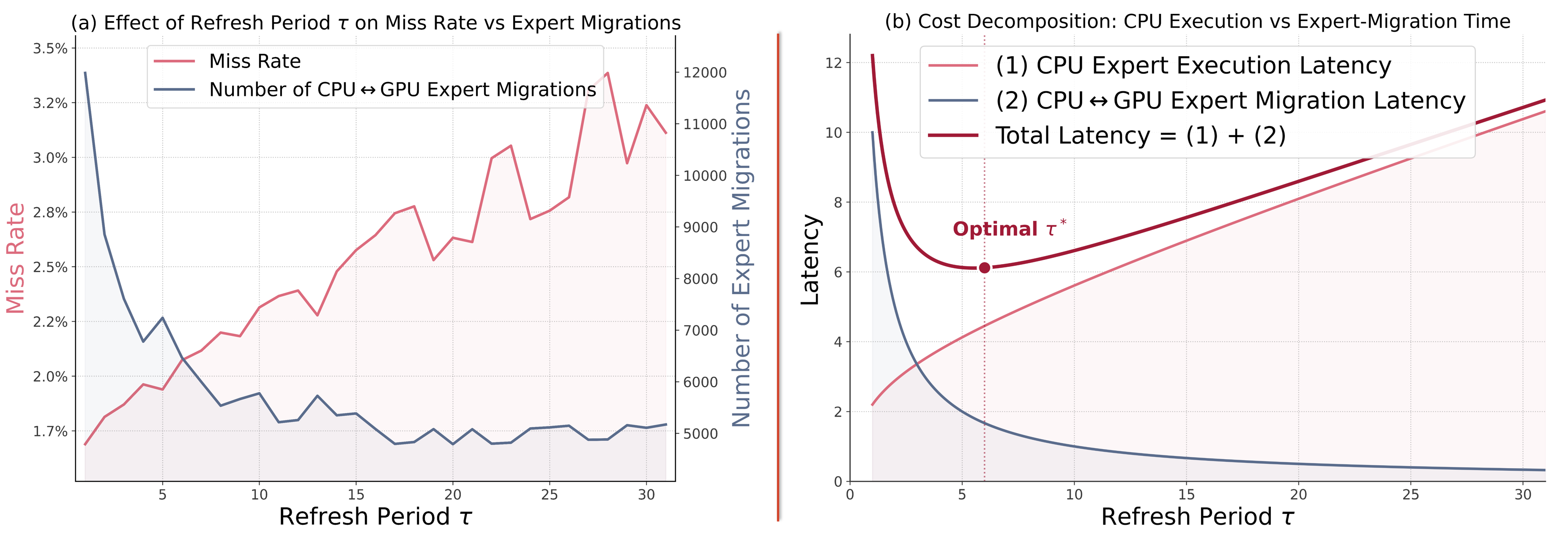
τ 증가에 따른 GPU-미스 레이트와 마이그레이션 수의 변화, LatCPU/LAT I/O 간의 상호작용이 그래프로 제시된다. 최적 τ는 Lat(total)을 최소화하는 지점으로 식(7)을 통해 도출된다.
Figure 4: Refresh Interval τ의 영향(미스 비율, 마이그레이션 수, 총 지연의 트레이드오프)
주요 결과
- 메인 벤치마크: Table 1에 따라 LLaDA2.0-mini에서 256-64-10GB 구성은 Fiddler 1.81, Mixtral-Offload 1.69, TIDE 2.11 token/s를 달성. 128-18GB 구성은 1.74, 1.76, 2.36; 1024-64-10GB 구성은 1.79, 1.45, 1.89; 128-18GB 구성은 1.80, 1.91, 2.44. LLaDA2.0-flash에선 256-32-30GB에서 0.95, 1.01, 1.25; 64-55GB에서 1.14, 1.35, 1.73; 1024-32-30GB에서 0.89, 1.01, 1.24; 64-55GB에서 1.05, 1.16, 1.45가 관측되었다.
- τ에 따른 Ablation: Table 2는 τ=1, Random τ, Optimal τ에 대한 각 조합별 처리량을 제시한다. LLaDA2.0-mini의 (32,64)에서 1.79(τ=1), 1.62(Random), 1.89(Optimal); (32,128)에서 1.91, 2.14, 2.44; (64,64)에서 1.71, 1.65, 1.90; (64,128)에서 2.14, 2.24, 2.40이다. LLaDA2.0-flash의 경우 (32,32)에서 1.01, 0.85, 1.24; (64,32)에서 1.16, 1.23, 1.45; (64,64)에서 1.12, 0.95, 1.32; (64,64)에서 1.27, 1.32, 1.49이다.
- 추가 분석: Figures 4–5에서 τ 증가에 따른 Miss Rate 증가와 CPU-GPU 마이그레이션 비용의 상호 작용을 시각화한다. 최적 τ는 3~6 구간에서 미세 조정되며, τ가 커질수록 I/O 비용의 1/τ 감소 효과가 CPU 비용 증가를 상쇄한다. 실험적으로 τ*를 오프라인으로 결정하는 MP 접근법이 Random τ에 비해 최대 1.4×의 속도up를 제공한다. block size 및 GPU 예산에 따라 TIDE의 이득은 일관되게 유지된다.
관련 Figure
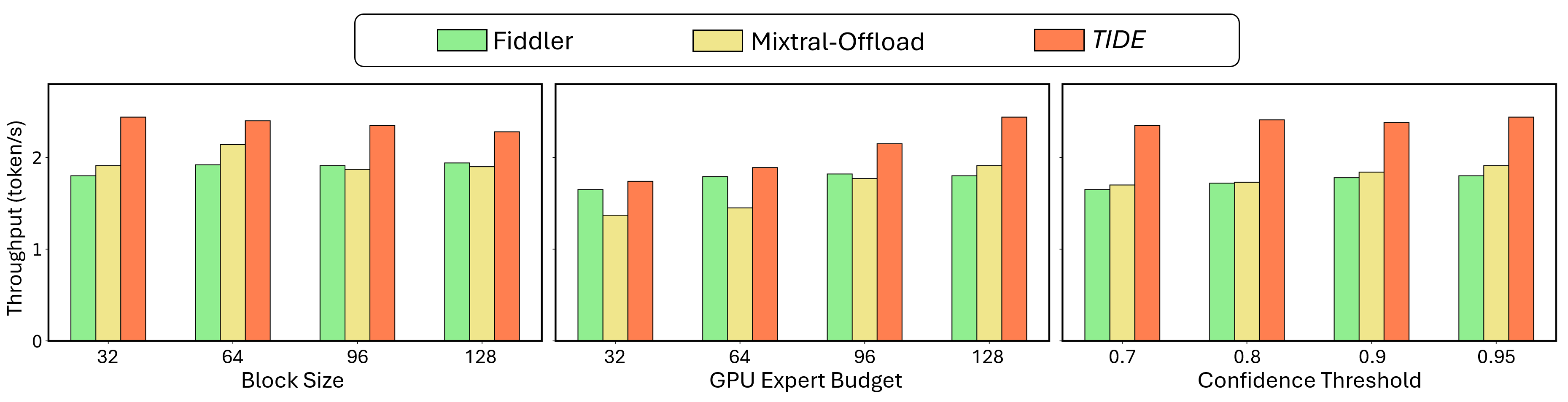
테이블 1과 2의 흐름을 보완하는 추가 시각으로, Baseline과 비교한 TIDE의 throughput 향상을 다수 설정에서 확인할 수 있다.
Figure: Throughput 분석 및 비교(다양한 설정에서의 비교 차트)
한계점
- Expert Activation 패턴 분석은 블록 내부 수준에 국한된다. 블록 단위 이상의 전역적 유사성 분석은 아직 미수집이다. 2) 평가가 한정된 하드웨어 플랫폼에서 수행되었다. AMD GPU와 ARM CPU 등 다양한 아키텍처에서의 일반화는 필요하다. 3) 현재 설정은 단일 GPU-CPU 시스템에 국한되며 다중 GPU/다중 노드 확장은 향후 연구과제다.
실무 활용
MoE-dLLM 추론을 리소스 제약 환경에서 수행할 때 I/O 및 CPU 병목을 줄이고, 손실 없이 throughput를 높이는 방법이다.
- edge 디바이스에서의 MoE 기반 채팅/대화 시스템의 응답 속도 향상
- 모바일/임베디드 환경에서 LLaDA2.0 계열 모델의 서비스 품질 향상
- 단일 GPU-CPU 서버에서 대용량 MoE-dLLM을 더 높은 실시간 처리량으로 운영
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.