이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
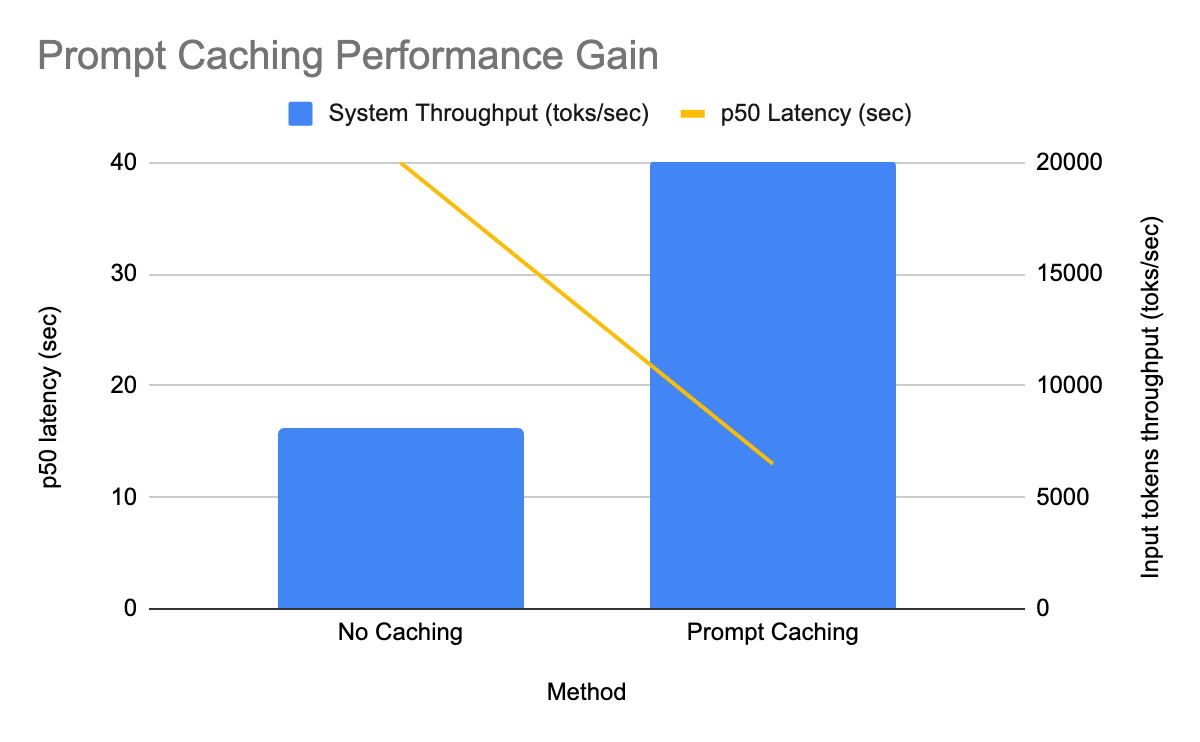
Databricks가 오픈소스 모델을 대상으로 프롬프트 캐싱 기능을 지원한다. 이 기능은 반복되는 시스템 프롬프트나 지시사항을 캐시에 저장하여 매번 재계산하는 비용을 제거한다. GPT-OSS 모델 적용 결과, 입력 토큰 처리량이 2.5배 증가하고 P50 지연 시간이 3배 감소했다. 캐시는 휘발성 메모리에만 상주하며 자동 적용되므로 별도의 사용자 설정이 필요 없다.
대상 독자
프로덕션 환경에서 오픈소스 LLM을 운영하는 개발자 및 엔지니어
의미 / 영향
이 기술은 LLM 추론 비용을 획기적으로 낮춰 소규모 스타트업도 프로덕션에 고성능 오픈소스 모델을 도입할 수 있게 한다. 특히 RAG 시스템이나 긴 컨텍스트를 반복 사용하는 에이전트 서비스에서 즉각적인 비용 절감과 성능 향상 효과를 제공한다.
섹션별 상세
LLM 추론 시 반복되는 프롬프트 접두사를 매번 처리하는 것은 컴퓨팅 자원 낭비와 지연의 원인이다.
프롬프트 캐싱은 동일한 접두사를 해시 키로 저장하고 이후 요청에서 캐시를 조회하여 토큰 계산 과정을 생략한다.
Databricks는 GPT-OSS, Gemma 3, Llama 3.1/3.3 등 주요 오픈소스 모델에 이 기능을 자동 적용했다.
실제 프로덕션 환경에서 30%의 캐시 적중률만으로도 처리량 2.5배 증가와 지연 시간 3배 감소라는 성능 개선을 확인했다.
보안을 위해 캐시는 휘발성 메모리에만 격리 저장되며 영구 저장되지 않는다.
실무 Takeaway
- 반복적인 시스템 프롬프트를 사용하는 RAG나 챗봇 서비스에서 프롬프트 캐싱을 통해 추론 비용과 지연 시간을 획기적으로 줄일 수 있다.
- 별도의 설정 없이 자동 적용되므로 기존 추론 파이프라인에 즉시 도입하여 성능 최적화를 달성할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 23.수집 2026. 05. 23.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.