TL;DR
대형 언어 모델에서 긴 컨텍스트를 처리할 때의 이차 복잡도는 계산량과 메모리 소모를 크게 증가시킨다. 본 연구는 완전한 full-attention이 이미 내재적 희소성을 가지며, Cue 기반의 헤드 분리와 저차원 검색공간으로의 매핑으로 추가 학습 없이도 희소 추론으로의 전환이 가능함을 보인다. 이로써 긴 문서나 고해상도 다-turn 대화에서의 효율과 정확도 간 균형을 바꿀 수 있다. 또한 dynamic top-p와 자체 증류를 통해 훈련 비용을 최소화하면서도 near-lossless 정확도를 유지한다.
왜 중요한가
대형 언어 모델에서 긴 컨텍스트를 처리할 때의 이차 복잡도는 계산량과 메모리 소모를 크게 증가시킨다. 본 연구는 완전한 full-attention이 이미 내재적 희소성을 가지며, Cue 기반의 헤드 분리와 저차원 검색공간으로의 매핑으로 추가 학습 없이도 희소 추론으로의 전환이 가능함을 보인다. 이로써 긴 문서나 고해상도 다-turn 대화에서의 효율과 정확도 간 균형을 바꿀 수 있다. 또한 dynamic top-p와 자체 증류를 통해 훈련 비용을 최소화하면서도 near-lossless 정확도를 유지한다.
핵심 기여
Head-wise sparse attention 설계
Retrieval Head와 Local Head를 구분하고, Retrieval Head에 대해서만 full KV 캐시를 유지하며 Local Head는 원래의 로컬 윈도우 패턴을 유지한다. 이로써 대부분의 헤드는 intrinsically sparse한 상태를 유지하되, 장거리 검색은 Retrieval Head에서만 수행된다.
저차원 근사 기반의 토큰 인덱스
RoPE의 저주파 구성요소에 주목하여 Retrieval Head를 위한 low-dimension projector(WQh, WK h)로 SH(m,·)를 근사한다. 16차원으로도 약 90% 재현율을 달성하며, 실제 검색 후보 토큰은 Top-p로 선별되어 전체 연산을 줄인다.
쿼리 의존적 dynamic Top-p 선택
동적 Top-p를 통해 헤드별 쿼리 특성에 따라 필요한 토큰 수를 조정한다. 고정 Top-k이 가지는 한계를 피하고, 질의가 다양한 경우에도 높은 재현율과 정확도를 유지한다.
두 단계 학습으로 성능 회복
(1) Stage-1에서 저차원 프로젝션 파라미터를 학습해 a_full(h)와 a_proj(h)의 KL 발산을 최소화하고, (2) Stage-2에서 End-to-End Self-Distillation을 수행해 sparse 모델이 dense Teacher의 next-token 분포를 모방하도록 한다. 특히 Top-10 logits만 정합 학습한다.
하드웨어 인식형 디코딩 커널
Top-p 디코딩을 히스토그램 기반으로 구현하고, block-sparse-attention을 이용한 디코딩 커널을 구성한다. 32K~1M 컨텍스트에서 전처리-디코드 구간 모두에서 속도 향상을 달성한다.
핵심 아이디어 이해하기
출발점: Transformer의 Self-Attention은 시퀀스 길이에 비례하는 계산 복잡도에서 한계가 드러난다. 공개된 선행 연구는 헤드의 역할 분화와 로컬 vs 원거리 정보의 차이를 지적해 왔다. 해결 원리: <>를 식별하고, RoPE의 저주파 구성요소를 이용해 16차원 저차원 서브스페이스에서 원거리 검색 신호를 재구성한다. 쿼리 의존적 토큰 예측 budget을 적용해 Top-p 기반의 동적 선택을 수행하고, Stage-1에서 저차원 프로젝션을 학습한 뒤 Stage-2에서 self-distillation으로 dense-teacher의 분포를 따라가도록 한다. 달라지는 점: 이 방식은 1M 컨텍스트에서도 9.36× prefill, 2.01× decode 속도향상과 near-lossless 정확도 달성을 가능하게 하며, native sparse pretraining 없이도 full-attention 모델의 효율화를 가능하게 한다.
관련 Figure
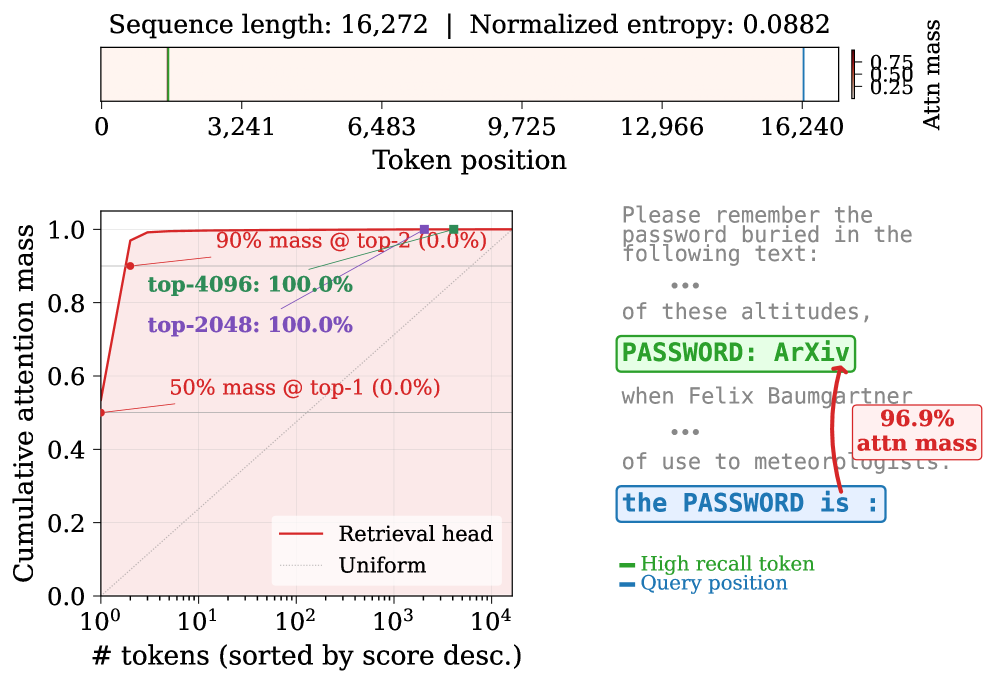
헤드 차별화가 검색 헤드의 원거리 기억과 로컬정보 처리 간의 역할 분담을 형성함을 보여준다.
Figure 2: Head Specialization을 시각화한 다이어그램
방법론
- Offline Head-wise Calibration: Needle-scan 방식으로 Npre, Npost를 정의하고 Rh = (1/|Npost|) Σt∈Npost Σj∈Npre Ah(t,j)으로 Retrieval Head의 검색 능력을 측정한다. 2) Low-rank Retrieval Routing: RoPE 이전의 qu_pre m,h과 k_pre n,h에 대해 WQh, WKh를 적용한 로우랭크 점수 sh(m,n) = q_pre^⊤WQh^⊤WKh k_pre이며, Sh(m) = Top-P(sh(m,·), p)로 활성 토큰 집합을 구성한다. Oh(m) = Σn∈Sh(m) exp(q_m^⊤kn,h/√dh) / Σj∈Sh(m) exp(q_m^⊤kj,h/√dh) 및 Sh(m) = Top-P으로 계산한다. 3) 동적 임계치 규칙: 각 헤드에 대해 서로 다른 토큰 예측 budget을 적용한다. 4) Two-Stage Training: Stage-1에서 a_full(h)와 a_proj(h)를 KL 발산으로 정렬하고, Stage-2에서 Top-10 logits에 대해 distillation 손실 KL(softmax(z_dense(10)) ∥ softmax(z_sparse(10))). 5) 하드웨어 커널: Top-p 디코딩을 히스토그램 기반으로 구현하고, block-sparse-attention과 cross-split reduce를 결합하여 메모리 오버헤드를 최소화한다.
관련 Figure
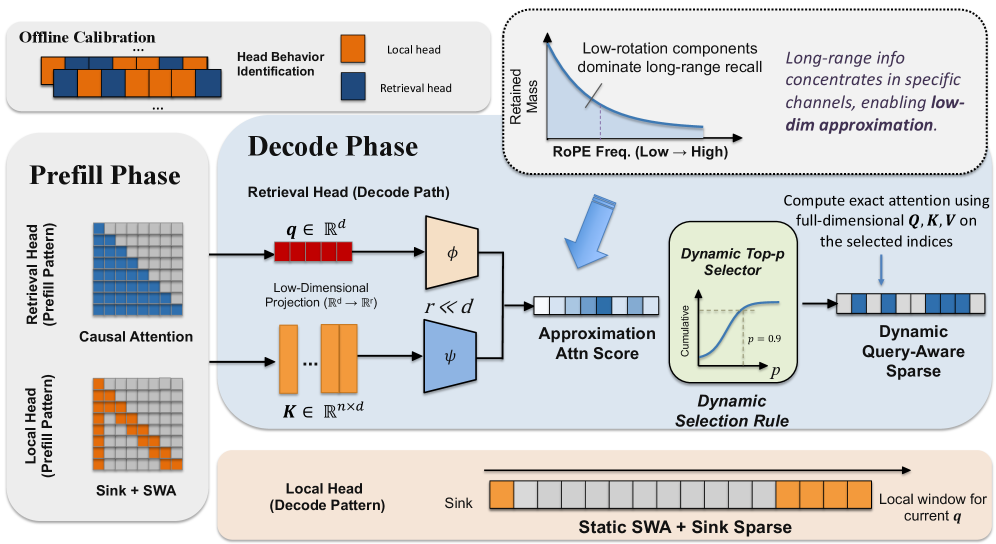
Offline Calibration → Decode Phase의 Retrieval Head와 Local Head 구조, Low-dim Projection과 Dynamic Top-p의 흐름을 보여준다.
Figure 4: RTPurbo 전체 아키텍처
주요 결과
벤치마크: LongBench/RULER에서의 정확도 비교. LongBench 평균에서 Full Attn 53.80% 대비 RTP Turbo w/top-p 54.24%로 소폭 상회. RULER(64K) Avg. Full Attn 86.23% vs RTPurbo w/top-p 85.49%로 near-lossless 수준을 보임. Reasoning 벤치마크(AIME24/AIME25/MMLU-PRO 등)에서 RTPurbo w/top-p가 대체로 Dense 모델과 근접하거나 일관된 성능을 유지하며, AIME 계열에서 86.67% 수준의 성능을 달성. MMLU-PRO 하위카테고리에서도 대체로 Dense 대비 손실이 작고, 전체 Avg는 90.06 근처를 기록. Ultra-long context에서의 성능은 컨텐츠 길이가 128K~512K로 확장될 때도 97%대의 정확도 유지 및 89.2% 이상의 sparsity를 달성한다. 효율성: Prefill 속도up 2.83×(32K)에서 9.36×(1M), Decode 속도up은 1.47×(32K)에서 2.01×(1M)까지 증가. 512K 컨텍스트에서도 97.1% 이상의 sparsity를 유지하며 정확도 저하를 최소화한다. 4-헤드 이하의 dynamic budget 구성과 per-head thresholding으로 긴 컨텍스트에서도 안정적 작동.
관련 Figure
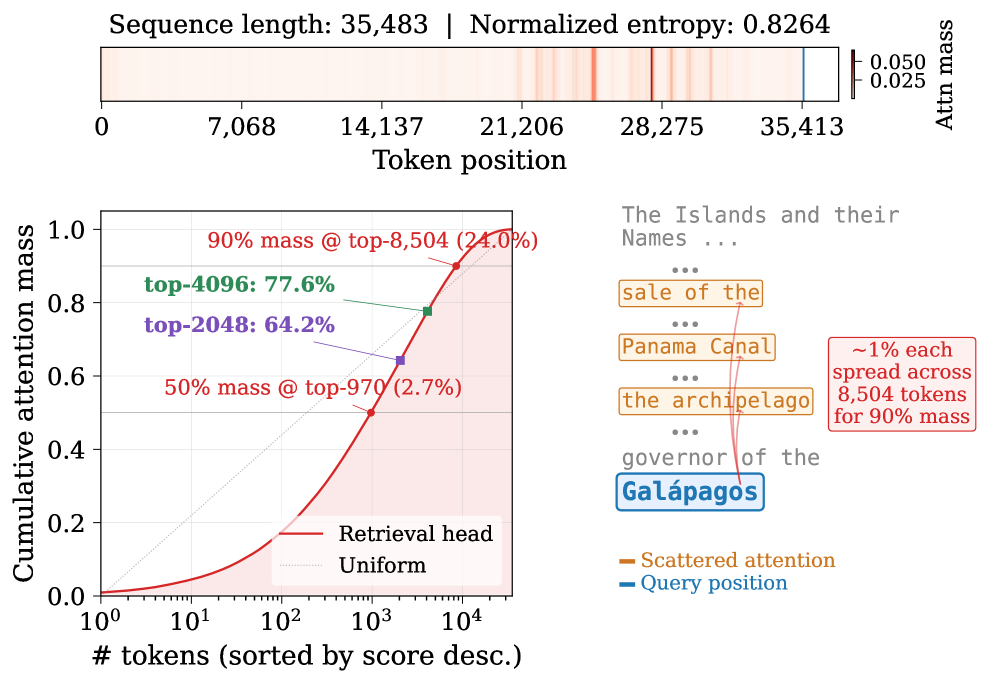
Prefill 속도up과 Decode 속도up 간의 상관관계를 시각적으로 제시하며, dynamic top-p가 긴 컨텍스트에서도 안정적으로 정확도를 유지함을 시사한다.
RTPurbo의 컨텍스트 길이에 따른 prefill 속도향상과 decode 속도향상을 한 눈에 보여주는 teaser 차트
기술 상세
아키텍처: Offline Calibration-Decode 파이프라인으로, Local Head는 슬라이딩 윈도우/_sink 패턴으로 처리하고 Retrieval Head는 prefill 시점에 full KV 캐시를 구성한 뒤 decode에서 Sparse Attention을 수행한다. 수학적 근거: RoPE 저주파 구성요소가 long-range recall에 안정적 신호를 제공한다는 점을 활용해, SH(m,·)의 Top-P를 통해 필요한 토큰 집합을 구성한다. 차별점: Prior work의 고정 Top-k이 아닌 쿼리 의존적 Top-p를 도입해 다양한 질의에 대해 적합한 토큰 예측 Budget을 제공한다. 학습 세부: Stage-1에서 8.6e5 파라미터 규모의 low-dim projection를 각 Retrieval Head에 대해 학습; Stage-2에서 top-10 logits를 이용한 distillation으로 dense Teacher의 분포를 따라가도록 한다. 하드웨어 커널: 두 개의 GPU 커널로 구성된 Top-p 디코딩. Kernel 1(D16)에서 per-block scoring 및 histogram 기반 threshold, Kernel 2(D128)에서 block-sparse attention과 cross-split reduce를 수행한다. 최적화: 256-bin 히스토그램, 1KB 메모리 오버헤드, Atomic counters로 동기화한다. 디코딩 파이프라인은 32K~1M 컨텍스트에서 FA2 대비 안정적 속도향상을 달성하도록 설계되었다.
관련 Figure
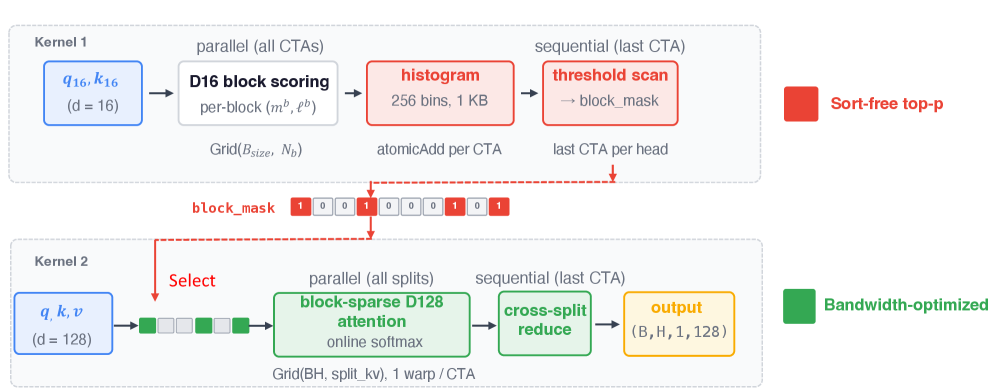
히스토그램 기반의 sort-free Top-p 디코딩과 block-sparse attention의 구현 흐름을 시각화하여 디코딩 커널의 구조적 특징을 드러낸다.
Figure 5: 하드웨어 인식형 디코딩 커널 개요
한계점
헤드 특화의 안정성 의존성: Offline calibration에 의해 Retrieval/Local 헤드가 구분되나, 도메인 이동이나 모델 구조 변화에 따라 분류 품질이 저하될 수 있음. 또한 현재 설계는 prefill에서 Retrieval Head의 Dense Attention을 유지하고 decode에서 Sparse Attention으로 넘어가므로 prefill Sparsification 강화가 남아 있다. 다른 모델군과의 광범위한 검증이 필요하다.
실무 활용
긴 컨텍스트를 다루는 LLM에 대해 RTPurbo를 적용하면 native sparse pretraining 없이도 full-attention의 이점을 유지하며, prefill/decode에서 큰 속도 향상을 얻을 수 있다.
- 초장문 문서 요약 및 질의응답 시스템
- 다-turn 대화 에이전트의 긴 대화 기록 활용
- 장문 추론과 증거 검색이 필요한 QA 시스템
- 강화학습 기반의 길고 복잡한 대화 시나리오
코드 공개 여부: 비공개
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.