TL;DR
현실 세계의 임상 워크플로우는 고정된 증거 패키지가 아닌, 다양한 소스에서 동적으로 증거를 탐색하고 융합하는 에이전트를 필요로 한다. ClinSeekAgent는 EHR, 의료 영상, 외부 지식 소스를 통합적으로 탐색하는 자동화된 에이전트 파이프라인을 제시하며, 강력한 인퍼런스 모델의 성능을 개선하고 오픈 소스 모델 학습에도 활용 가능하다.
왜 중요한가
현실 세계의 임상 워크플로우는 고정된 증거 패키지가 아닌, 다양한 소스에서 동적으로 증거를 탐색하고 융합하는 에이전트를 필요로 한다. ClinSeekAgent는 EHR, 의료 영상, 외부 지식 소스를 통합적으로 탐색하는 자동화된 에이전트 파이프라인을 제시하며, 강력한 인퍼런스 모델의 성능을 개선하고 오픈 소스 모델 학습에도 활용 가능하다.
핵심 기여
다중 소스 증거 탐색 파이프라인
EHR retrieval, 웹 검색, 의학 영상 분석 도구를 통합한 자동화된 에이전트 파이프라인을 제공한다. 이를 통해 고정된 컨텍스트에 의존하지 않고 데이터의 다양성과 시계열 정보를 활용해 임상 의사결정을 grounded하게 수행한다.
ClinSeek-Bench를 통한 인퍼런스 검증
Curated Input과 Automated Evidence-Seeking의 paired 샘플링을 통해 동일한 task에 대해 두 설정에서 모델의 성능 차이를 평가하는 벤치마크를 구성한다.
강력한 에이전트 모델에서의 인퍼런스 개선
텍스트 기반 EHR task에서 Claude Opus 4.6은 Curated Input 대비 3.2ppt, MiniMax M2.5는 4.2ppt 상승을 달성하고, 멀티모달-task에서 Claude Opus 4.6은 15.1ppt 개선 등 다중 소스 증거 탐색의 이점을 보인다.
오픈소스 학습 파이프라인으로의 전이
ClinSeekAgent의 trajectories를 이용해 Qwen3.5-35B-A3B를 미세조정하여 ClinSeek-35B-A3B를 얻고 AgentEHR-Bench에서 Open-Source 모델 중 최상위 수준의 성능을 달성한다(Avg F1 34.0).
핵심 아이디어 이해하기
단락 1: 시작점과 한계 – 임상 의사결정은 텍스트 기반의 요약이나 벤치마크의 curated context에 의존하기 쉽고, longitudinal한 EHR, 영상 데이터, 외부 지식의 조합이 필요한 상황에서 고전적 접근은 정보 결손으로 오답 가능성이 커진다. Transformer의 Self-Attention이나 기존 LLM의 단일 프롬프트 추론은 다소 고정된 맥락에서 작동하며, 장기 의사결정에 필요한 증거를 능동적으로 탐색하기 어렵다. 기본 가정은 증거가 모델에 이미 handover되어 있다는 점이다. 구체적 한계는 긴 호환성의 증거를 분리된 단계에서만 다룬다는 데 있다. 단락 2: 해결 원리 – ClinSeekAgent는 20개의 도구를 갖춘 공통 도구 공간(EHR 조회 11, 웹 브라우저 3, 영상 분석 6)을 통해 task x = (p, t, q, M, Y)에서 시작해 hk-1의 이력에 따라 ak를 선택하고 관찰 ok를 얻어 ŷ를 산출한다. EHR 관련 쿼리는 참조 시점 t 이전 데이터로 제한되며, 도구 호출은 순차적으로 누적되는 궤적 τ = (x, (ak, ok)) 형태로 기록된다. 이를 통해 의료 신호를 시간 축으로 추적하고 다양한 모달리티를 조합해 근거를 grounded한 판단에 반영한다. 단락 3: 달라지는 점 – 기존의 curated-context 방식과 달리 에이전트가 스스로 원천 데이터에서 증거를 탐색하고, EHR, 웹, 영상 도구의 상호작용을 통해 증거를 재구성한다. 이로써 증거가 부족한 경우에도 다양한 소스에서 신호를 찾고, 장기 의사결정을 위한 계획 수립과 도구의 연쇄 사용을 가능하게 한다. 단락 4: 효과와 확장성 – 강력한 에이전트 모델과의 조합에서 텍스트 기반 TASK에서의 성능 상승뿐 아니라 멀티모달 TASK에서도 일관된 개선을 보인다. 또한 ClinSeekAgent를 통해 높은 품질의 에이전트 행동 trajectories를 수집하고, 이를 open-source 모델로 distill하여 ClinSeek-35B-A3B를 구축했다.
방법론
- Task Formulation: x = (p, t, q, M, Y)이며, 추론 중에는 Curated Input이 제공되지 않는다. hipothesis의 각 단계에서 ak은 πθ(·|x, hk-1)에 의해 결정되고, 도구 호출 시 ok를, 그렇지 않으면 최종 예측 ŷ를 출력한다. ehr 관련 작업은 ehr.load_ehr로 로딩하고 t 이전의 레코드만 조회한다. 2) Multi-Source Tool Space: 11개의 EHR 도구(스키마 인스펙션, 템포럴 RETRIEVAL, SQL 쿼리, 후보 항 grounding 등), 3개의 웹 도구, 6개의 이미지 도구를 제공한다. 3) Agentic Evidence-Seeking Trajectories: τ = (x, (ak, ok))_k=1..K, ŷ가 최종 결과이며, 증거 소스 간의 순서는 task에 따라 다르게 결정된다. 4) ClinSeek-Bench 구성: Curated Input(원 benchmark의 증거 패키지)을 유지한 채 같은 task와 라벨을 사용하고, Automated Evidence-Seeking에서는 curated context를 제거하고 ClinSeekAgent 도구로 필요한 증거를 수집하도록 구성한다. 5) 학습 및 평가: 텍스트 기반 벤치와 멀티모달 벤치를 병렬로 평가하고, 12개 모델에서 ClinSeekAgent 프레임워크의 효과를 분석한다. 6) Training-time SFT: Claude Opus 4.6를 teacher로 Trajectory를 수집해 Qwen3.5-35B-A3B를 미세조정하여 ClinSeek-35B-A3B를 얻는다. 7) 수치 및 실험 설정: 52k 토큰 길이의 native tool-call 포맷으로 데이터가 구성되며, 8×H200 GPU 환경에서 학습이 수행되었다. 8) 도구 사용 분포 분석: SFT 후 도구 호출 분포가 다변화되어, ehr.run_sql_query와 같은 도구 사용 비율이 증가한다. 이로써 학생 모델은 EHR를 프로그래머블 데이터베이스처럼 다루는 정책을 학습한다.
주요 결과
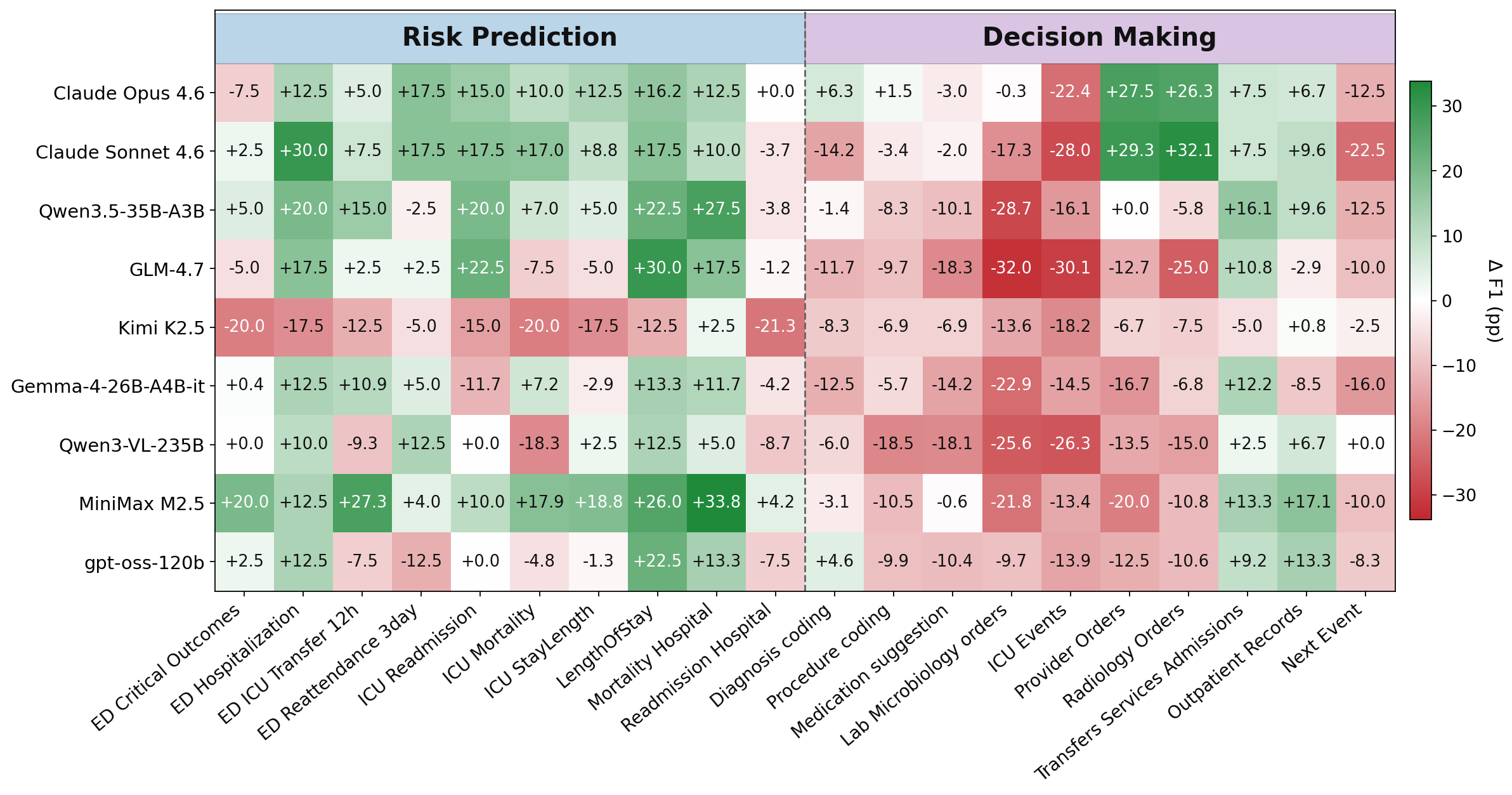
- 주된 벤치마크 결과: 텍스트 기반 EHR TASK에서 Claude Opus 4.6은 ClinSeekAgent 적용 시 60.0에서 63.2로, MiniMax M2.5는 43.1에서 47.3으로 상승했다(표 1). 2) 멀티모달 TASK에서의 증가: Claude Opus 4.6은 47.5에서 62.6으로 상승(+15.1), Claude Sonnet 4.6은 48.0에서 54.9로 상승(+6.9), Qwen3-VL-235B는 43.9에서 49.8(+5.9), Gemma-4-26B-A4B-it은 38.2에서 44.9(+6.7)로 상승했다(표 2). 3) 실패 분석: 결정(task)군에서 ClinSeekAgent의 이점이 불확실하며 일부 경우 성능이 저하된다. 예를 들어 Qwen3.5-35B-A3B의 위험 예측에서는 +17.3ppt의 개선이 관찰되나, 의사결정(task) 영역에서는 도구 탐색의 과잉 정보로 핵심 신호를 놓치는 사례가 존재한다. 4) Training-time 결과: ClinSeek-35B-A3B가 AgentEHR-Bench의 다섯 과제에서 평균 F1이 34.0으로 증가했고, Teacher 대비 94.4% 수준의 성능에 도달한다. Diagnoses(+18.8), Laboratory Events(+20.8), Microbiology Events(+11.4), Procedures(+9.8) 등에서 큰 개선이 나타났다. 5) 도구 사용 변화: SFT 이후 ehr.run_sql_query 등 SQL 도구의 사용이 크게 증가하였고, 도구 정책은 EHR를 프로그래머블 데이터베이스로 다루는 방향으로 확장됐다.
관련 Figure
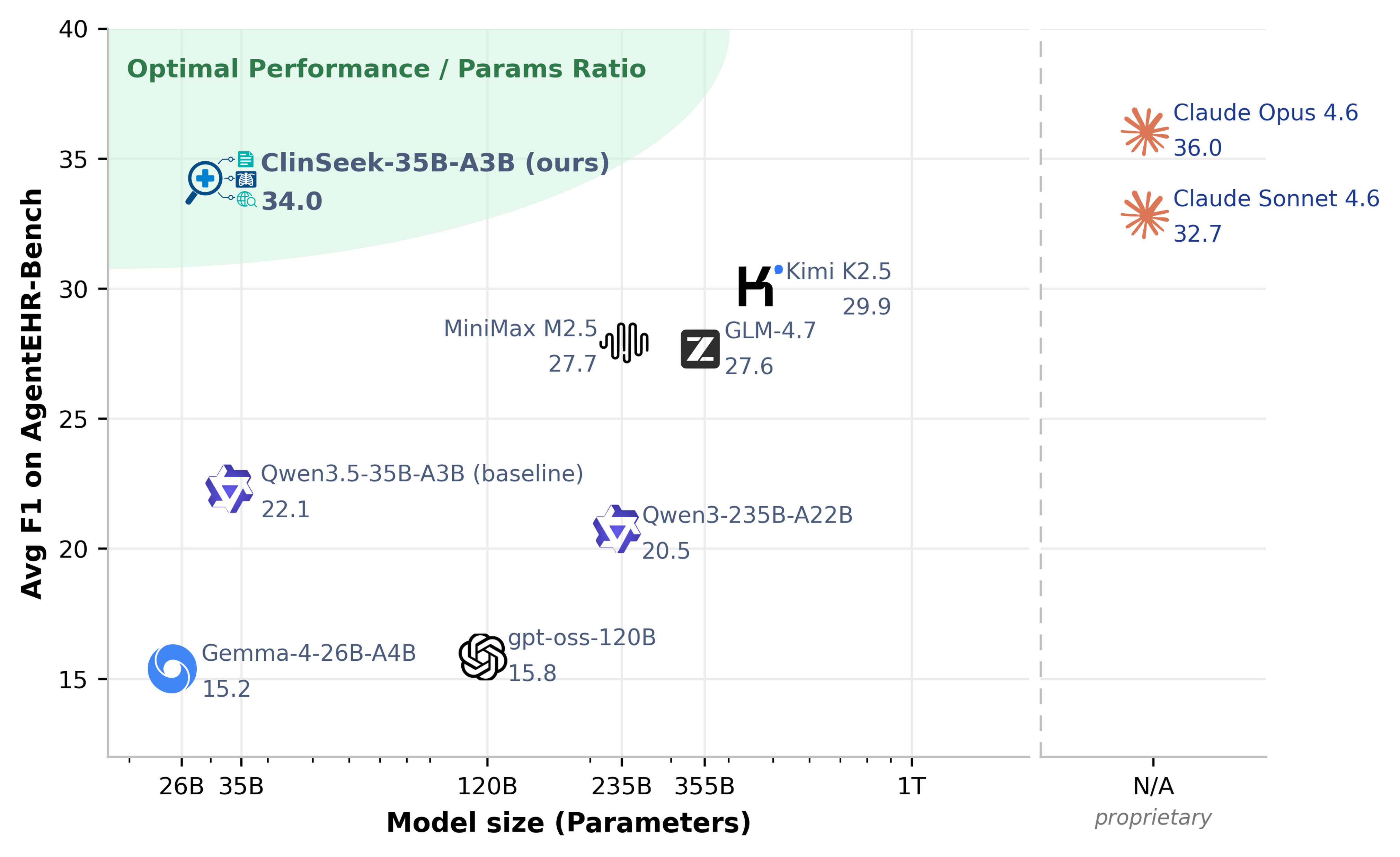
강력한 에이전트 모델에서의 도구 사용 정책이 모델 규모에 비례해 더 큰 이점을 제공함을 시사한다.
텍스트-기반 EHR 과 멀티모달 TASK의 성능-모델크기 비교 차트로, ClinSeekAgent의 오픈소스 모델들이 강력한 성능 향상을 보인다.
CXR 기반 멀티모달 태스크에서 도구 결합의 효과가 크다—이미지 정보와 EHR, 외부 지식의 조합이 정확도 향상을 견인한다.
멀티모달 벤치에서의 결과 비교: CXR 관련 태스크에서 일관된 개선을 보임.

사례 연구를 통해 멀티모달 도구의 조합이 실제 예측 성능 개선으로 연결될 수 있음을 보여준다.
구체 사례 비교: ClinSeekAgent가 도구를 활용해 83.3의 F1로 Curated Input 대비 큰 차이를 낸 사례.
기술 상세
- 아키텍처: EHR retrieval(11 도구) + Web browser(3 도구) + Image analysis(6 도구)로 구성된 단일 도구 공간. 2) 수학적 기반: x=(p,t,q,M,Y)이며, k번째 행동은 ak ∼ πθ(·|x,hk-1)로 결정되고, 도구 호출 시 ok를 수신한다. 3) 학습/미세조정: teacher 모델 Claude Opus 4.6로부터 ClinSeekAgent trajectories를 수집해 Qwen3.5-35B-A3B를 SFT로 학습, 52K 토큰 길이의 native 포맷으로 구성되며, 3에폭 학습, 8×H200 GPU에서 수행한다. 4) Distillation 효과: ClinSeek-35B-A3B는 도구 사용 다양성(특히 SQL 도구 ehr.run_sql_query)의 활용 증가를 통해 오픈 소스 에이전트의 성능을 상향시켰고, 5) 비교 연구: Curated Input과의 차이점은 증거 탐색의 자동화 및 다중 모달 간의 결합에 있다.
관련 Figure
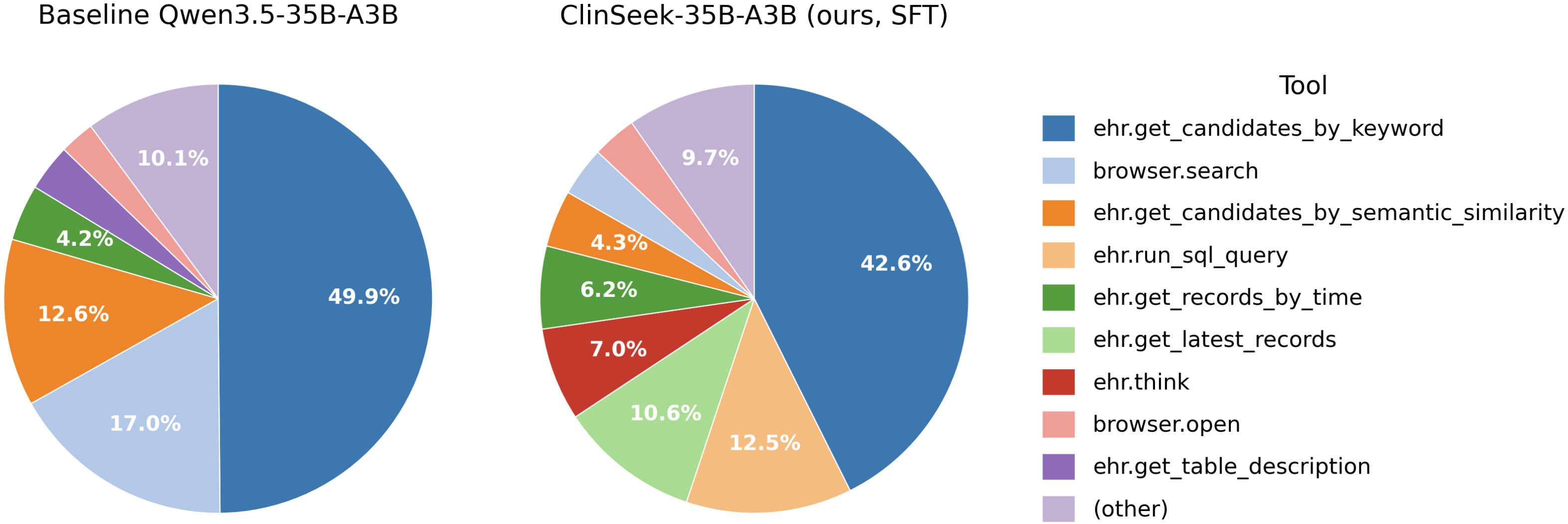
도구 사용의 다양화가 성능 개선의 주된 원인임을 시사하며, 이로 인한 학습-추론 간의 정책 차이가 나타난다.
도구 호출 분포를 보여주는 파이 차트. ClinSeekAgent의 도구 사용 비율 변화를 시각화.
한계점
평가 데이터셋이 비교적 단순하며, 긴 하이레벨 멀티모달 의사결정 시나리오를 충분히 stress 테스트하지는 못한다. 교사 모델의 Trajectory 중에는 중복되거나 지나치게 가치가 낮은 도구 호출이 포함될 수 있어 학생 모델의 학습 방향을 왜곡할 수 있다. 향후 연구에서는 보상 기반 강화학습(RLHF)이나 튜닝-전이 기법으로 더 효율적이고 견고한 증거 탐색 정책을 학습하는 방향이 필요하다.
관련 Figure
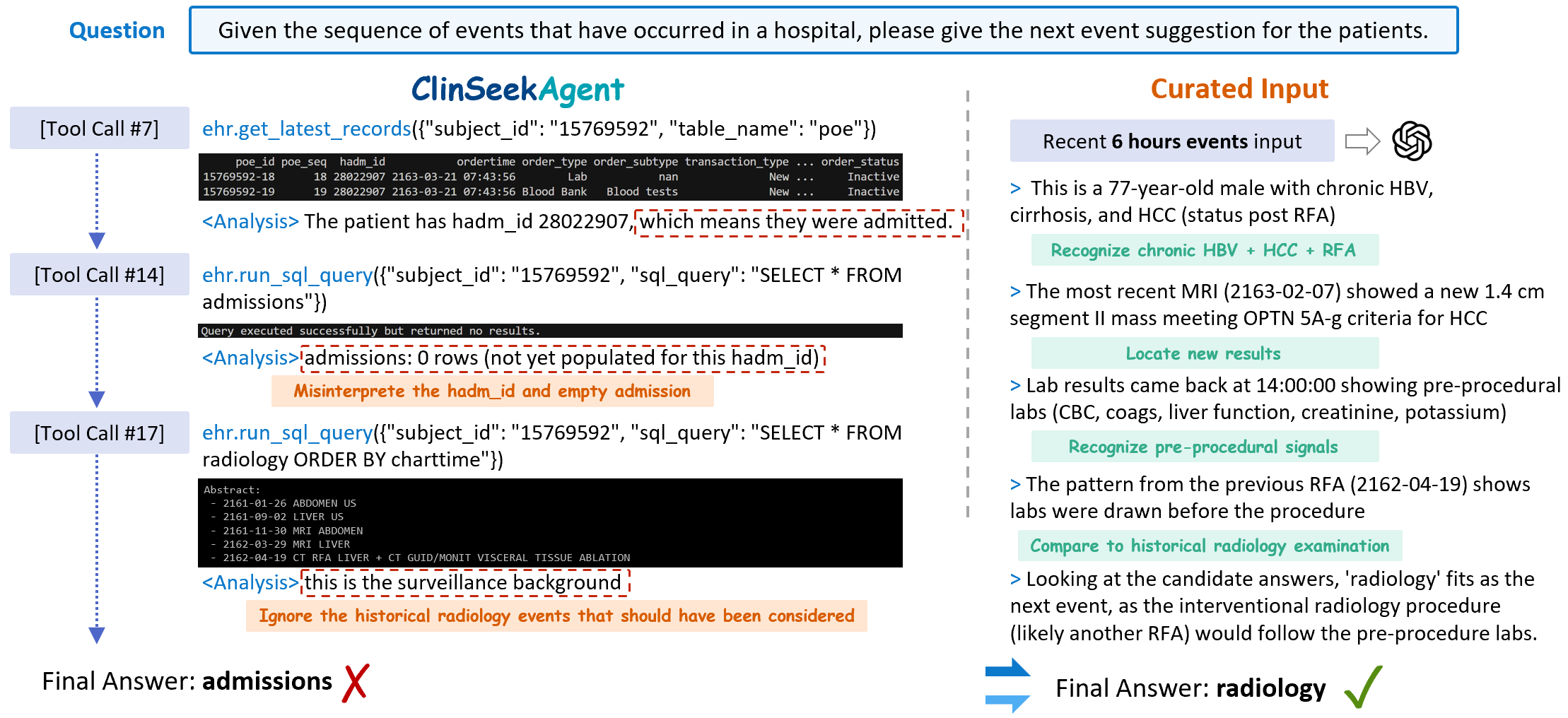
한계점으로 제시된 failure case를 시각화하여, 현 연구의 한계 및 향후 개선 포인트를 보강한다.
Failure 사례: 결정-메이킹 태스크에서 증거 탐색이 부족하거나 잘못된 신호를 따라가는 문제를 다룬 사례.
실무 활용
임상 현장에서 EHR, 의료 영상, 외부 지식을 결합해 증거를 자동으로 수집하고 근거를 grounded한 의사결정을 돕는 파이프라인이다. 인퍼런스 시간 및 학습 시간 파이프라인 양쪽에서 성능 향상을 달성한다.
- Risk prediction: Mortality, LengthOfStay, 24h decompensation 예측
- In-hospital mortality 예측 및 phenotype 예측
- CXR 영상 기반 질환 판단 보조와 EHR 신호의 통합
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.