TL;DR
OmniPro는 옴니모달(perception) 인지, 프로액티브 응답, 그리고 다양한 비디오 이해 태스크를 하나의 프레임워크로 평가하는 최초의 벤치마크이다. 2,700샘플, 9개 서브태스크로 구성되고 84%의 샘플이 오디오 의존성을 가지며, 모달리티 분리 라벨을 제공해 미세한 멀티모달 분석이 가능하다. Probe 모드와 Online 모드를 모두 이용한 이중 평가 프로토콜을 도입하여 콘텐츠 이해도와 실제 스트리밍 상의 자율 응답 능력을 함께 측정한다. 실험 결과, 오디오-비주얼 입력이 비디오 단독 입력보다 일관되게 이득을 주며, 트리거가 영상의 뒤쪽으로 갈수록 성능 저하가 커지고 비언어(non-speech) 음향 인식의 한계가 드러난다.
왜 중요한가
OmniPro는 옴니모달(perception) 인지, 프로액티브 응답, 그리고 다양한 비디오 이해 태스크를 하나의 프레임워크로 평가하는 최초의 벤치마크이다. 2,700샘플, 9개 서브태스크로 구성되고 84%의 샘플이 오디오 의존성을 가지며, 모달리티 분리 라벨을 제공해 미세한 멀티모달 분석이 가능하다. Probe 모드와 Online 모드를 모두 이용한 이중 평가 프로토콜을 도입하여 콘텐츠 이해도와 실제 스트리밍 상의 자율 응답 능력을 함께 측정한다. 실험 결과, 오디오-비주얼 입력이 비디오 단독 입력보다 일관되게 이득을 주며, 트리거가 영상의 뒤쪽으로 갈수록 성능 저하가 커지고 비언어(non-speech) 음향 인식의 한계가 드러난다.
핵심 기여
OMNIPRO 벤치마크의 도입
Omni-proactive 영상 이해를 위한 최초의 포괄적 벤치마크로, 2,700 samples, 9개 서브태스크, 3수준의 태스크 구조를 제시하고 84%의 샘플이 audio 의존성을 가지며 6가지 비디오 이해 능력을 포괄한다.
트리탑 구조의 태스크 분류
Perception, Comprehension, Reasoning의 3단계 계층으로 구성되며, 6가지 기본 비디오 이해 역량(Alert, Monitoring, Grounding, Counting, Narration, Prediction)을 포괄하는 9개 서브태스크를 제공한다.
듀얼 모드 평가 프로토콜
Probe 모드는 ground-truth 트리거마다 사전/사후 프로브를 통해 콘텐츠 이해도를 측정하고, Online 모드는 스트리밍 영상에서 자율적으로 응답 시점을 결정하도록 하여 실제 프로액티브 능력을 평가한다.
다양한 모델에 대한 포괄적 평가
11개 대표 모델(개방형 + 독점형)을 Probe와 Online 양 모드에서 평가하여 모달리티 활용 차이, 장기 트랙잉의 한계, 비언어 음향 인식의 취약점을 분석한다.
데이터 생성 파이프라인 및 공개
LongVALE와 COIN에서 원천 비디오를 수집하고 Gemini 3 Flash를 이용한 템포럴 Dense Captioning과 QA 파생 과정을 통해 2,700 샘플의 질 높은 QA 세트를 자동 생성하고 30%의 재검토를 거쳐 품질을 보장한다. 데이터셋과 템플릿은 공개한다.
핵심 아이디어 이해하기
- 옴니-모달 인지와 콘텐츠 이해, 2) 시나리오에 따라 스스로 언제 응답할지 결정하는 proactive capability, 3) 영상 이해의 다양한 능력(발견/추적/ counting/ Grounding/ Narration/ 예측)을 결합한 평가의 필요성이라는 3가지 직관에 기반한다.
다음으로 Dense Captioning과 QA 파이프라인을 통해 트리거 시점을 정확히 매칭하고, 오디오-비디오의 교차 정보를 활용해 트리거를 탐지한다. 이때 9개 서브태스크를 3수준으로 구성해 단일 프레임워크에서 omni-modal 모델의 차이를 효과적으로 구분할 수 있도록 한다. 실험적으로는 오디오-시각 입력의 보완 효과가 모델별로 다르게 나타나며, 특히 비언어 음향의 인식이 전반적으로 최약한 bottleneck로 확인된다.
관련 Figure
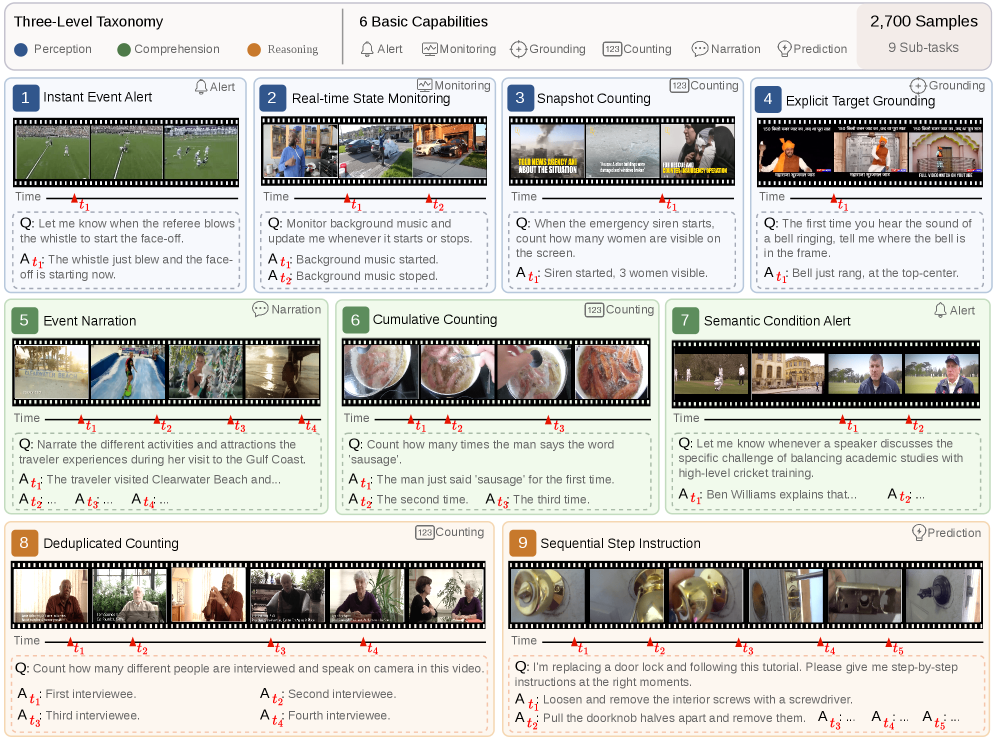
핵심 벤치마크 구성요소를 한 눈에 제시해 OMNIPRO의 설계 목표를 직관적으로 이해하게 한다.
Figure 1은 OMNIPRO의 9개 서브태스크를 3수준의 트리오로 구성한 개요를 제시하며, 각 panel은 비디오 프레임, 시간 정렬 트리거, 사용자의 지시(Q) 및 예측 반응(A)을 보여준다.
방법론
데이터 구성: LongVALE(일상 생활, 스포츠, 뉴스 등 다양한 장르)에서 1,171개 비디오와 COIN의 600개(주로 순차형 설명 영상)를 수집해 총 1,771개 원천 비디오를 확보한다. 자동 QA 파이프라인: Dense Captioning(Gemini 3 Flash)을 이용해 segment별로 caption(이벤트 요약), visual, audio, speech를 포함한 다중 모달 설명을 생성하고, 각 세그먼트를 바탕으로 QA 샘플을 합성한다. QA 파생: 원본 비디오와 dense captions, 태스크별 프롬프트로 질의응답 쌍을 생성하며, trigger time은 실제 영상 콘텐츠와 일치하도록 검증한다. 데이터 품질관리: 2회에 걸친 인간 검토를 통해 자연스러운 질문, 트리거 타임 정확도, 응답의 신뢰성, 모달리티 표기를 교정한다. 데이터 통계: 오디오 의존성은 84% 샘플에서 중요하고, 트리거는 시각+음성+소리 조합에서 주로 발생하며 첫 트리거 평균은 약 54.1초, 마지막 트리거 평균은 126.2초로 긴 호수(over-long horizon)에서의 지속 주의가 필요함.
평가 프로토콜: Probe 모드는 ground-truth 트리거마다 트리거 이전/이후 각 두 번의 쿼리로 내용 이해를 평가하고, Online 모드는 스트리밍 비디오에서 자체적으로 응답 시점을 결정하도록 한다. 측정 지표는 Probe에서 정확도(정확히 2개 프로브가 모두 정답일 때 해당 트리거를 정답으로 간주), Online에서 F1(타임스탬프 매칭 + 콘텐츠 정답 여부)이다. 입력은 1fps로 샘플링하며, 추론은 오픈 소스 모델의 경우 배치 없이Greedy 디코딩으로 수행했다.
관련 Figure
Dense captioning 및 QA 샘플 생성의 구체적 구성 방식을 보여주며 데이터 구축의 재현성을 확인시킨다.
Dense Captioning Prompt의 스크린샷으로 데이터 생성 프롬프트를 제시한다.
주요 결과
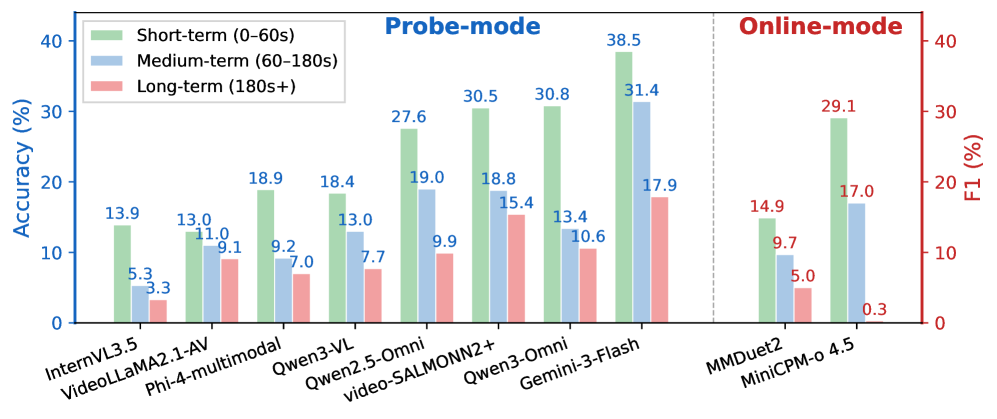
주요 결과는 다음과 같다. (1) Gemini-3-Flash가 오프라인 전체에서 평균 40.4%의 정확도으로 가장 우수했고, 오픈 소스 최상은 22.1%였다. (2) 오디오-멀티모달(A+V) 입력은 비디오 단독 대비 +2.4 ~ +11.1 포인트의 이점을 제공했다. (3) Online 모드는 더 어려워 MiniCPM-o 4.5의 F1이 20.9%에 그쳤고, 이벤트-나래이션(Event-Narr.) 및 Sequential Step Instruction 같은 생성 중심 태스크에서 성능 저하가 커졌다. (4) 추론 단계가 많은 Step-Inst.류의 태스크에서 1차 간극이 가장 크게 나타났고, Step-Inst.의 평균 점수 차이는 Gemini-3-Flash와 오픈 소스 간에 크게 벌어졌다. (5) 모달리티 기여 분석에서 A+V 조합은 태스크에 따라 다르게 기여하며, 이벤트-발생 탐지에는 Audio가, Dedup-Count 등 일부 태스크에는 Video가 더 큰 역할을 한다. 비언어 음향(non-speech audio) 인식에 대한 한계는 모든 모델에서 보편적으로 나타났다.
관련 Figure
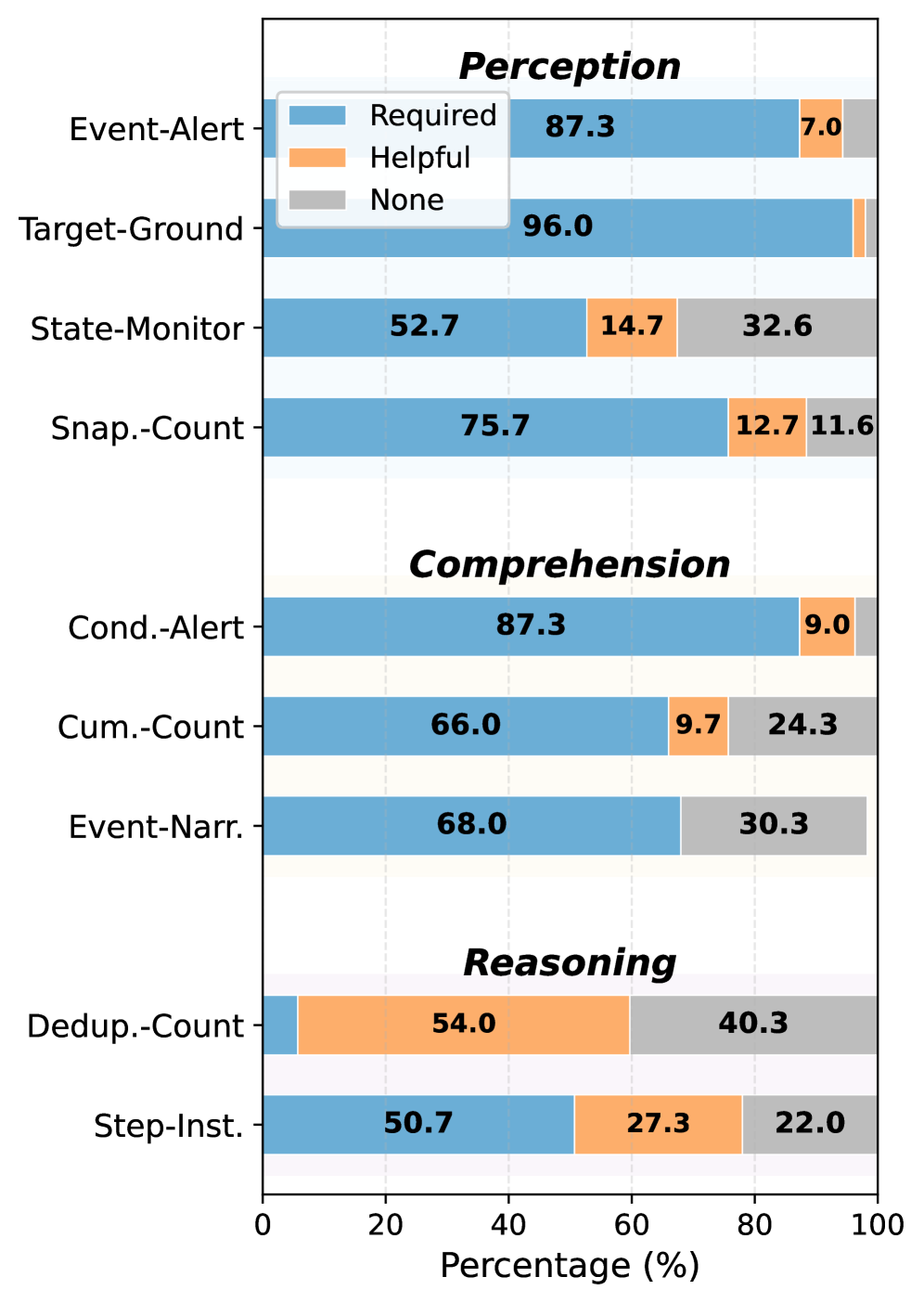
벤치마크의 데이터 특성과 오디오-비디오의 결합 중요성을 수치로 확인시켜 준다.
Figure 2는 태스크별 오디오 의존성과 트리거 모달리티 비율을 포함한 데이터 통계를 보여준다.
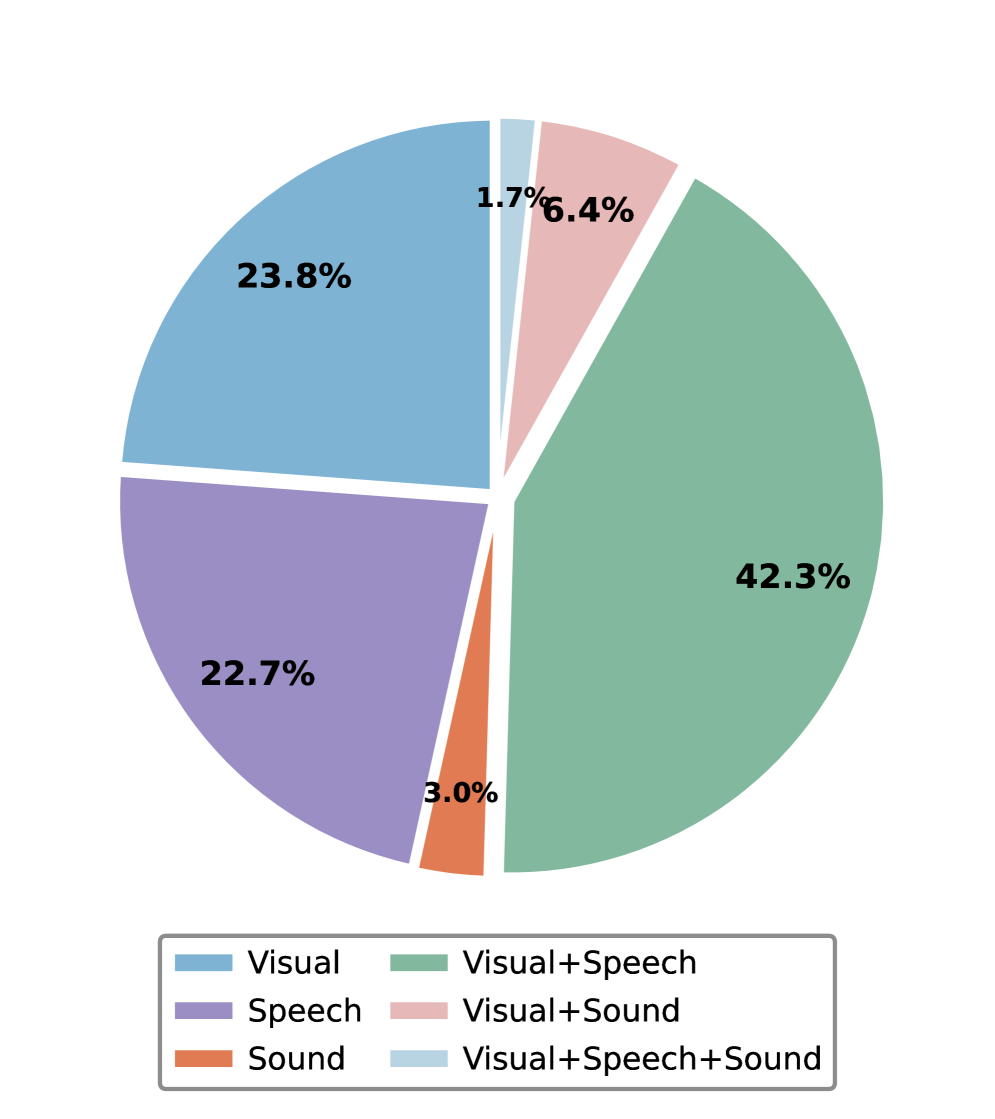
다중 모달 트리거의 비중과 cross-modal 특성을 강조하며 omni-modal 성능의 차별화를 돕는다.
Circle(도넛) 차트로 트리거 모달리티 비율을 시각화한다.
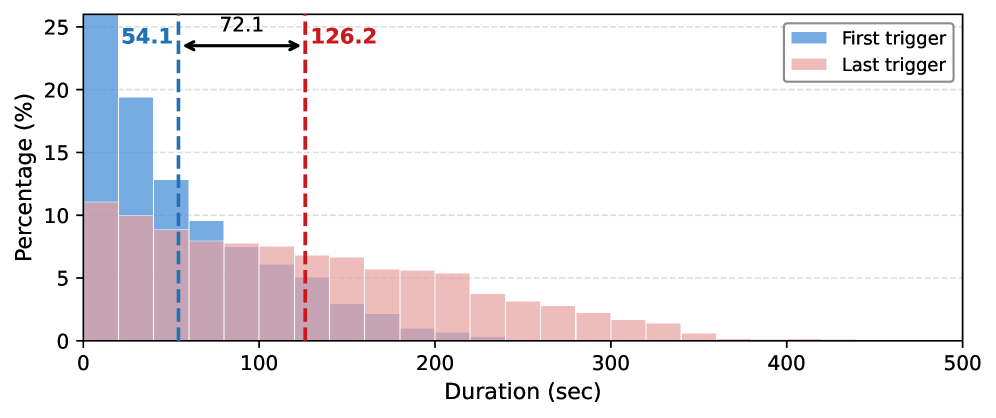
장기 지속 주의의 도전과 트리거 시점의 분포를 직관적으로 보여준다.
Figure 2의 첫 트리거와 마지막 트리거 시간 분포를 나타내는 바 차트.
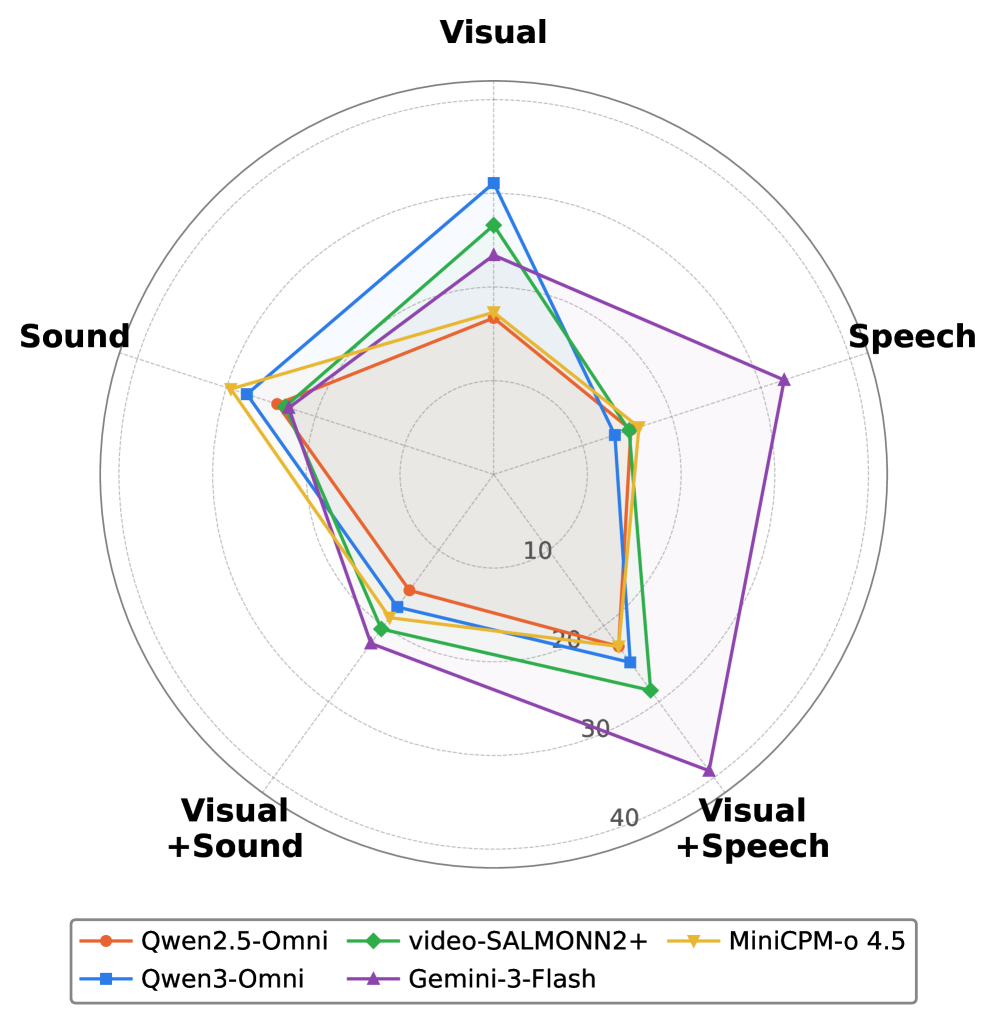
각 모델의 Visual/Speech/Sound 사용의 상대적 기여를 비교해 벤치마크의 핵심 인사이트를 구체적으로 보여준다.
모달리티 기여 분석을 위한 레더 차트(Radar)가 제시된다.
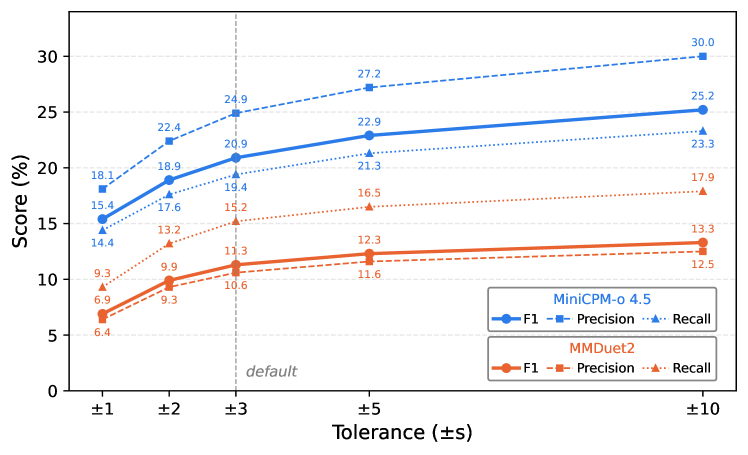
Online 모드의 F1과 tolerances의 영향력을 시각적으로 나타내어 스트리밍 평가의 난이도를 보여준다.
온라인 모드의 성능 추이와 허용 오차의 효과를 다룬 그래프.
실무 활용
OMNIPRO는 옴니-모달 대화형 비디오 이해를 평가하는 표준화된 벤치마크로, 실세계의 멀티모달 대화 에이전트 및 스트리밍 비디오 시스템의 품질을 진단하고 개선하는 데 활용될 수 있다.
- 스트리밍 비디오 기반의 대화형 LLM 평가 및 비교
- 모달리티 간 정보 통합의 효과를 정량적으로 분석
- 비언어 음향의 인식 개선을 위한 모델 설계 및 데이터 수집 전략 수립
- Long-horizon 이벤트 탐지 및 누적 추적의 모델 내장 여부 점검
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.