이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
AI 추론은 성능, 개발 생산성, 장치 이식성이라는 P3 문제 사이에서 균형을 찾아야 한다. 이 연구는 PyTorch 기반 LLM을 NVIDIA GPU에 배포할 때 torch.compile, TensorRT, XLA, ONNX Runtime 등 주요 MLC 도구의 성능과 트레이드오프를 체계적으로 평가한다. AOT(Ahead-Of-Time) 방식인 TensorRT-LLM은 고정된 모델에서 최고 성능을 보이나, JIT(Just-In-Time) 방식인 torch.compile은 유연성과 이식성을 제공하지만 LLM 추론에서 일관된 가속을 보이지 못한다. 실험 결과, 프로덕션 환경에서는 TensorRT-LLM이 유리하며, 연구 및 프로토타이핑 단계에서는 torch.compile이 적합한 것으로 나타났다.
대상 독자
LLM 프로덕션 배포 및 최적화를 담당하는 AI 엔지니어
의미 / 영향
이 연구는 LLM 배포 시 무조건적인 컴파일러 적용보다는 P3 우선순위에 따른 전략적 선택이 필요함을 시사한다. 특히 성능 중심의 프로덕션 환경과 유연성 중심의 연구 환경 간의 명확한 컴파일러 선택 가이드를 제공하여 배포 효율성을 높인다.
섹션별 상세
P3 문제는 성능(Performance), 생산성(Productivity), 이식성(Portability) 사이의 근본적인 상충 관계를 의미하며, MLC는 이를 해결하기 위해 고수준 모델을 하드웨어 최적화 코드로 변환한다.
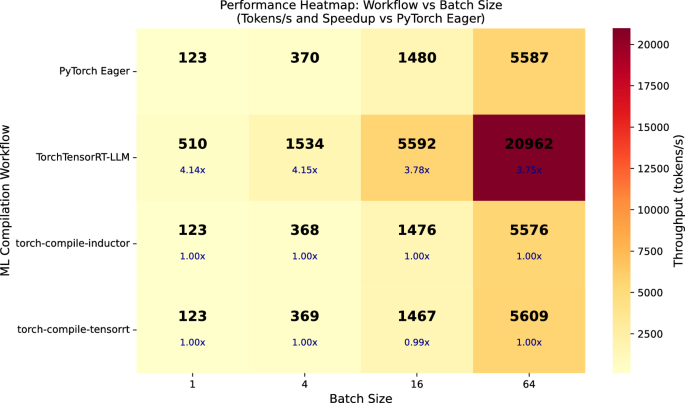
TensorRT-LLM은 LLM 전용 최적화와 KV 캐시 관리 기능을 통해 SOTA LLM에서 가장 높은 처리량을 기록하며, 배치 크기가 커질수록 성능 이점이 더욱 두드러진다.
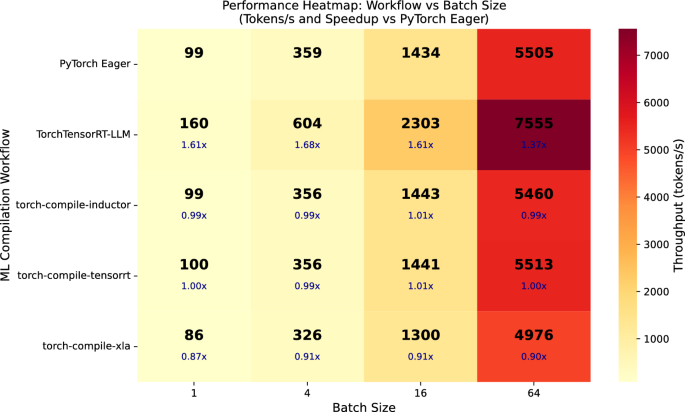
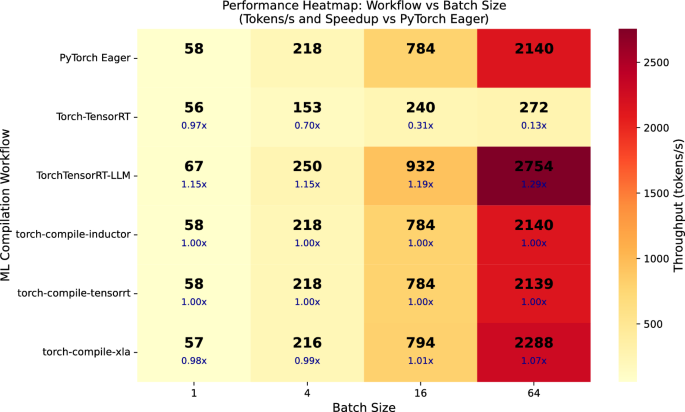
torch.compile은 PyTorch 생태계와의 높은 호환성과 유연성을 제공하지만, LLM의 generate() 과정에서 발생하는 동적 그래프 특성으로 인해 그래프 캡처가 불안정하여 성능 향상이 제한적이다.
합성 모델(Synthetic models) 벤치마크 결과, AOT 컴파일러는 컴파일 오버헤드가 발생하지만 추론 단계에서 동기화 비용을 줄여 성능을 극대화하는 반면, JIT 방식은 컴파일 오버헤드가 적으나 LLM 추론 가속에는 한계가 있다.
컴파일 오버헤드 분석 결과, 메모리 사용량은 모델 복잡도에 따라 증가하며, 특히 TensorRT 기반 워크플로는 컴파일 과정에서 원본 모델 대비 최대 2배의 VRAM을 점유할 수 있어 배포 환경의 메모리 제약을 고려해야 한다.
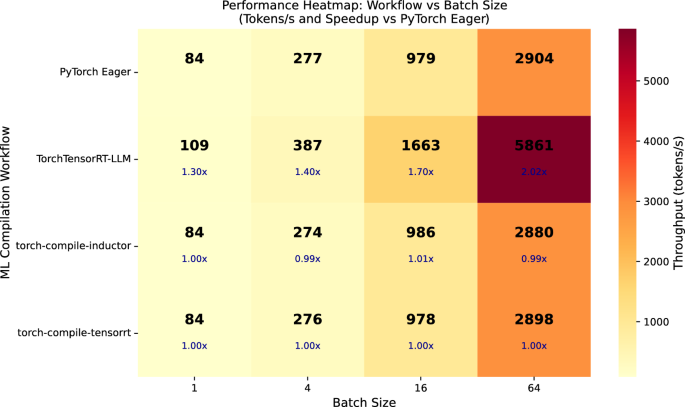
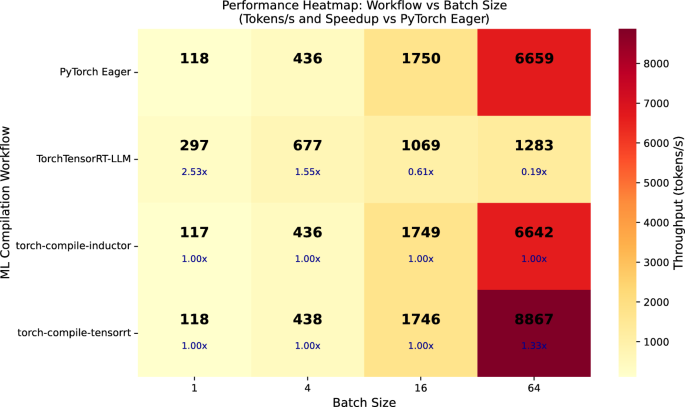
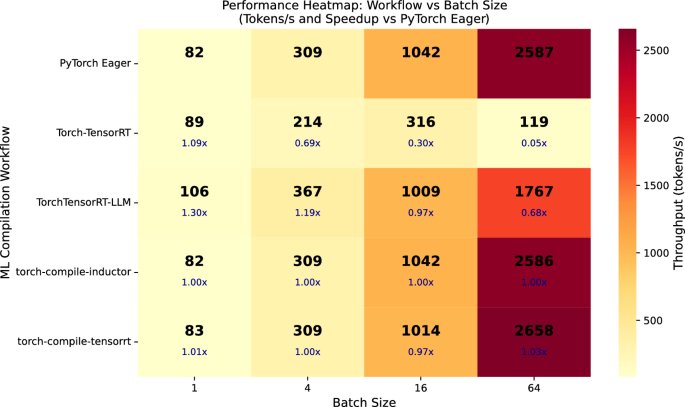
실무 Takeaway
- 프로덕션 환경에서 비용 효율성과 성능이 중요하다면 TensorRT-LLM을 우선적으로 고려해야 한다.
- 연구 및 빠른 프로토타이핑 단계에서는 생산성과 유연성을 위해 torch.compile(Inductor)을 기본값으로 사용한다.
- AOT 컴파일러 사용 시 컴파일 과정에서 원본 모델보다 많은 VRAM이 필요하므로, 배포 대상 GPU의 메모리 용량을 사전에 확인해야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 24.수집 2026. 05. 24.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.