TL;DR
Unified multimodal models(UMMs)은 이해와 생성의 성능을 하나의 공유 잠재 공간에서 학습하지만, 이해·생성 간 매핑의 비정렬로 인해 기능적 일관성이 손실된다. LatentUMM은 두 단계의 정합(dual latent alignment)과 잠재 다이내믹스의 안정화(latent dynamics stabilization)를 통해 모달 간 및 능력 간의 일관성을 명시적으로 보강한다.
왜 중요한가
Unified multimodal models(UMMs)은 이해와 생성의 성능을 하나의 공유 잠재 공간에서 학습하지만, 이해·생성 간 매핑의 비정렬로 인해 기능적 일관성이 손실된다. LatentUMM은 두 단계의 정합(dual latent alignment)과 잠재 다이내믹스의 안정화(latent dynamics stabilization)를 통해 모달 간 및 능력 간의 일관성을 명시적으로 보강한다.
핵심 기여
Dual latent alignment
강화된 embedding 모델 E*를 사용해 텍스트-이미지 간 교차 모달 정합과 이해-생성 간 역방향 정합을 동시에 추구한다. Lx-modal은 ϕ(xt)와 ϕ(xi)의 유클리드 거리로 교차 모달Semantics를 정렬하고, Lx-task는 z와 zˆ의 차이를 최소화해 이해-생성 간 책임 있는 변환을 보장한다.
Latent dynamics stabilization
확률적 잠재 롤아웃(K 샘플의 z(k) = z + ϵ(k))을 통해 다양한 경로를 샘플하고, z 및 zˆ(k) 간의 코사인 유사도로 각 경로의 일관성을 평가한다. Preferential 학습(Lpref)을 도입해 더 일관된 경로를 선별한다.
모델 교차 일반화 및 효율성
Bagel, Janus-Pro, Harmon 등 다양한 backbones에서 LatentUMM이 일관성과 생성/이해 성능을 모두 개선하고, rollout 빈도에 따른 오버헤드를 백본 학습의 주된 복잡도에 비해 작게 유지한다.
핵심 아이디어 이해하기
초기 배경: 이해와 생성은 동일한 latent space를 공유하더라도, 입력 인코딩과 출력 디코딩 간의 변환 경로가 명시적으로 조정되지 않으면 시맨틱 드리프트가 발생한다. Dual latent alignment는 E*가 매핑하는 강력한 공정 임베딩 공간에서 두 가지 변환(understanding, generation)을 서로 다른 방향으로 연결하되, 같은 기하학적 공간에서 일관되도록 학습 신호를 부여한다. Latent dynamics stabilization은 잠재 공간에서의 경로를 여러 차례 샘플링하고, 가장 안정적인 경로를 선호하도록 학습 신호를 구성한다. 이로써 모달 전환 시Semantics가 손실되지 않는 경로를 선별한다. 결과적으로 백본이 바뀌어도 일관된 잠재 기하학을 유지하며, cross-modal reasoning의 안정성이 증가한다. 정렬의 핵심 아이디어: Lx-modal은 cross-modal embedding 공간에서 모달 간 시맨틱 구조를 강화하고, Lx-task는 이해-생성 간 bidirectional 부합성을 잠재 공간에서 강제한다. 롤아웃 기반의 경로 평가와 선호 학습은 샘플 간 변동성에 따른 Robustness를 높여, 다양한 입력에 대해 더 안정적인 추론 경로를 확보한다. 실험적으로 Gemini/SigLIP/CLIP 등 다양한 embedding 모델에 대해 일관성 향상을 확인했다. 결과적 의미: LatentUMM은 latent-space에 대한 외부 시그널(고차원 임베딩)을 활용해 잠재 기하학을 재구성하고, 이해-생성 간의 상호 작용을 구조적으로 제약하므로 단일 지표의 개선이 아닌 다중 모달 성능의 균형 향상을 달성한다.
관련 Figure
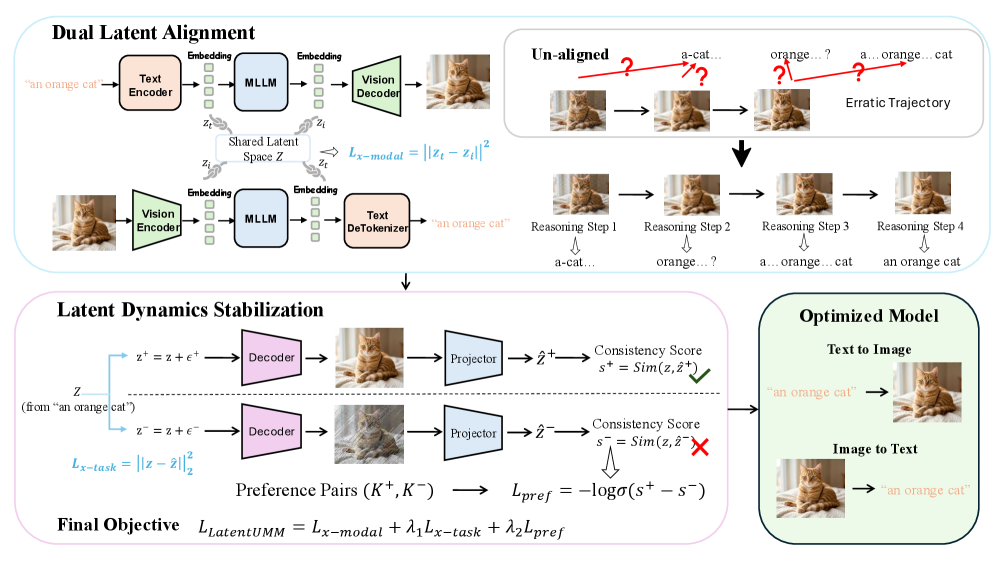
Dual latent alignment가 모달 간 경로를 정렬하기 전후의 차이를 시각적으로 제시한다. Reasoning Step의 경로 차이와 일관성 개선의 연결고리를 제공합니다.
Un-aligned vs Aligned latent trajectories와 Reasoning Step의 흐름을 보여주는 도식
방법론
- 문제 구성: xt와 xi를 입력으로 받아 z = F(zt, zi)로 공유 잠재 공간 Z에 매핑하고, xˆ = G(z)로 재구성한다. 더 강력한 임베딩 모델 E*(·)를 ϕ(·)로 고정 사용해 ϕ(xt)와 ϕ(xi)을 정렬한다. 2) Dual Latent Alignment: Lx-modal = ||ϕ(xt) − ϕ(xi)||^2; z가 주어진 상태에서 zˆ = ϕ(ˆx)로 재인코딩한 뒤 Lx-task = ||z − zˆ||^2를 최소화한다. 3) Latent Dynamics Stabilization: z^(k) = z + ϵ^(k), ϵ^(k) ∼ N(0, σ^2I), k = 1,...,K. 각 경로는 z^(k) → ˆx^(k) = G(z^(k)) → zˆ^(k) = ϕ(ˆx^(k))로 구성되고 Sim(z, zˆ^(k))를 계산한다. Lpref는 L(k+)과 L(k−)의 차이에 대해 −log σ(s^(k+) − s^(k−))로 정의한다. 최종 손실은 LLatentUMM = Lx-modal + λ1 Lx-task + λ2 Lpref 이다. 4) 학습 및 추론: Stage I에서 Dual-capability alignment를 학습하고 Stage II에서 latent dynamics stabilization을 추가한다. 추론 시에는 rollout, 선호 샘플링, 외부 임베딩 계산을 모두 사용하지 않는다. 5) 구현 세부: LoRA 어댑터를 일부 projection 레이어에만 학습시키고, 학습률과 Warmup, gradient clipping 등을 설정한다. Embedding 모델로 Gemini를 기본 사용하고, ablation으로 CLIP/SigLIP도 수행한다. 6) 평가 방식: 2M 텍스트-이미지 데이터에서 생성/이해/ 편집/일관성 벤치마크를 대상으로 비교한다.
관련 Figure
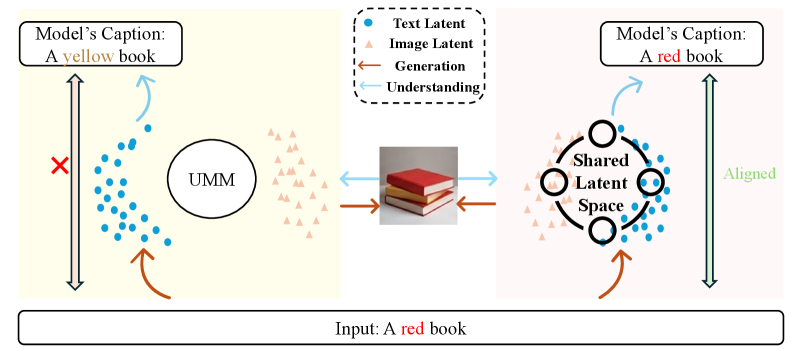
모델의 구조적 흐름과 두 단계 정렬의 연결고리를 시각적으로 보여준다. 텍스트-이미지 인코더/LMM 및 Vision Encoder의 연결과 Shared Latent Space의 위치를 확인할 수 있다.
LatentUMM 아키텍처의 Dual Latent Alignment 및 Shared Latent Space를 요약한 다이어그램
주요 결과
주요 벤치마크에서 LatentUMM이 일관성 및 성능을 일관되게 향상시켰다. 예를 들어, Bagel 백본에서 LatentUMM 도입 시 전반적 점수(Overall)가 71.3에서 73.6으로 상승했고, 1) 생성 벤치마크에서 DPGBench, UEval, WISE의 글로벌/개체/속성/관계 지표가 개선되었다. 특히 DPG-Bench Global은 82.07에서 82.37로, UEval은 90.22에서 91.34로, WISE는 87.82에서 88.88로 증가했다. 2) 편집 벤치마크에서도 원본 대비 Semantic Correctness와 Perceptual Quality가 개선되었다. 3) 백본 일반화: Bagel, Janus-Pro, Harmon 모두 LatentUMM의 이득을 보였고, 예를 들면 Janus-Pro는 Understanding 점수가 40.7에서 41.2로, Harmon은 35.0에서 37.6으로 상승하였다. 4) 일관성 벤치마크(Unification Bench/RealUnify)에서도 LatentUMM이 Baseline 대비 더 높은 점수를 기록했다. 5) 효율성: rollout은 10스텝당 한 번 적용되며, H100에서 10k 샘플 기준 약 20GPU시간(단일 GPU 기준)으로 추정되며, 더 큰 규모의 배포에서도 선형적으로 확장 가능하다. 6) 시각적 사례(E1/E2): LatentUMM은 Baseline보다 시각적 구조의 정합성과 사례별 해석의 일관성을 높였고, 4단계 시퀀스의 순차적 의존성 유지 및 공간 구성의 정확성을 보여준다.
관련 Figure
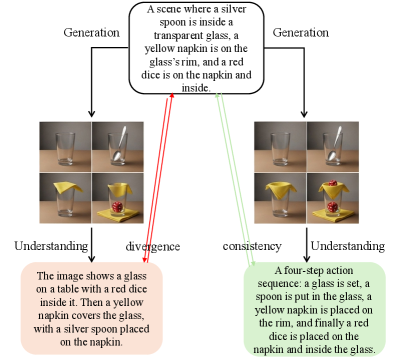
LatentUMM이 Baseline 대비 복수의 프롬프트에서 구조적 피폭 없이 더 일관된 객체 구성과 텍스처를 생성함을 시각적으로 보여준다. 결과의 질적 차이를 뚜렷하게 제시한다.
Baseline과 LatentUMM의 Qualitative 이미지 생성 비교 샘플
기술 상세
아키텍처: modality-specific encoders Et, Ei, a fusion 모듈 F, 디코더 G로 구성된 기본 UMM을 기초로 한다. 외부 임베딩 모델 E*를 고정된 ϕ(x)로 사용해 xt/x i 모두 d 차원의 같은 임베딩 공간에 매핑한다. 손실 함수 Lx-modal은 ∥ϕ(xt) − ϕ(xi)∥^2로 정의되며, Lx-task은 ∥z − zˆ∥^2로 정의되는 bidirectional 정합을 구현한다. Latent Rollouts: z^(k) = z + ε^(k), ε^(k) ∼ N(0, σ^2I); xˆ^(k) = G(z^(k)); zˆ^(k) = ϕ(xˆ^(k)); s^(k) = Sim(z, zˆ^(k)); Lpref = −log σ(s^(k+) − s^(k−)). 최종 목표: LLatentUMM = Lx-modal + λ1 Lx-task + λ2 Lpref. 학습은 두 단계로 진행: Stage I(dual-capability alignment)와 Stage II(latent dynamics stabilization). 추론 시 rollout 및 external embedding은 사용하지 않는다. Rollout 파라미터: K 샘플, σ 노이즈 스케일, r 트리거 주기. 디코딩 전략: self-consistency decoding 등 다양한 기법의 영향 분석. 알고리즘적 차별점: 외부 embedding으로 latent geometry를 강화하고, rollout-based 탐색으로 경로의 안정성을 평가/선택한다. Prior work 대비 차별점: joint optimization만으로는 달성하기 어려운 cross-modal bidirectional 일관성과 latent trajectory의 안정성을 외부 geometric supervisory signal과 확률적 탐색으로 보완한다. 구현 세부: LoRA 어댑터를 사용해 제한된 파라미터만 학습, Gemini(CLIP/SigLIP 포함) 임베딩 비교, rollout 빈도 등 하이퍼파라미터 실험, inference-time에는 추가 처리 없음. 이론적 분석: latent alignment가 모달 간 Semantics를 구조적으로 정합시키고, rollout 기반 신호가 긴 시퀀스에서의 드리프트를 억제하는 방식으로 작동한다.
실무 활용
LatentUMM은 기존 VLM/UMM 기반의 파인튜닝 없이도, 외부 고용량 임베딩 모델(E*)을 활용해 잠재 공간의 구조를 강화하고 롤아웃 기반의 경로 탐색으로 일관성을 높인다. 추론 시간이 증가하지 않으며(추론 시 rollout 비활성화), 기존 백본에 손쉽게 post-training 방식으로 적용 가능하다.
- 다중 모달 추론에서 이해-생성 간 일관성 저하 문제를 완화하기 위한 단일 모델 레이어 업그레이드 없이, LatentUMM의 이중 정렬을 적용해 안정적인 텍스트-이미지 편집 및 재해석 수행
- 생성된 출력을 다시 이해할 때 의미가 보존되도록 하는 대화형 멀티모달 시스템의 신뢰성 향상
- 다양한 백본에 대해 일관성과 생성 품질의 균형을 맞추는 일반화 가능한 후처리(post-training) 전략으로 활용
- 시나리오 기반의 멀티모달 QA/편집 시스템에서 경로 안정성을 요구하는 애플리케이션에서의 활용
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.