TL;DR
긴 비디오 이해에서 도구 호출은 증거를 빠르게 모으는 핵심 방법이지만, 프리트레인 도구 priors가 RL 초기에 포맷 불안정과 도구 탐색의 급진적 증가를 유발한다. ParaVT는 단일 턴에 여러 창을 병렬로 평가하는 구조로 맥락 손실을 줄이고, 프레이밍 문제를 안정화하며, 도구 사용의 실제 가치가 충분히 보상되도록 설계된다. 이로써 긴 비디오 기반 추론에서의 효율성과 정확성을 함께 높인다.
왜 중요한가
긴 비디오 이해에서 도구 호출은 증거를 빠르게 모으는 핵심 방법이지만, 프리트레인 도구 priors가 RL 초기에 포맷 불안정과 도구 탐색의 급진적 증가를 유발한다. ParaVT는 단일 턴에 여러 창을 병렬로 평가하는 구조로 맥락 손실을 줄이고, 프레이밍 문제를 안정화하며, 도구 사용의 실제 가치가 충분히 보상되도록 설계된다. 이로써 긴 비디오 기반 추론에서의 효율성과 정확성을 함께 높인다.
핵심 기여
ParaVT: 병렬 비디오 도구 호출을 위한 RL 프레임워크
하나의 턴에 K개의 병렬 tool_call을 생성하는 메인 에이전트와 K개의 서-에이전트가 각 창을 독립적으로 Grounded 하여 요약을 반환하고, 이 요약들을 합쳐 최종 <answer>를 도출하는 엔드-투-엔드 RL 프레임워크.
Tool Prior Paradox의 식별 및 교차 모델 증거
사전학습된 도구 priors가 포맷 안정성과 도구 탐색 간의 상충을 유발하는 현상을 정의하고, 강한 priors는 포맷 붕괴를 촉진하고 약한 priors는 도구 호출 자체를 억제한다는 교차 모델 증거를 제시한다.
PARA-GRPO: Parseability-Anchored 및 Ratio-Gated GRPO
포맷 안정성과 도구 사용의 보상을 함께 달성하는 알고리즘으로, (i) 구조 토큰의 특정 위치에만 형식 보상(anchor)을 걸고, (ii) 프롬프트별 프레임 예산(nFrames)을 무작위로 바꿔 도구 호출-건Skip 간의 비율 차이를 학습 신호로 활용한다.
Self-curated 데이터 및 RL 파이프라인
SFT: 97K 샘플의 다중 작업 코퍼스, RL: 4,406샘플의 개방형 QA, MCQ, 템포럴 그라운딩 등을 포함한 2단계 학습 파이프라인 구성.
실험적 성과 및 일반화
ParaVT는 여섯 개의 긴 비디오 벤치마크에서 Qwen3-VL-8B 기반의 기본 모델 대비 평균 +7.9% 향상을 달성하고, PARA-GRPO의 학습 시 형식 준수율은 0.13에서 0.64로 증가한다.
코드/데이터 가용성
코드, 데이터, 모델 가중치가 공개 저장소에서 접근 가능하며, GitHub URL은 https://github.com/EvolvingLMMs-Lab/ParaVT 이다.
핵심 아이디어 이해하기
구간별 토큰 포맷이 RL 중에 갑자기 붕괴될 수 있다는 점에서 시작한다. 포맷 토큰은 초기 SFT로 학습되지만, temperature 샘플링 하의 RL 루프에서 pretrained tool_prior에 의해 재현되면서 <tool_call> 같은 고정 포맷이 붕괴될 수 있다. 이 포맷 붕괴는 도구 사용의 신뢰도 하락으로 이어진다. ParaVT는 (1) parseability를 구조 토큰의 특정 위치에서 강하게 고정하고, (2) 프레임 예산을 무작위로 바꿔 도구 사용의 필요성을 학습 신호로 만들며, 이 두 가지를 결합해 포맷 안정성과 도구 탐색 사이의 균형을 회복한다. 실험적으로, cross-model 대조에서 강한 priors은 도구 탐색은 촉진하지만 포맷을 붕괴시키고 약한 priors은 포맷은 안정시키나 도구 사용이 거의 일어나지 않는 경향을 보인다. PARA-GRPO의 Exploration Anchoring은 끝 토큰의 닫힘 여부를 강화하고, nFrames Gating은 프롬프트별 프레임 예산의 무작위화를 통해 도구 사용에 실제 차이를 만든다. 이로써 포맷 안정성과 도구 사용 간의 균형이 재구성되어, 다수의 창으로 구성된 도구 호출이 하나의 턴에서 실질적인 성능 향상을 이끌어낸다.
관련 Figure
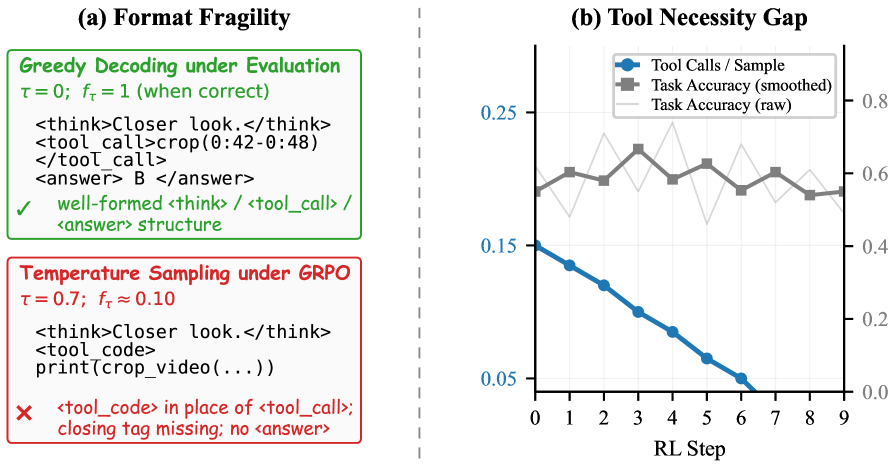
제시된 포맷 붕괴와 도구 필요성의 차이를 시각적으로 보여주며, RL 중 Temperature 샘플링이 포맷 실패를 유발한다는 핵심 주장과 도구 priors의 양면 효과를 설명한다.
Figure 1: Tool Prior Paradox의 두 가지 실패 모드(Format Fragility, Tool Necessity Gap) 개요
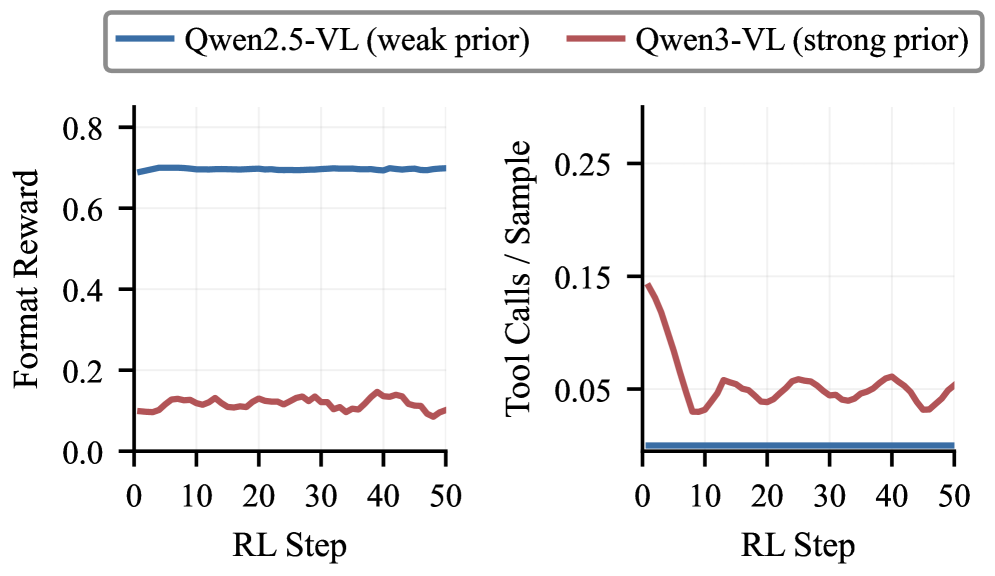
강한 priors는 포맷을 해치고 도구 호출이 증가하는 경향, 약한 priors는 포맷은 안정되나 도구 호출이 거의 없음을 보임. Tool Prior Paradox의 교차 모델 증거를 제공한다.
Figure 2: 두 모델(Qwen2.5-VL, Qwen3-VL)의 도구 priors 차이 및 RL 시나리오에서의 포맷/도구 사용 관계
방법론
아키텍처: 한 턴에 K개의 분리된 window를 각 서-에이전트가 병렬로 crop_video를 호출하고, 각 서-에이전트는 해당 창의 텍스트 요약을 반환한다. 메인 에이전트는 이 K개의 요약을 바탕으로 전체 증거를 합산해 최종 를 생성한다. 이로써 peer-correctable evidence가 형성되고, 프레임 증가는 제로-혹은 상수적이며, 추론 지연은 가장 느린 서브에이전트에 의해서만 결정된다. 학습 프로토콜은 SFT(97K 샘플)로 시작하여 RL(4,406 샘플)로 넘어간다. RL은 GRPO를 사용하며, 포맷 보상과 정확도 보상을 합친 총 보상을 최적화한다. PARA-GRPO는 두 구성요소로 나뉜다. Exploration Anchoring은 구조 토큰의 closing 태그 등에 대해 선택적 보상을 부여하고, Constrained Generation은 Think Prefix와 Answer Suffix를 통해 초기/마지막 구문을 견고하게 만든다. nFrames Gating은 프롬프트별 overview 프레임 수를 {4,8,16,32,64}의 균등분포로 무작위화하여, 일부 프롬프트에서 도구 호출과 건Skip 간의 보상 차이가 생기도록 한다. 보상 구성은 R(x,y) = Racc(y,a*) + λfmt Rfmt(y) + Rtool(y) 형태이며, Rfmt에는 Ranchor를 포함한다. 구현은 8개의 FSDP 작업자와 1개의 SGLang 인퍼런스 노드로 구성된 AReaL 프레임워크를 사용한다. 실험적으로 G=8, τ=0.7, anchor 가중치는 λanchor=0.5이며, sub-agent는 crop_video의 64 프레임까지 처리한다. SFT 데이터는 General Video QA, Long-video Reasoning, Temporal Grounding, Parallel-tool Traces 등을 포함한다.
관련 Figure
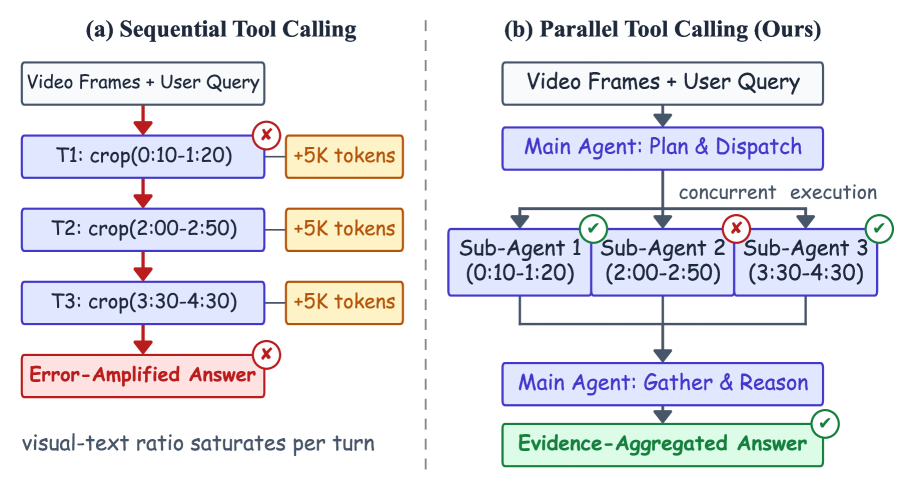
단일 턴에서의 병렬 도구 호출 구조가 브레인스토밍과 증거 수집의 분산화, 오류 투표를 통해 정확도 향상을 가능하게 한다는 점을 시각화한다.
Figure 3: Sequential Tool Calling vs Parallel Tool Calling의 프레임워크 비교
메인 에이전트와 서-에이전트 간 동시 실행 및 최종 증거 응집 과정을 나타내며, parseable한 출력 형식의 중요성을 뒷받침한다.
Figure 3의 병렬 도구 호출 구성의 구체적 구성도
주요 결과
주요 결과: ParaVT는 여섯 개 벤치마크의 비교에서 Open-source 7–8B 대안들 중 상위권 성능을 보였고, Qwen3-VL-8B 기반의 베이스라인 대비 평균 +7.9% 증가를 달성했다. LongVideoBench/ LVBench/ MLVU에서 큰 향상을 보였으며, Charades-STA에서 mIoU가 50.1에 도달했다. Grounding 측면에서 MMVU와 MMVU w/ 자막 비교에서 68.6으로 상향했고, VideoMME에서도 w/o w/ subtitles에서 각각 65.0 및 68.6으로 우수성을 보였다. Ablation 연구에서, 전체 PARA-GRPO를 적용했을 때 학습 시 형식 보상 fτ가 0.64로 상승하고 도구 활용률 κ는 0.21로 유지되었다. Exploration Anchoring 단독은 fτ를 0.35로 올리나 κ는 0.19로 유지, nFrames Gating 단독은 κ를 급격히 증가시키나 fτ는 0.10에 머문다. 두 구성요소를 함께 적용한 경우에만 두 축 모두 안정화되며, dispatch 모드를 Parallel로 유지했을 때도 벤치마크 전반에서 성능이 향상되었다. 학습 다이나믹스 그래프는 GRPO 대비 PARA-GRPO가 형식 보상과 도구 탐색 간의 균형을 달성하는 과정을 보여준다.
관련 Figure
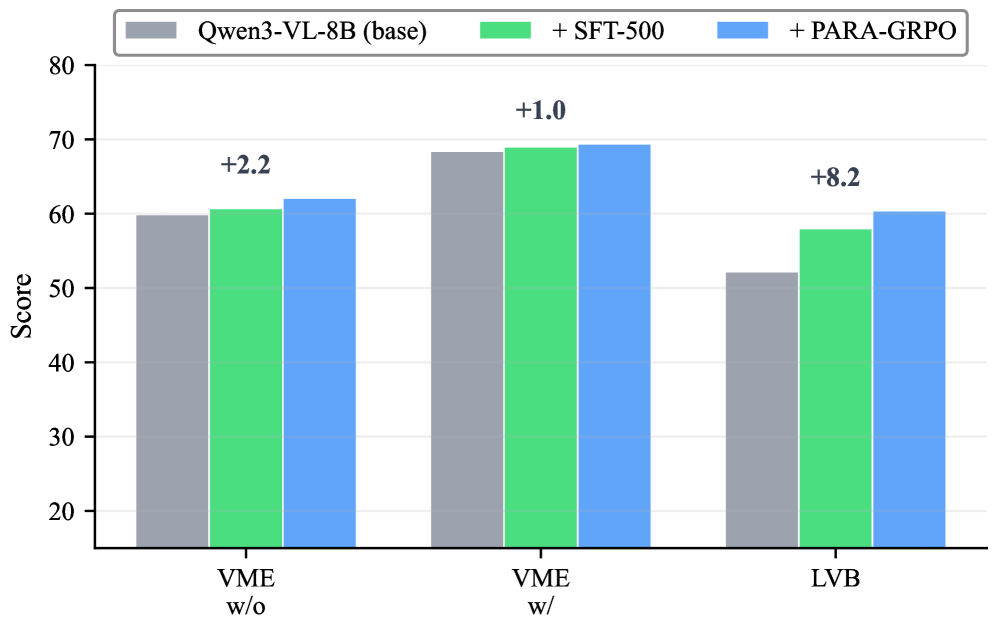
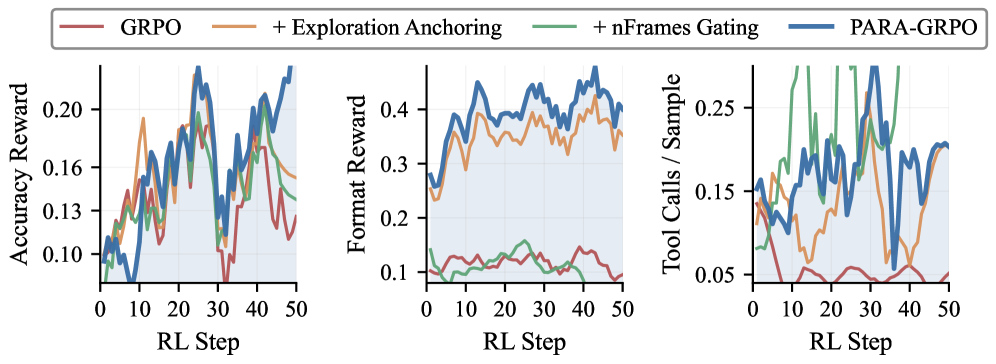
Exploration Anchoring과 nFrames Gating이 각각 형식 보상(fτ)과 도구 호출율(κ)에 미치는 영향을 시각화한다. 전체 조합이 가장 우수한 트레이닝 동작을 보인다.
Figure 4: PARA-GRPO 구성요소별 학습 다이내믹스
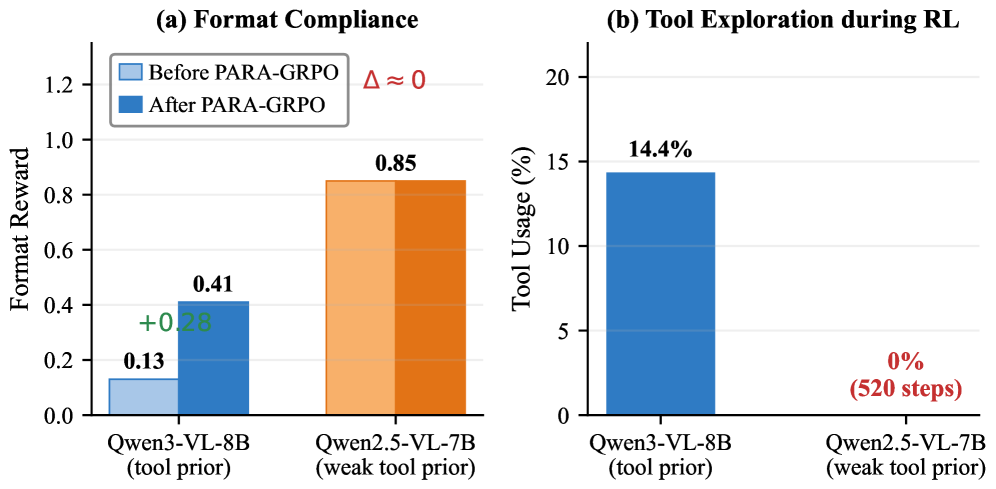
<think>, <tool_call>, <answer> 태그의 봉쇄율을 통해 포맷 안정성을 정량화한다. PARA-GRPO의 도입으로 세 태그의 봉쇄율이 크게 회복된다.
Figure 5: 형식 Fragility의 정량화(세 가지 태그의 봉쇄 비율)
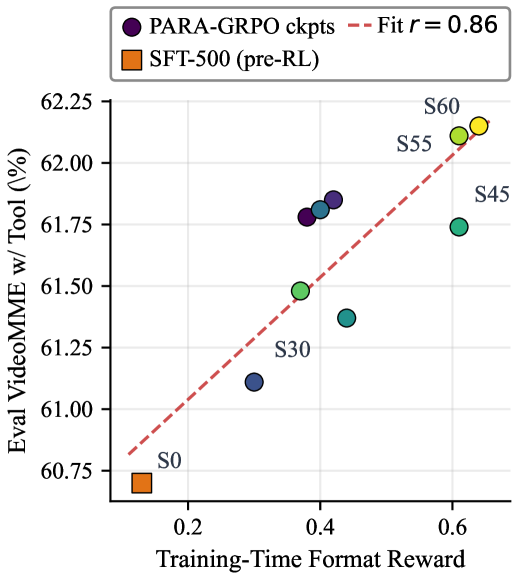
형식 보상(fτ)이 평가 지표와 높은 선형 상관관계를 보임. 이는 RL 시 형식 보상이 실제 성능 향상으로 이어짐을 시사한다.
Figure 6: Training-time 형식 보상과 평가 지표 간의 상관관계
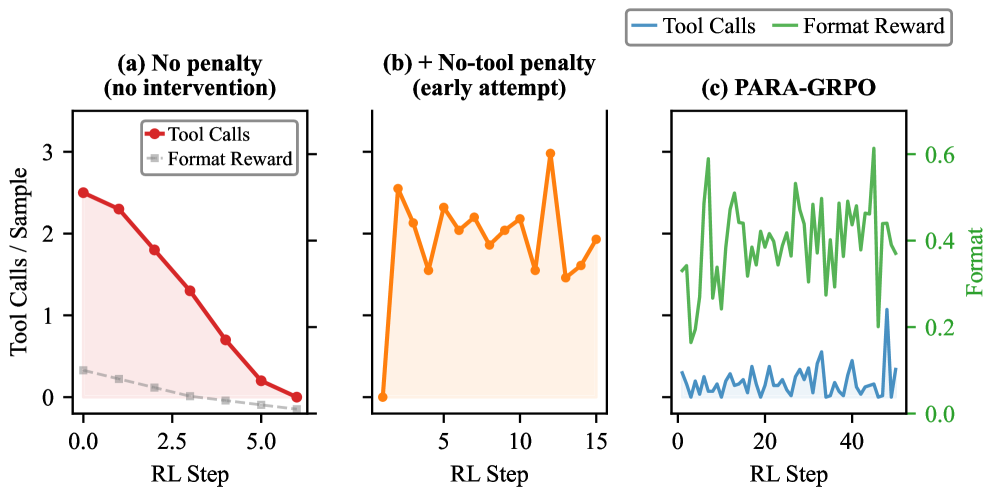
두 모델(Qwen3-VL vs Qwen2.5-VL)에서의 RL 시나리오를 비교하고, 포맷-보상과 도구 사용의 관계를 보여준다.
Figure 7: Two-model trajectory의 도구 사용 현황
기술 상세
아키텍처: 메인 에이전트가 K개의 서-에이전트를 병렬로 배치해 각 창의 crop_video를 실행하고, 각 서-에이전트는 창에 해당하는 텍스트 요약을 반환한다. 학습은 SFT로 시작해 RL GRPO로 진행되며, 보상은 정확도, 형식 준수, 도구 호출의 파싱 가능성의 합으로 구성된다. PARA-GRPO의 구성 요소는 Exploration Anchoring(Think Prefix, Answer Suffix 및 선택적 Ranchor 보상)과 nFrames Gating(프레임 예산의 무작위화)로 나뉜다. 형식 보상은 Rfmt = Rbase + λanchor Ranchor 으로 정규화되며, Ranchor는 의 닫힘 여부, → 흐름의 유지, 의 미종료를 각각 보상/패널티한다. Token-decoupled GRPO 및 Bidirectional tag reversion 실험도 수행되며, Full PARA-GRPO가 형식 안정성과 도구 탐색의 균형을 가장 잘 달성한다. 벤치마크 프로토콜은 64 프레임 적응형으로 구성되며, 각 프롬프트에 대해 G=8 롤아웃을 샘플링한다. 시스템 프롬프트는 SFT 단계에서 tool_call 태그를 사용하며, RL 중에도 동일한 포맷을 유지한다.
실무 활용
도구 내재형 LMM의 RL 학습에서, 병렬 도구 호출 구조와 PARA-GRPO 설계는 툴 priors와 RL 신호 간의 불균형을 완화하고, 긴 비디오 이해에서 효율성과 정확성을 동시에 향상시킨다.
- 장시간 축적 증거가 필요한 스포츠 경기 해설/요약 시스템에 도입
- CCTV 영상 분석에서 다중 창의 증거를 한 턴에 수집하여 신속 판단에 활용
- 의료 영상의 롱폼 분석에서 타임윈도우별 병렬 조회를 통한 진단 보조
- 영상 기반 법의학/감시 데이터 분석 파이프라인에서 도구 호출 비용 관리
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.