이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
아제르바이잔어는 형태학적으로 복잡하여 표준 토크나이저 사용 시 토큰 파편화가 발생하고 컨텍스트 윈도우 효율이 저하된다. 이 프로젝트는 맞춤형 토크나이저를 개발하여 토큰 효율을 2배 개선하고, Liger Kernel과 FSDP를 적용하여 GPU 메모리 사용량을 58% 절감했다. 최종적으로 LoRA를 통해 효율적인 파인튜닝을 수행하여 대화형 모델을 완성했다. 이 접근법은 저자원 언어 모델링에서 학습 처리량과 비용 효율성을 동시에 확보하는 실무 가이드라인을 제공한다.
배경
PyTorch 분산 학습(FSDP)에 대한 이해, Amazon SageMaker AI 사용 경험, LLM 토큰화 및 파인튜닝 개념
대상 독자
저자원 언어 모델링을 수행하거나 LLM 학습 비용 및 성능 최적화에 관심이 있는 AI 엔지니어
의미 / 영향
이 사례는 저자원 언어 모델링에서 토크나이저 최적화와 커널 수준의 메모리 관리가 모델 성능과 비용 효율성에 얼마나 큰 영향을 미치는지 보여준다. 특히 Liger Kernel과 FSDP의 결합은 대규모 모델 학습 시 인프라 비용을 획기적으로 줄일 수 있는 실무적인 표준 패턴을 제시한다.
섹션별 상세
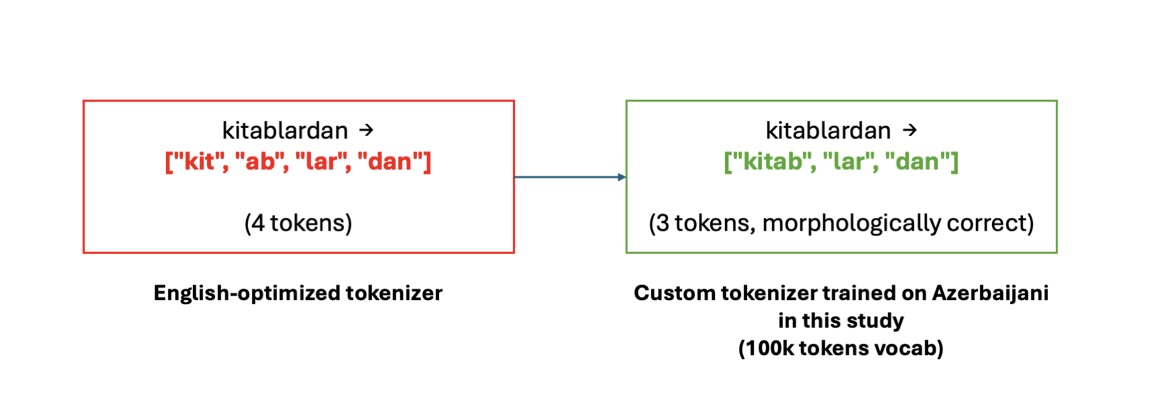
아제르바이잔어는 접미사 활용이 많아 일반적인 영어 최적화 토크나이저로는 토큰이 과도하게 분절된다. 맞춤형 BBPE 토크나이저를 학습시켜 토큰 효율(fertility score)을 3.22에서 1.59로 2배 개선하고, 동일 컨텍스트 윈도우 내 처리 가능한 텍스트 양을 2배로 늘렸다.
근거
- 맞춤형 토크나이저를 통해 토큰 효율(fertility score)을 3.22에서 1.59로 2배 개선했다. — Results and validation 섹션
Llama 3.2 1B 모델의 지속적 사전 학습(CPT) 단계에서 PyTorch FSDP와 Liger Kernel을 통합하여 GPU 메모리 효율을 높였다. Liger Kernel은 여러 연산을 단일 커널로 융합하여 중간 메모리 할당을 줄였으며, 이를 통해 ml.p5.48xlarge 인스턴스에서 처리량을 23% 향상시켰다.
근거
- Liger Kernel을 FSDP와 결합하여 ml.p5.48xlarge 인스턴스에서 GPU 메모리 사용량을 58% 절감하고 처리량을 23% 향상시켰다. — Results and validation 섹션
사전 학습 후 LoRA를 적용하여 모델을 대화형 어시스턴트로 전환했다. 전체 가중치 대신 저순위 분해 행렬만 학습시켜 파라미터 업데이트 비용을 최소화했으며, 2,000개의 질의응답 쌍으로 짧은 시간 내에 효율적인 파인튜닝을 완료했다.
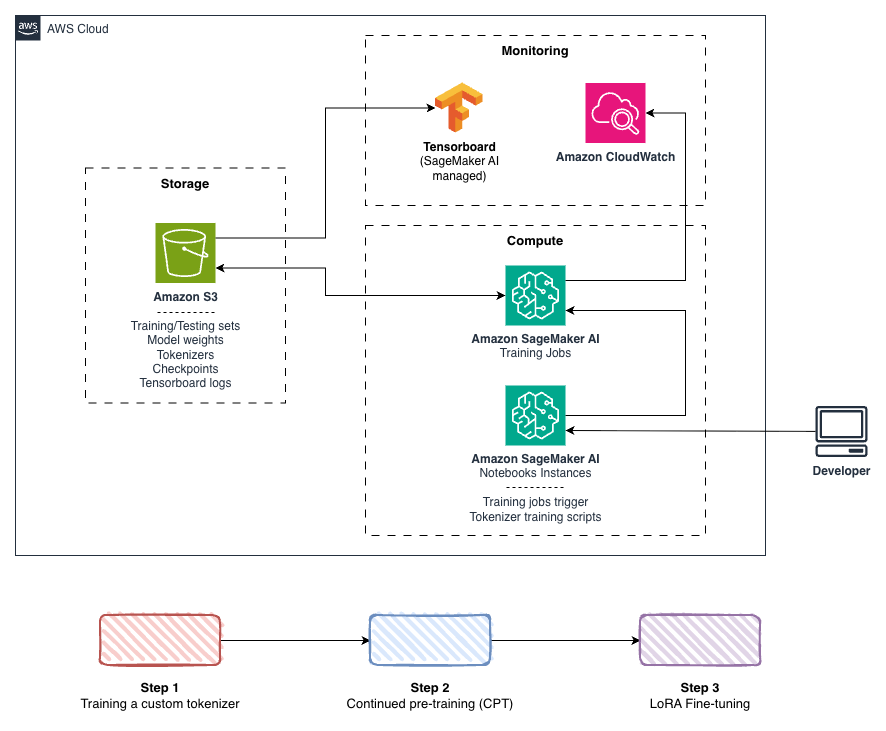
학습 파이프라인은 Amazon SageMaker AI의 관리형 인프라를 기반으로 구축되어 독립적인 단계별 최적화가 가능하다. 각 단계는 S3에 아티팩트를 저장하고 TensorBoard로 메트릭을 추적하며, 필요 시에만 인스턴스를 프로비저닝하여 유휴 비용을 제거했다.
용어 해설
- Liger Kernels
- — LLM의 핵심 연산을 융합하여 GPU 메모리 사용량을 줄이고 처리량을 높이는 Triton 기반의 최적화된 커널 구현체입니다. 표준 연산보다 메모리 효율이 뛰어나 대규모 모델 학습 시 병목을 완화합니다.
- FSDP
- — 모델의 파라미터, 그래디언트, 옵티마이저 상태를 여러 GPU에 분산 저장하여 메모리 부족 문제를 해결하는 분산 학습 기법입니다. 대규모 모델을 단일 GPU 메모리 한계를 넘어 학습할 수 있게 합니다.
- Fertility Score
- — 단어당 평균 토큰 수를 나타내는 지표입니다. 점수가 낮을수록 토크나이저가 해당 언어를 더 효율적으로 인코딩하여 컨텍스트 윈도우를 경제적으로 사용함을 의미합니다.
- Byte-Pair Encoding
- — 가장 빈번하게 등장하는 바이트 쌍을 반복적으로 병합하여 어휘 사전을 구축하는 알고리즘입니다. 언어 특성에 맞는 맞춤형 토크나이저를 학습시킬 때 주로 사용됩니다.
- Continued Pre-training
- — 이미 사전 학습된 모델을 새로운 데이터셋으로 추가 학습시켜 특정 언어, 도메인, 또는 문화적 맥락에 적응시키는 과정입니다. 모델의 기본 지식을 유지하면서 새로운 지식을 습득하게 합니다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 29.수집 2026. 05. 29.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.