이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
LinkedIn은 기존 CPU 기반의 선형 계획법(LP) 솔버인 DuaLip을 PyTorch 기반의 GPU 가속 시스템으로 재설계했다. 이 시스템은 대규모 웹 애플리케이션의 의사결정 문제를 해결하기 위해 희소 행렬 연산과 블록 단위 투영을 GPU에서 병렬 처리한다. 기존 Scala/Spark 스택 대비 반복당 처리 시간을 75배 단축했으며, 다중 GPU 환경에서 선형적인 확장성을 확보했다. 이 전환을 통해 엔지니어링 오버헤드를 줄이고 복잡한 비즈니스 최적화 문제를 실시간으로 처리할 수 있게 됐다.
배경
선형 계획법(Linear Programming) 기초, 분산 컴퓨팅 및 GPU 가속 개념, PyTorch 텐서 연산 및 NCCL 통신 이해
대상 독자
대규모 최적화 시스템을 구축하는 엔지니어 및 AI 인프라 개발자
의미 / 영향
이 사례는 PyTorch가 딥러닝을 넘어 범용적인 대규모 수치 최적화 및 선형 계획법 문제 해결을 위한 고성능 엔진으로 활용될 수 있음을 보여준다. GPU 가속을 통한 최적화 솔버의 재설계는 기존 CPU 기반 시스템의 한계를 극복하고 실시간 비즈니스 의사결정의 규모를 확장하는 핵심 전략이 될 수 있다.
섹션별 상세
기존 CPU 기반 DuaLip 솔버는 대규모 데이터셋 처리 시 행렬 분해와 basis 업데이트 연산의 메모리 및 계산 비용으로 인해 확장성에 한계가 있었다.
DuaLip-PyTorch는 PyTorch의 텐서 연산과 GPU 가속을 활용해 희소 행렬-벡터 곱셈과 투영 연산을 최적화하여 연산 병목을 해소했다.
변수를 GPU 간에 분할하고 NCCL all-reduce를 통해 듀얼 변수를 동기화하여 다중 GPU 환경에서 효율적인 분산 처리를 구현했다.
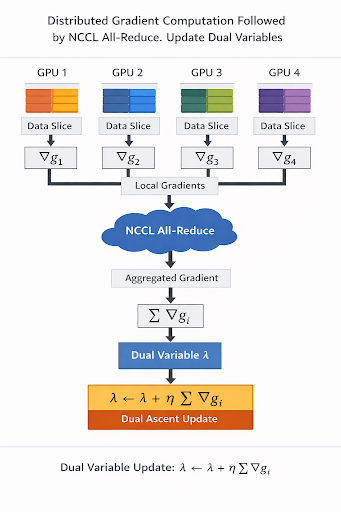
실험 결과, 기존 Scala/Spark 구현체 대비 반복당 처리 시간이 75배 단축되었으며, GPU 개수에 비례하는 선형적인 속도 향상을 기록했다.


기술
- PyTorch
- DuaLip
- NCCL
- Scala
- Spark
활용 사례
- 대규모 비즈니스 지표 최적화
- 광고 및 콘텐츠 랭킹 시스템
- 분산 선형 계획법 솔버
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 01.수집 2026. 06. 02.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.