이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
LLM 배포 시 모델 로딩 시간은 GPU 유휴 시간을 발생시켜 콜드 스타트 지연과 비용 비효율을 초래한다. Amazon FSx for Lustre와 NVIDIA GPUDirect Storage(GDS)를 결합하여 CPU를 거치지 않고 스토리지에서 GPU HBM으로 데이터를 직접 전송하는 병렬 로딩 방식을 구현한다. Llama 3.1 405B 모델 기준 로딩 시간을 기존 18분에서 6.4초로 단축했다. TurboQuant KV 캐시 압축 기술을 병행하여 동일 하드웨어에서 컨텍스트 윈도우를 5배 확장한다.
배경
AWS P5en/P6 인스턴스, Amazon FSx for Lustre, NVIDIA GDS 설정
대상 독자
프로덕션 환경에서 대규모 LLM을 배포하고 운영하는 엔지니어
의미 / 영향
이 기술은 대규모 LLM의 콜드 스타트 문제를 해결하여 실시간 서비스의 가용성을 높인다. 또한 메모리 효율을 극대화하여 더 긴 컨텍스트 처리를 가능하게 함으로써 LLM 서비스의 경제성을 개선한다.
섹션별 상세
기존 CPU 기반 모델 로딩은 체크포인트를 CPU 메모리로 읽고 직렬로 GPU에 복사하는 과정에서 병목이 발생한다.
bash
lfs setstripe -c -1 -S 16M /fsx/model_shards/Llama-3.1-405B-FP8-8wayFSx for Lustre 출력 디렉토리에 모든 OST를 활용하도록 스트라이핑을 설정하는 명령어이다.
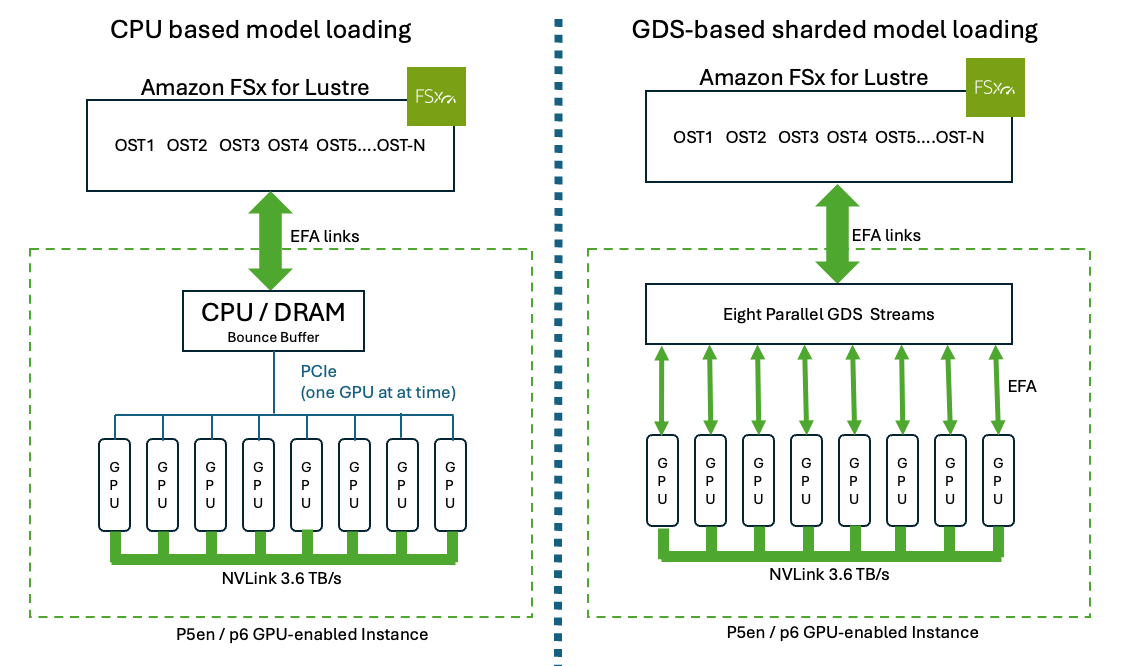
GDS를 활용한 병렬 로딩은 Amazon FSx for Lustre의 데이터를 EFA를 통해 GPU HBM으로 직접 전송하여 CPU와 PCIe 버스 병목을 제거한다.
python
loader = SafeTensorsFileLoader(pg=None, device=f"cuda:{rank}", nogds=False)
fbuf = loader.copy_files_to_device()fastsafetensors 라이브러리를 사용하여 GDS를 통해 데이터를 GPU 메모리로 직접 로드하는 코드이다.
모델을 FP8로 사전 양자화하고 텐서 병렬(TP) 단위로 미리 분할하여 저장하면 로딩 시 직렬화 및 변환 과정을 생략할 수 있다.
Llama 3.1 405B 모델 테스트 결과, 표준 로딩 대비 169배 빠른 6.4초의 로딩 속도를 달성했다.
근거
- Llama 3.1 405B 모델 로딩 시간이 18분에서 6.4초로 단축됐다. — The performance difference 섹션의 Llama 3.1 405B Instruct 결과 표
TurboQuant를 통한 KV 캐시 압축은 HBM 사용량을 줄여 P5en 인스턴스 기준 컨텍스트 윈도우를 82K에서 400K 이상으로 5배 확장한다.
근거
- TurboQuant KV 캐시 압축으로 컨텍스트 윈도우가 5배 확장된다. — P5en (8x H200) 및 P6 node (8x B200) 성능 비교 표
용어 해설
- NVIDIA GPUDirect Storage
- — 스토리지와 GPU 메모리 간의 직접적인 데이터 전송을 가능하게 하는 기술이다. CPU와 시스템 메모리를 거치지 않아 데이터 복사 오버헤드를 제거하고 처리량을 극대화한다.
- KV Cache
- — LLM 추론 시 이전 토큰의 키(Key)와 값(Value) 상태를 저장하여 중복 계산을 방지하는 메모리 영역이다. 컨텍스트 길이가 길어질수록 메모리 점유율이 급격히 증가한다.
- Tensor Parallelism
- — 단일 모델의 가중치 행렬을 여러 GPU에 나누어 배치하여 연산을 분산 처리하는 기법이다. 단일 GPU 메모리에 담기 힘든 대규모 모델을 추론할 때 필수적이다.
- TurboQuant
- — KV 캐시를 약 3비트로 압축하여 메모리 사용량을 줄이는 기술이다. 정확도 손실 없이 컨텍스트 윈도우를 확장하고 추론 속도를 개선한다.
- Amazon FSx for Lustre
- — 고성능 컴퓨팅 워크로드를 위해 설계된 관리형 병렬 파일 시스템이다. 대규모 데이터 처리와 빠른 I/O 성능을 제공한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 02.수집 2026. 06. 02.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.
