이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
LLM의 구조화된 데이터 추출 작업에서 발생하는 텍스트 퇴화(반복 루프)는 SFT만으로는 해결하기 어려운 구조적 한계가 존재함. DharmaOCR은 SFT 모델이 생성한 퇴화 출력을 필터링하지 않고 DPO의 '거부(rejected)' 예시로 활용하여 모델이 퇴화 패턴을 회피하도록 학습함. 이 접근법은 5개 모델 패밀리에서 평균 59.4%의 퇴화 감소 효과를 보였으며, 모델의 추출 성능을 유지하면서도 안정성을 높임. 이 방법론은 퇴화가 범주적으로 식별 가능하고 자동 평가가 가능한 구조화된 작업에서 효과적인 학습 신호로 작용함.
대상 독자
구조화된 데이터 추출 파이프라인을 구축하는 LLM 엔지니어
의미 / 영향
이 방법론은 모델의 실패 사례를 데이터 정제 과정에서 버리지 않고 학습 신호로 전환하여 모델의 안정성을 높이는 실용적인 접근법을 제시함. 특히 인간 피드백 데이터가 부족한 전문 도메인에서 DPO를 효과적으로 활용할 수 있는 구조를 제공함.
섹션별 상세
SFT는 도메인 적응에는 효과적이지만, 토큰 단위 학습 특성상 문장 수준의 반복 루프인 텍스트 퇴화를 직접적으로 억제하지 못함.
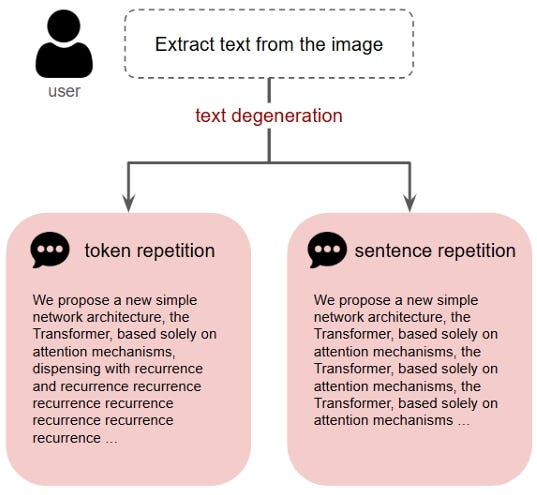
DharmaOCR 파이프라인은 SFT 모델이 생성한 퇴화 출력을 데이터셋에서 제거하지 않고, 오히려 DPO 학습을 위한 '거부(rejected)' 예시로 의도적으로 보존함.
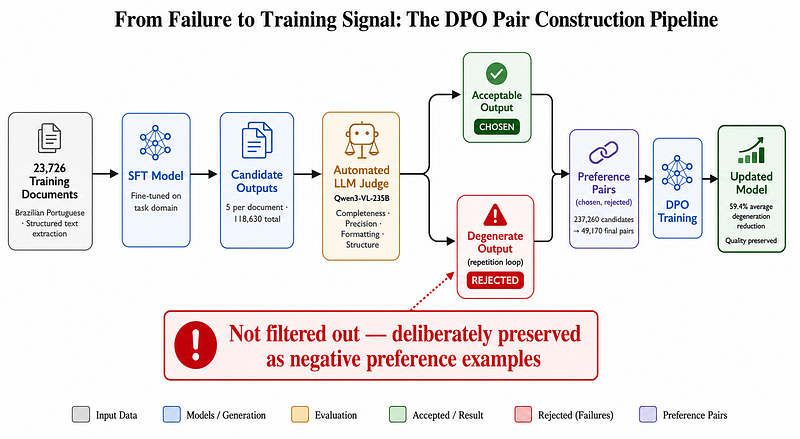
DPO는 전체 출력을 평가하여 퇴화 패턴을 명시적으로 학습에서 배제함으로써, SFT가 해결하지 못한 분포 공간의 퇴화 유인(attractor)을 효과적으로 제거함.
5개 모델 패밀리 대상 실험 결과, DPO 적용 후 텍스트 퇴화율이 평균 59.4% 감소했으며, 최대 87.6%까지 개선되는 등 일관된 성능 향상을 보임.
기술
- DPO
- SFT
- DharmaOCR
활용 사례
- 구조화된 문서 추출
- OCR 파이프라인
- LLM 출력 안정화
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 03.수집 2026. 06. 03.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.