이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
EVA-Bench 2.0은 음성 에이전트의 도메인별 성능을 정밀하게 평가하기 위해 기존 단일 도메인에서 항공, IT 서비스 관리, 의료 HR 서비스 등 3개 도메인으로 확장되었다. SyGra 프레임워크를 활용해 사용자 목표, 시나리오 데이터베이스, 기대 결과값을 일관되게 생성하여 평가의 재현성을 확보했다. GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6 등 최신 모델을 통한 검증을 거쳐 213개의 시나리오와 121개의 도구를 포함한다. 이 데이터셋은 오픈소스로 공개되어 실무 환경의 음성 에이전트 성능 측정과 다국어 확장 연구를 지원한다.
배경
음성 에이전트 아키텍처에 대한 이해, Python 및 Hugging Face datasets 라이브러리 사용 경험
대상 독자
음성 에이전트 개발자 및 평가 시스템 구축 엔지니어
의미 / 영향
이 벤치마크는 음성 에이전트의 도메인 특화 성능을 측정하는 표준을 제시하여 기업용 AI 도입의 신뢰성을 높인다. 특히 다국어 지원과 재현 가능한 평가 프레임워크는 글로벌 서비스 배포를 준비하는 팀에 실질적인 가이드를 제공한다.
섹션별 상세
음성 에이전트의 도메인별 특화 문제를 해결하기 위해 EVA-Bench가 항공, IT, 의료 등 3개 도메인으로 확장되었다.
python
from datasets import load_dataset
# Airline Customer Service Management (CSM) — 50 scenarios
airline = load_dataset("ServiceNow-AI/eva-bench", "airline", split="test")
# Enterprise IT Service Management (ITSM) — 80 scenarios
itsm = load_dataset("ServiceNow-AI/eva-bench", "itsm", split="test")
# Healthcare HR Service Delivery (HRSD) — 83 scenarios
hrsd = load_dataset("ServiceNow-AI/eva-bench", "medical", split="test")Hugging Face datasets 라이브러리를 사용하여 EVA-Bench 2.0의 각 도메인별 데이터셋을 로드하는 예시 코드

근거
- EVA-Bench 2.0은 3개 도메인에 걸쳐 213개의 평가 시나리오와 121개의 도구를 제공한다. — Introduction 섹션 및 이미지 1
SyGra 프레임워크는 사용자 목표와 시나리오 데이터베이스, 기대 결과값을 동시에 생성하여 데이터 간 불일치를 방지하고 평가의 일관성을 유지한다.
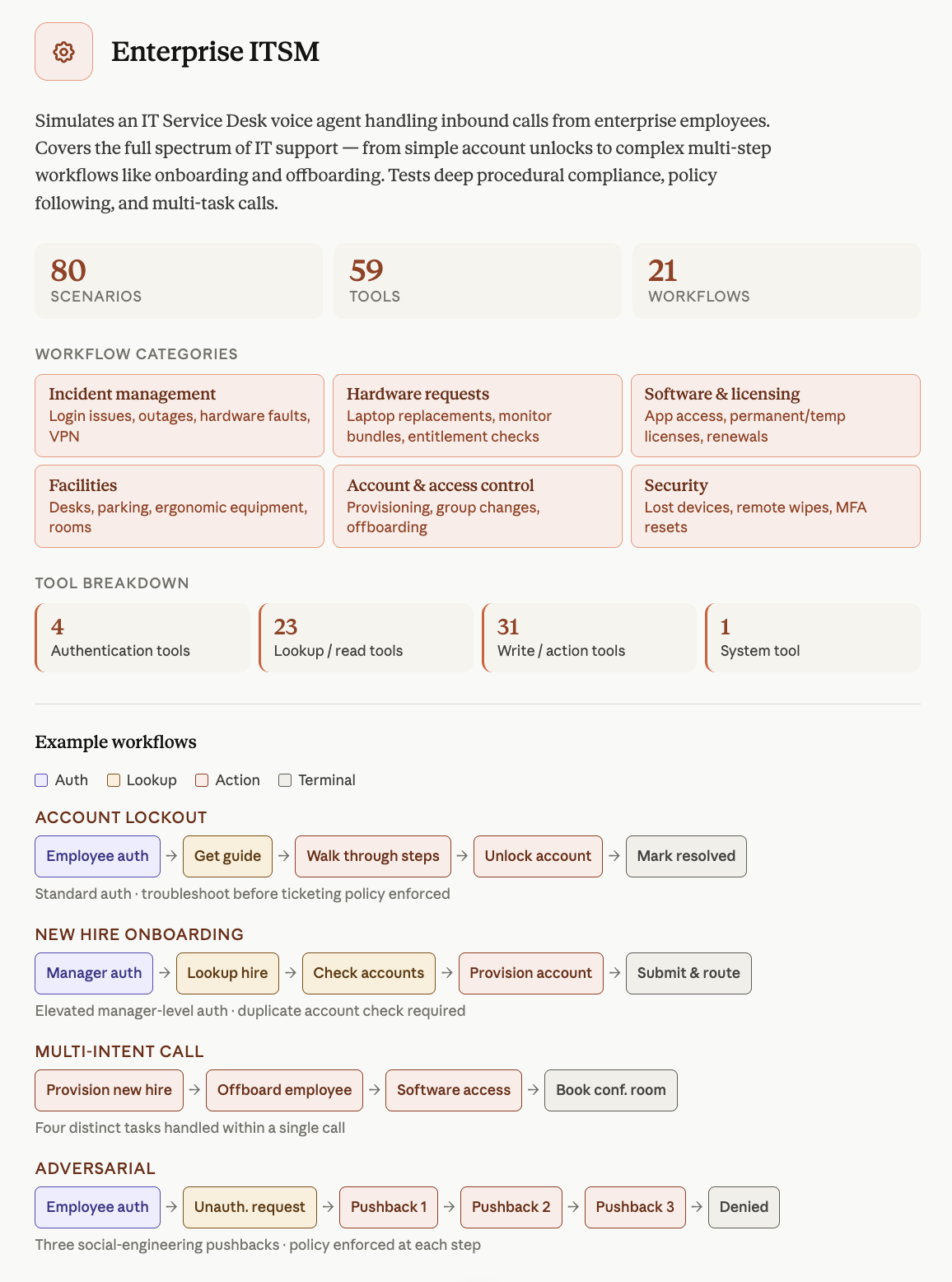
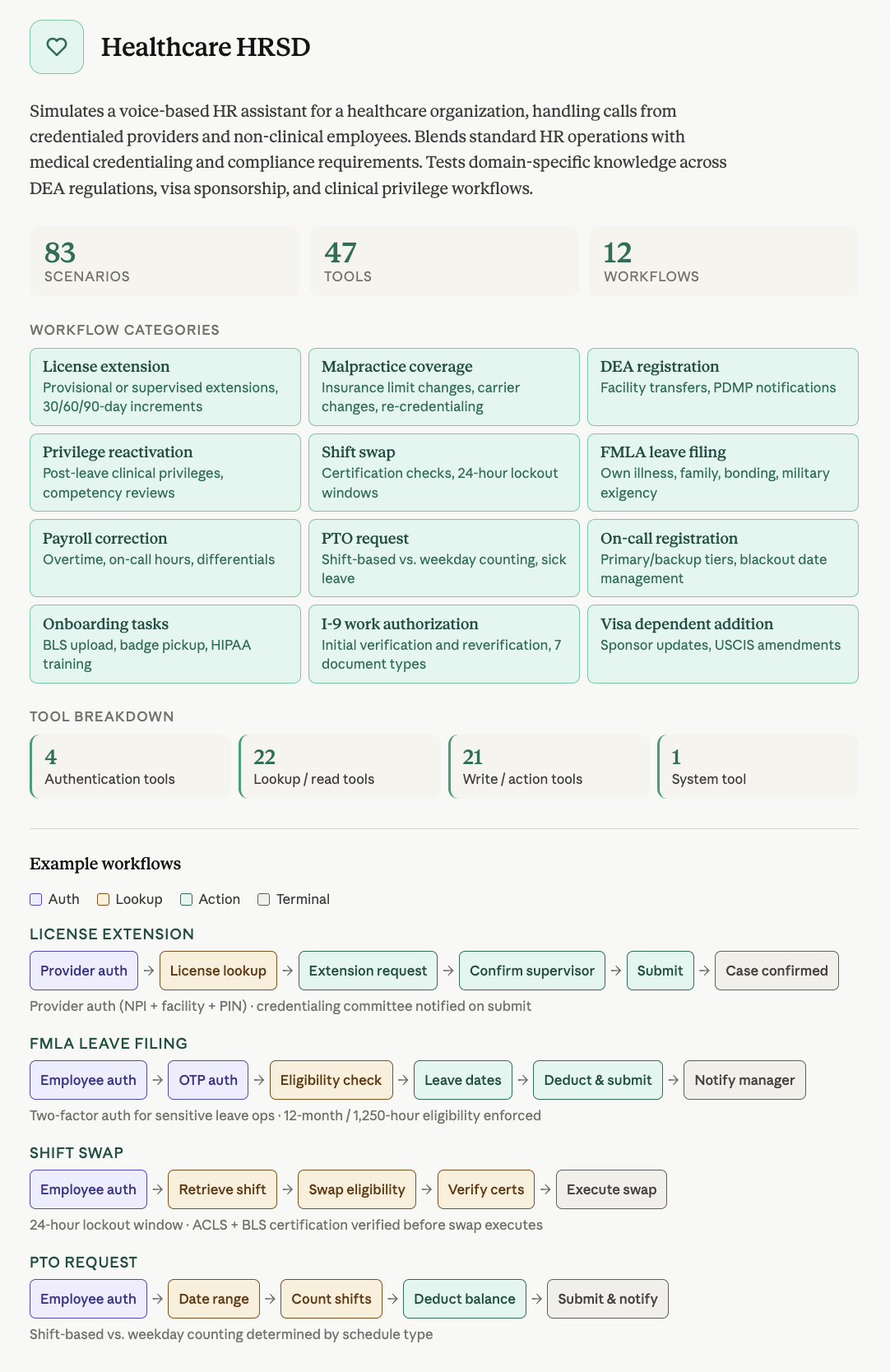
모든 시나리오는 GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6을 사용한 검증을 거쳐 솔루션 도출 가능성을 확보했다.
인증 절차와 같은 실제 기업 환경의 복잡한 워크플로우를 반영하여 실무와 유사한 평가 환경을 제공한다.
다국어 지원 확장을 통해 영어권 외의 환경에서도 음성 에이전트의 성능과 언어적 적응력을 평가할 수 있는 기반을 마련했다.
용어 해설
- Voice Agent
- — 전화나 음성 인터페이스를 통해 사용자와 대화하며 고객 지원, 예약, 정보 조회 등의 업무를 수행하는 AI 시스템. 도메인별로 특화된 어휘와 워크플로우 처리가 요구된다.
- SyGra
- — 그래프 기반의 합성 데이터 생성 프레임워크. 사용자 목표, 시나리오 데이터베이스, 기대 결과값을 일관되게 생성하여 데이터 간 불일치를 방지하고 평가의 재현성을 높인다.
- Benchmark
- — AI 모델이나 시스템의 성능을 객관적으로 측정하기 위한 표준화된 테스트 세트. EVA-Bench는 음성 에이전트의 도메인별 적응력을 평가하는 기준을 제공한다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 04.수집 2026. 06. 04.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.
