이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
NVIDIA Nemotron 3 Ultra 모델이 Amazon SageMaker JumpStart에 추가되어 원클릭 배포를 지원한다. 이 모델은 550B 파라미터 규모의 하이브리드 Transformer-Mamba MoE 아키텍처를 기반으로 하며, 55B 활성 파라미터를 사용한다. 기존 모델 대비 추론 속도가 5배 빠르고 에이전트 워크로드 비용을 최대 30% 절감한다. 최대 1M 토큰의 컨텍스트 길이를 지원하여 복잡한 다단계 추론과 에이전트 오케스트레이션에 최적화됐다.
배경
AWS 계정, SageMaker JumpStart 권한, ml.p5en.48xlarge 등 적절한 GPU 인스턴스 서비스 할당량
대상 독자
프로덕션 환경에서 에이전트 워크로드 및 대규모 추론을 수행하는 AI 엔지니어
의미 / 영향
이 모델은 에이전트 워크로드에 특화된 아키텍처를 통해 추론 비용과 속도 문제를 해결한다. 기업은 복잡한 다단계 추론 작업을 더 경제적으로 자동화할 수 있다.
섹션별 상세
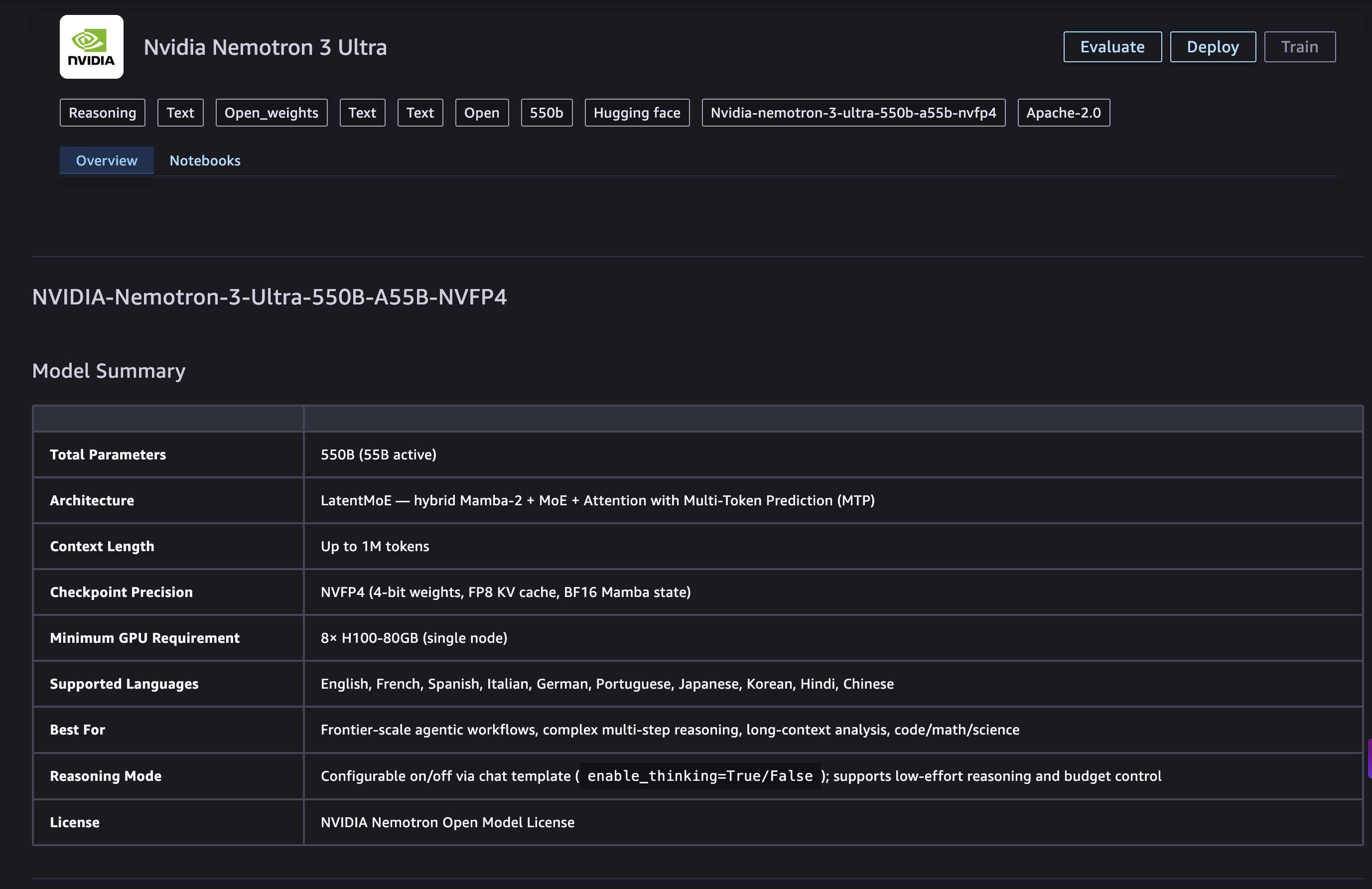
550B 파라미터 중 55B만 활성화하는 하이브리드 Transformer-Mamba MoE 구조를 채택하여 연산 효율성을 높였다.
근거
- Nemotron 3 Ultra는 550B 총 파라미터 중 55B만 활성화하는 하이브리드 Transformer-Mamba MoE 아키텍처를 사용한다. — Model Summary 섹션
에이전트 워크로드에서 기존 모델 대비 5배 빠른 추론 속도와 30% 낮은 비용을 제공한다.
근거
- 에이전트 워크로드에서 5배 빠른 추론 속도와 최대 30% 낮은 비용을 제공한다. — Model Summary 섹션
1M 토큰의 긴 컨텍스트 윈도우를 지원하여 에이전트의 계획 수립, 도구 호출, 자기 수정 루프를 안정적으로 유지한다.
SageMaker JumpStart를 통해 인프라 구성 없이 원클릭으로 배포하거나 Python SDK로 즉시 연동 가능하다.
용어 해설
- Mixture-of-Experts
- — 전체 파라미터 중 입력 데이터에 따라 필요한 일부 전문가 네트워크만 활성화하는 아키텍처. 모델의 총 파라미터 수는 크지만 실제 연산 시에는 적은 수의 파라미터만 사용하여 추론 속도와 효율성을 높인다.
- Mamba
- — 선형 시간 복잡도를 가지는 상태 공간 모델(SSM) 아키텍처. 긴 시퀀스 데이터 처리 시 Transformer의 이차 복잡도 문제를 해결하여 효율적인 컨텍스트 처리를 가능하게 한다.
- Agentic Workload
- — AI 에이전트가 계획 수립, 도구 호출, 하위 에이전트 위임, 결과 검증 등을 반복하며 다단계 추론을 수행하는 작업. 긴 컨텍스트 유지와 높은 추론 신뢰성이 요구된다.
- NVFP4
- — NVIDIA에서 최적화한 모델 가중치 및 KV 캐시 정밀도 포맷. 4비트 가중치와 FP8 KV 캐시를 사용하여 모델 호스팅 비용을 낮추고 추론 속도를 가속화한다.
코드 예제
python
import sagemaker
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(
model_id="huggingface-reasoning-nvidia-nemotron-3-ultra-550b-a55b-nvfp4",
role=sagemaker.get_execution_role(),
)
predictor = model.deploy(accept_eula=True)SageMaker Python SDK를 사용하여 Nemotron 3 Ultra 모델을 배포하는 코드
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 05.수집 2026. 06. 05.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.