이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
AI 에이전트는 복잡한 도구 호출과 다단계 추론을 수행하므로 단순 출력 확인만으로는 내부 오류를 파악하기 어렵다. Agent-EvalKit은 Claude Code 등 AI 코딩 어시스턴트와 통합되어 에이전트의 전체 실행 경로를 추적하고, 도구 호출과 응답의 일치성을 평가한다. 이 툴킷은 계획, 데이터 생성, 추적, 실행, 평가, 보고의 6단계 워크플로를 통해 환각 등 잠재적 실패 모드를 식별한다. 여행 연구 에이전트 사례에서 응답 품질은 높았으나 사실 충실도(faithfulness)가 32.3%에 불과함이 확인되었고, 이를 통해 구체적인 코드 수정안이 도출되었다.
배경
AWS 계정 (Amazon Bedrock), Python 3.11 이상, uv 패키지 매니저, AI 코딩 어시스턴트 (Claude Code 등)
대상 독자
AI 에이전트를 개발하고 프로덕션에 배포하려는 개발자
의미 / 영향
에이전트 평가를 개발 워크플로에 내재화하여 환각과 같은 신뢰성 문제를 코드 수준에서 해결할 수 있게 한다. 이는 에이전트의 프로덕션 준비 상태를 높이는 필수적인 과정이다.
섹션별 상세
에이전트의 자율적인 도구 선택과 순차적 작업은 단순 출력 기반 테스트로는 내부의 환각이나 검증 누락을 감지하기 어렵다.
Agent-EvalKit은 Claude Code와 같은 AI 코딩 어시스턴트 내에서 직접 동작하며, 에이전트의 소스 코드와 시스템 프롬프트를 분석하여 평가 계획을 수립한다.
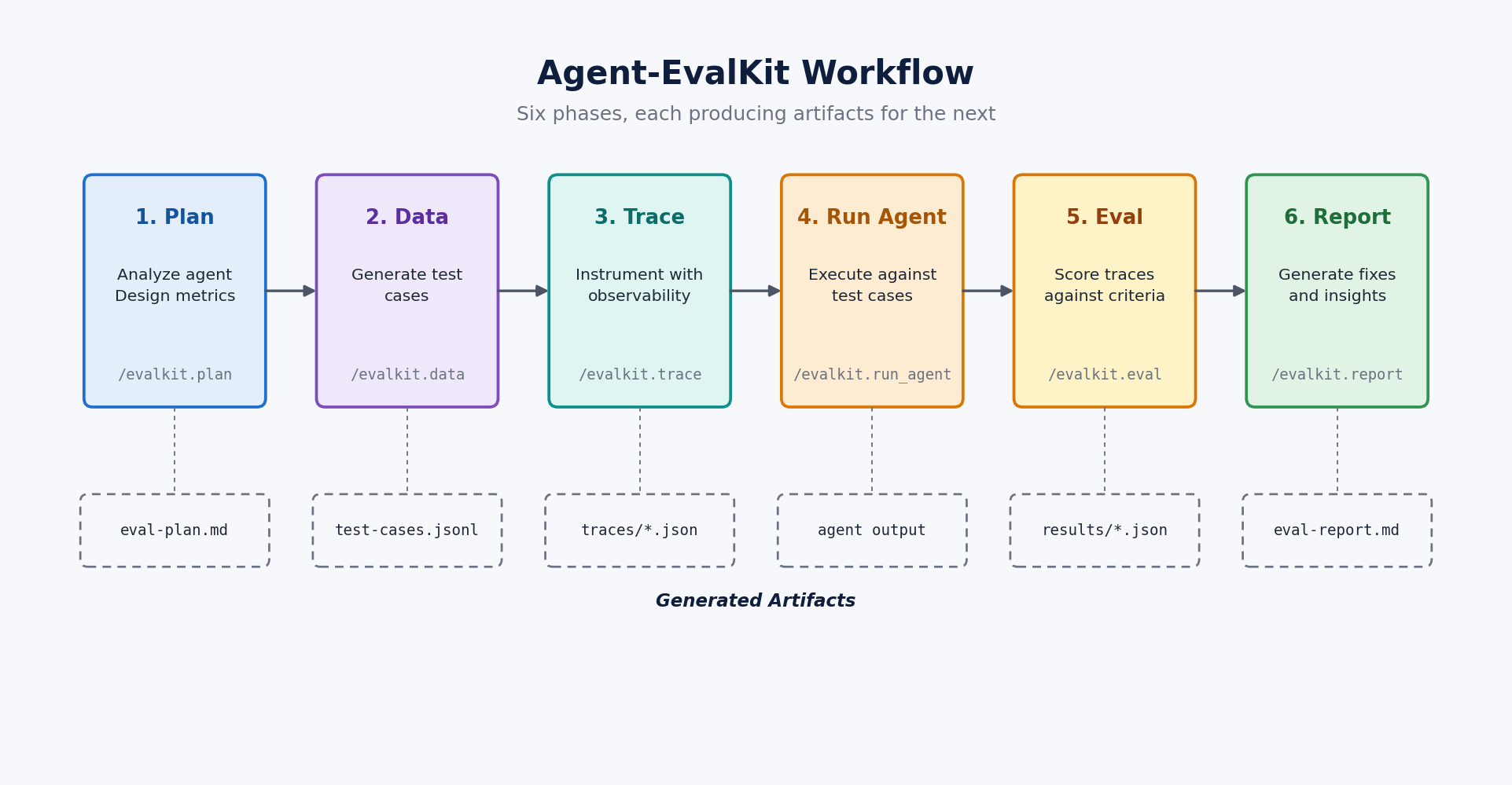
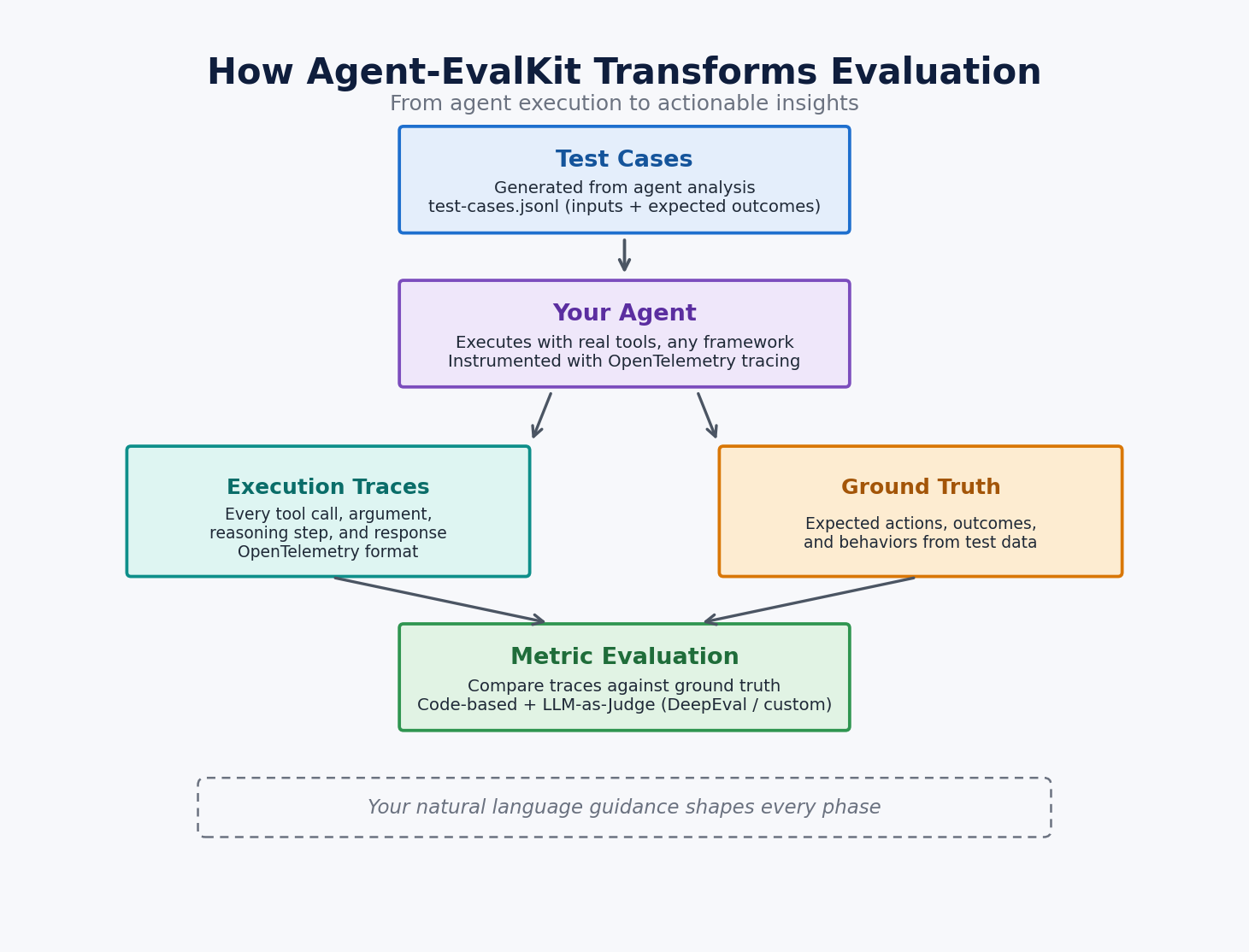
6단계 워크플로(Plan, Data, Trace, Run, Eval, Report)를 통해 OpenTelemetry 기반의 실행 추적과 LLM-as-judge 평가를 수행한다.

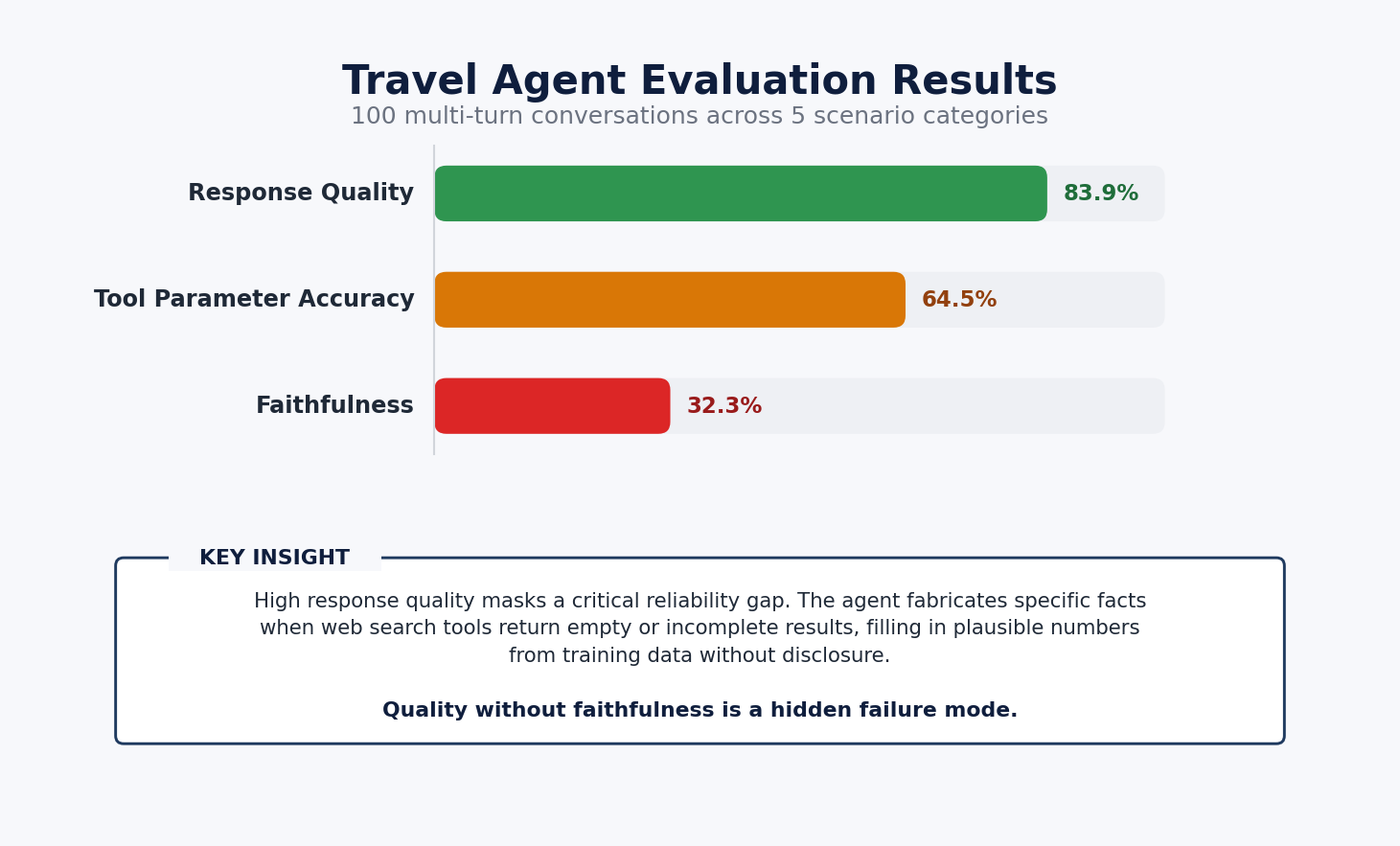
여행 연구 에이전트 테스트 결과, 응답 품질은 83.9%로 높았으나 도구 결과가 없을 때 사실을 조작하는 환각 현상으로 인해 충실도 점수는 32.3%에 그쳤다.
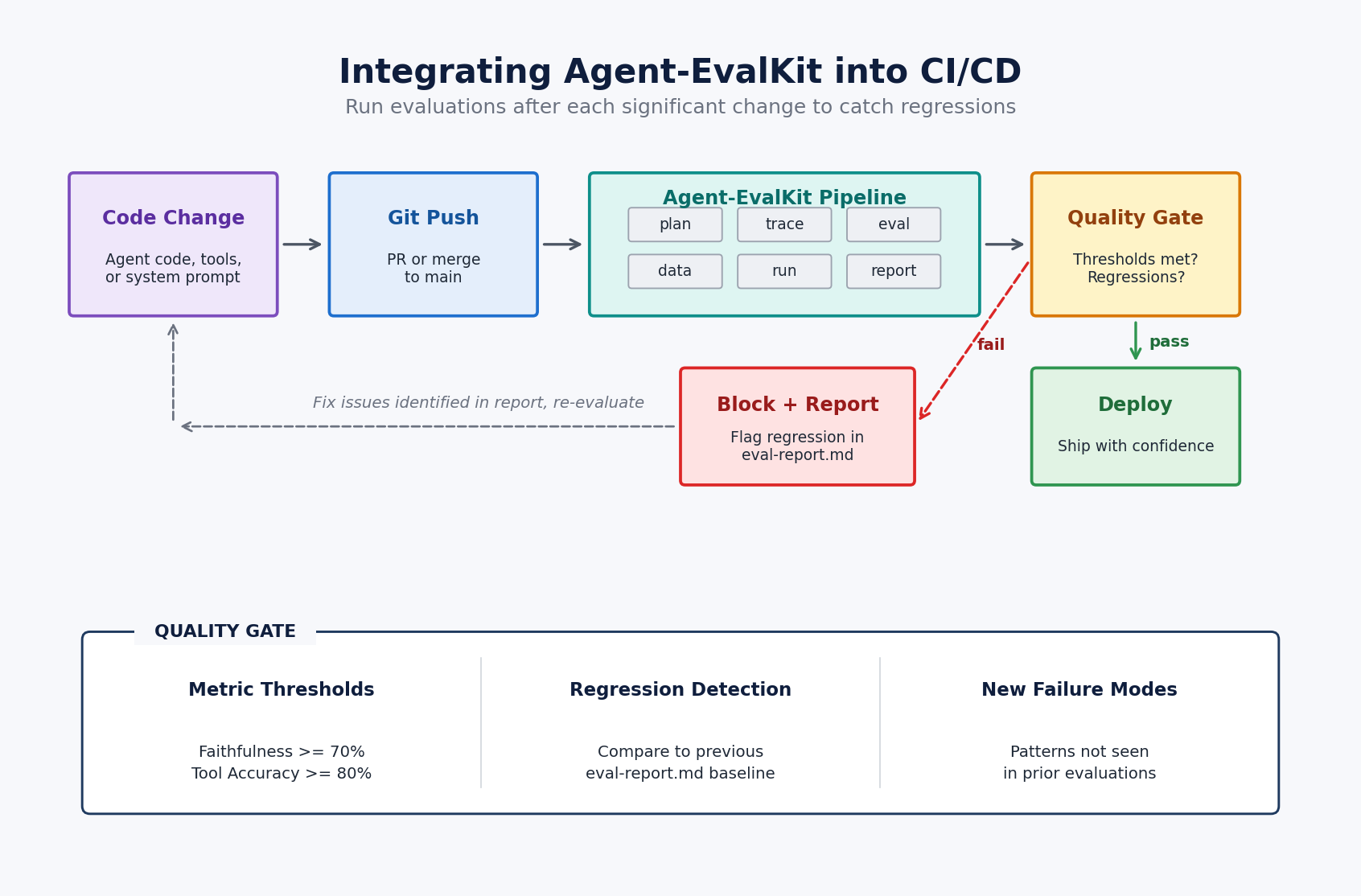
CI/CD 파이프라인에 통합하여 코드 변경 시마다 평가를 자동화하고, 품질 게이트를 통해 회귀를 방지하며 지속적인 성능 개선을 지원한다.
실무 Takeaway
- 에이전트 평가 시 응답 품질뿐만 아니라 도구 호출의 정확성과 사실 충실도를 개별 지표로 측정하여 숨겨진 실패 모드를 식별한다.
- Agent-EvalKit을 사용하여 에이전트의 실행 경로를 추적하고, 환각이 발생하는 특정 코드 지점을 파악하여 즉각적인 수정안을 도출한다.
- CI/CD 파이프라인에 평가 단계를 통합하여 코드 변경이 에이전트의 신뢰성에 미치는 영향을 지속적으로 모니터링한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 12.수집 2026. 06. 12.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.