이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
기업은 매일 방대한 문서를 처리하지만, 기존 OCR은 문맥 이해가 부족해 수동 작업이 필수적이다. Amazon Bedrock Data Automation(BDA)은 문서 분류, 추출, 검증을 자동화하여 다중 모달 데이터를 처리한다. AWS Step Functions가 워크플로를 오케스트레이션하고, AgentCore Runtime 기반 에이전트가 복잡한 분석을 수행한다. 부동산 투자 분석 사례에서 문서 처리 시간을 3~4시간에서 15~20분으로 단축하고 5만 건 이상의 문서를 성공적으로 처리했다.
배경
AWS 계정 및 IAM 권한, Amazon Bedrock 접근 권한, AWS CDK 및 Python 기본 지식
대상 독자
프로덕션 환경에서 대규모 문서 처리 파이프라인을 구축하려는 개발자 및 아키텍트
의미 / 영향
이 아키텍처는 비정형 문서 처리를 단순한 비용 센터에서 전략적 자산으로 전환하며, 특히 시각적 데이터가 많은 금융 및 부동산 분야에서 자동화 효율을 극대화한다.
섹션별 상세
입력 처리 계층은 S3 버킷에 문서가 도착하면 AWS Step Functions를 통해 BDA 작업을 비동기적으로 실행하여 문서 분류와 추출을 자동화한다.
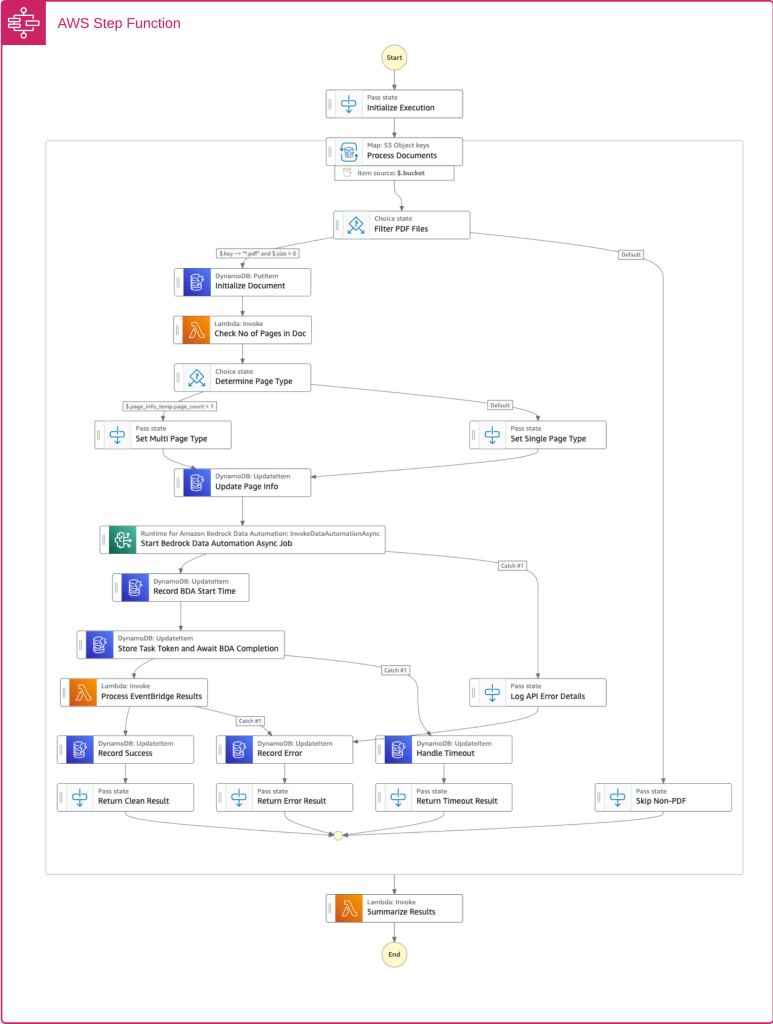
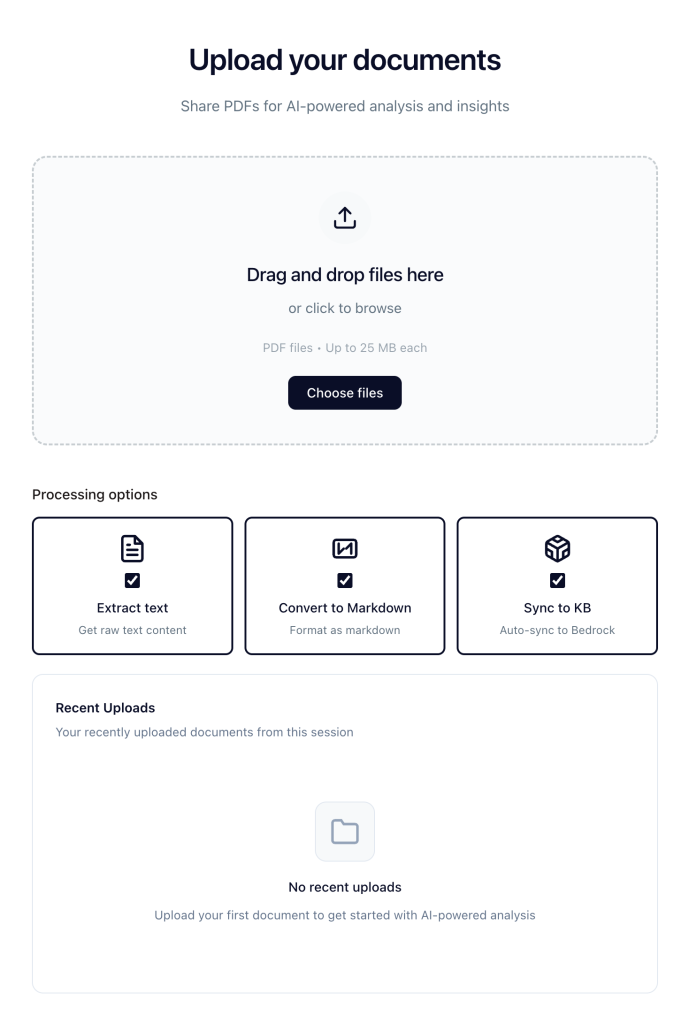
BDA는 표준 출력 또는 사용자 정의 블루프린트를 통해 텍스트, 표, 양식뿐만 아니라 차트, 그래프, 다이어그램 등 시각적 요소까지 분석하여 구조화된 데이터를 생성한다.
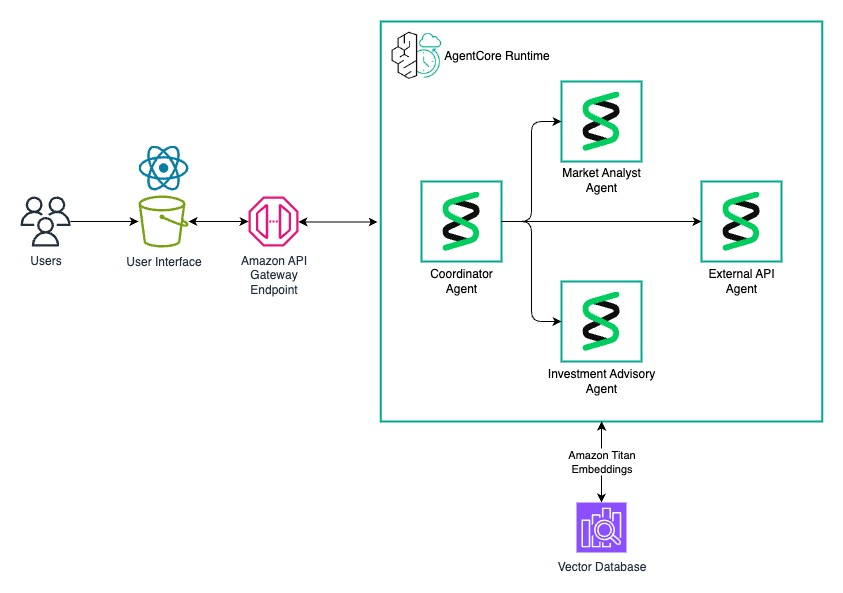
지능형 계층은 Amazon Bedrock Knowledge Bases와 OpenSearch Serverless를 결합하여 추출된 데이터에 대한 시맨틱 검색과 RAG를 지원한다.
에이전트 계층은 AgentCore Runtime 위에서 시장 분석가, 투자 자문, 외부 API 에이전트가 협업하여 복잡한 문서 분석과 교차 검증을 수행한다.
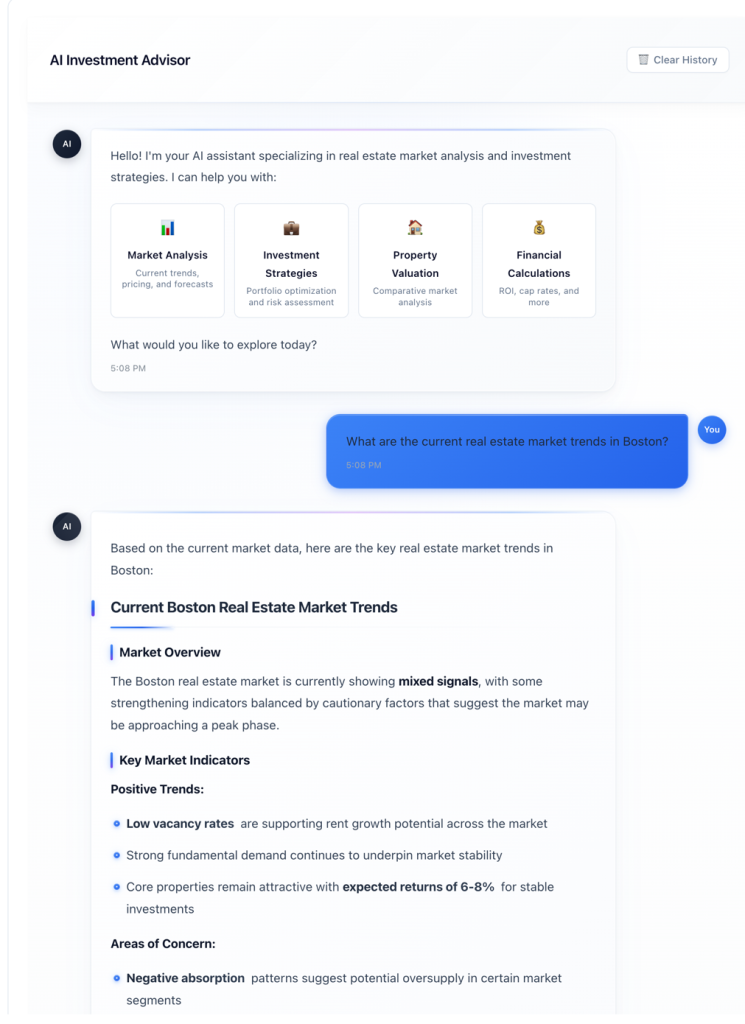
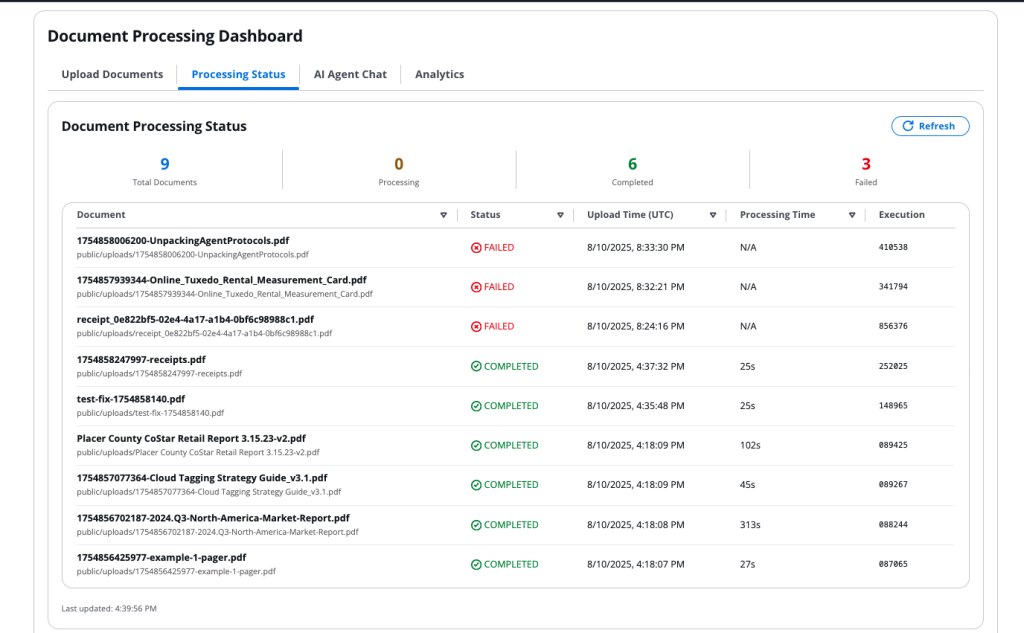
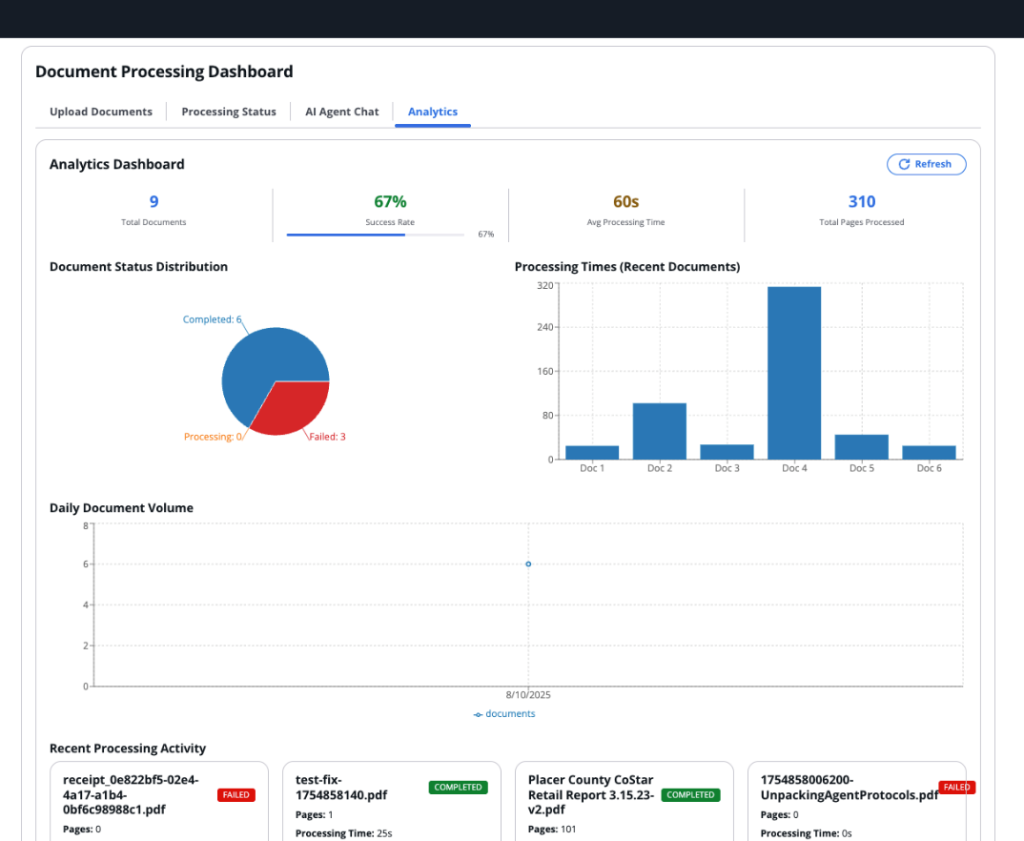
부동산 투자 분석 사례에서 이 파이프라인은 5만 건 이상의 문서를 처리하며 기존 3~4시간 소요되던 작업을 15~20분으로 단축했다.
코드 예제
bash
git clone https://github.com/aws-samples/sample-pdf-to-insights-idp-solution솔루션 배포를 위한 코드 저장소 복제 명령어
bash
./deploy.sh –profile default –environment UAT배포 스크립트 실행 명령어
실무 Takeaway
- Amazon Bedrock Data Automation을 활용하면 문서 분류부터 데이터 추출까지의 과정을 자동화하여 수동 작업 병목을 제거할 수 있다.
- 복잡한 문서 분석이 필요한 경우, 에이전트 기반 오케스트레이션을 도입하여 전문화된 태스크 에이전트 간의 협업을 구현해야 한다.
- 시각적 요소(차트, 그래프)가 포함된 문서는 BDA의 시각적 분석 기능을 통해 텍스트 데이터와 함께 구조화하여 비즈니스 인사이트로 전환할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 12.수집 2026. 06. 13.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.