이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
LLM 개발은 데이터, 아키텍처, 하이퍼파라미터 조정에 따른 반복적인 평가 루프를 포함한다. 기존 평가 도구들은 최종 모델의 벤치마크 측정에 치중되어 있어, 개발 중인 모델의 지속적인 변화를 반영하기 어렵다. olmo-eval은 벤치마크 로직과 실행 정책을 분리하여 모듈성을 높이고, 체크포인트 간의 질문 단위 비교를 통해 성능 변화를 정밀하게 분석한다. 이 도구는 샌드박스 환경과 도구 사용 평가를 지원하며, 개발 속도를 높이기 위한 경량화된 실행 경로를 제공한다.
배경
Python, LLM 개발 및 평가 프로세스에 대한 이해
대상 독자
LLM 프로덕션 개발자 및 연구원
의미 / 영향
이 도구는 LLM 개발 과정에서 반복적인 평가 비용과 시간을 절감하여 모델 개발 속도를 높인다. 특히 체크포인트 간 정밀 비교 기능을 통해 모델 개선의 방향성을 데이터 기반으로 결정할 수 있게 돕는다.
섹션별 상세
LLM 개발 중에는 잦은 벤치마크 실행과 결과 분석이 필수적이나, 기존 도구는 완성된 모델 평가에 최적화되어 있어 개발 과정의 변화를 따라가기 어렵다. olmo-eval은 이러한 개발 루프를 지원하기 위해 설계되었다.
olmo-eval의 핵심 구조는 벤치마크 로직(Task)과 실행 정책(Harness)을 분리하는 것이다. 이를 통해 동일한 벤치마크를 표준 환경이나 도구 사용 환경 등 다양한 조건에서 재사용할 수 있다.
python
@register("internal_freshqa")
class InternalFreshQA(Task):
data_source = DataSource(path="s3://evals/internal/freshqa.jsonl", split="test")
formatter = ChatFormatter()
sampling_params = SamplingParams(temperature=0.0)
metrics = (AccuracyMetric(scorer=ExactMatchScorer),)
@property
def instances(self):
loader = DataLoader()
for idx, doc in enumerate(loader.load(self.config.get_data_source())):
yield Instance(
question=doc["question"],
gold_answer=doc["answer"],
metadata={"id": doc.get("id", f"freshqa_{idx}")},
)olmo-eval에서 새로운 벤치마크 작업을 정의하는 Task 클래스 구현 예시
이 도구는 전체 평균 점수뿐만 아니라 체크포인트 간 질문 단위의 비교를 지원한다. 이를 통해 미세한 성능 변화가 개선인지 단순 노이즈인지 명확하게 판단할 수 있다.
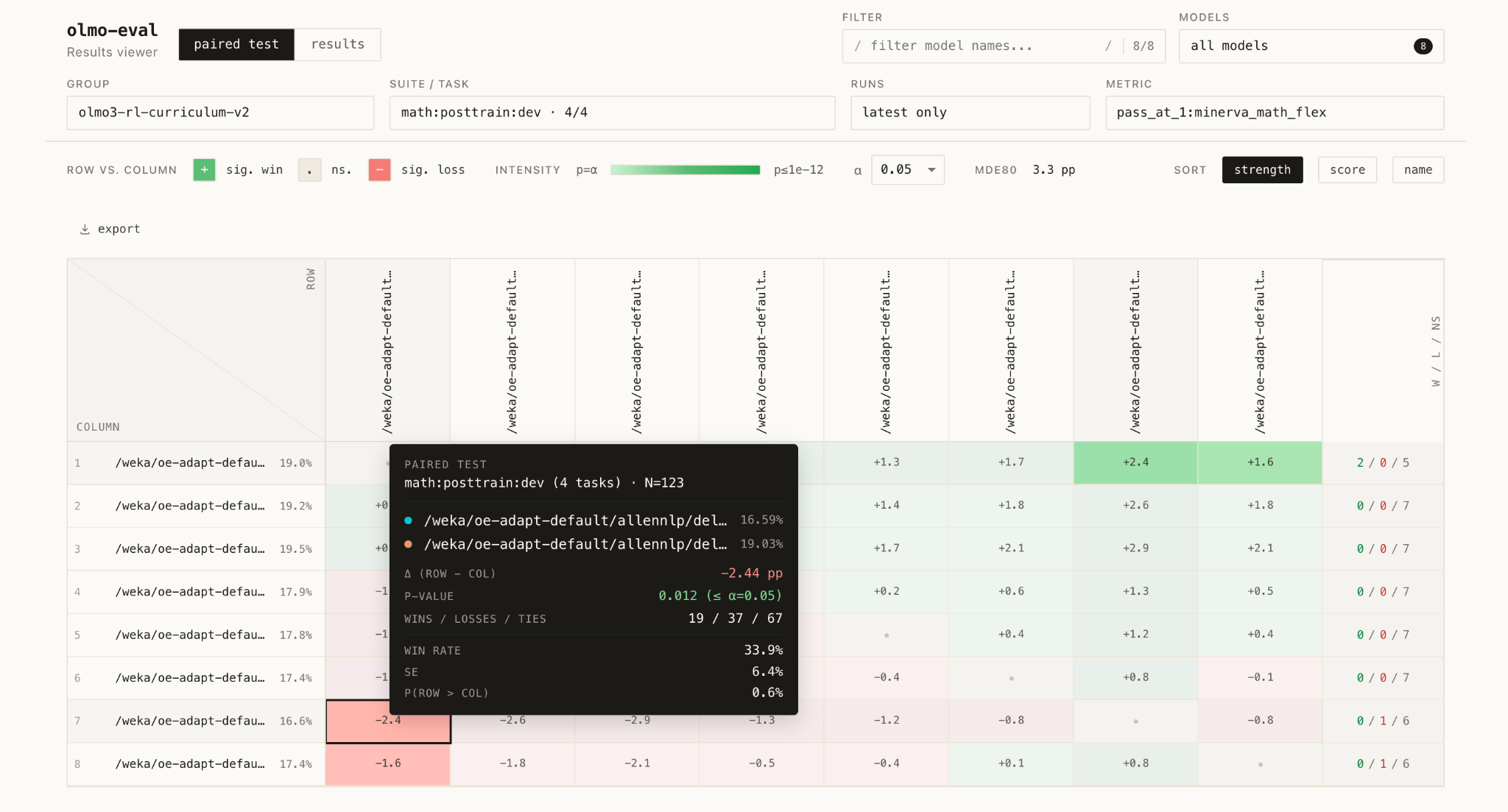
olmo-eval은 경량화된 실행 경로를 기본으로 하되, 코드 실행 등 격리된 환경이 필요한 경우에만 컨테이너를 사용하는 방식으로 효율성을 극대화했다.
실무 Takeaway
- LLM 개발 시 전체 평균 점수 외에 체크포인트 간 질문 단위 비교를 수행하여 성능 개선의 실질적 근거를 확보해야 한다.
- 벤치마크 로직과 실행 정책을 분리하면 동일한 평가셋을 다양한 환경(도구 사용, 표준 추론 등)에서 재사용하여 개발 효율을 높일 수 있다.
언급된 리소스
GitHubolmo-eval GitHub
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 13.수집 2026. 06. 13.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.